爬虫+各种花括号处理 分析数据就要先处理数据
Posted mamang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫+各种花括号处理 分析数据就要先处理数据相关的知识,希望对你有一定的参考价值。
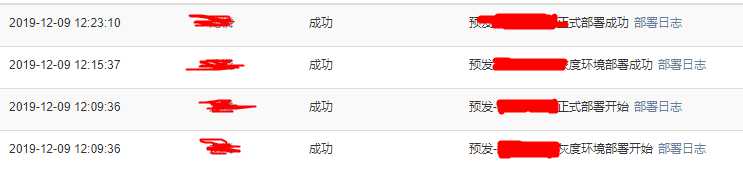
第一步 爬取数据
这样的日志页面需要取下来对时间进行分析,也可以求人家从数据库里面取出来给我,但是数据差不多,还是不求了
话不多说 只会request的我,根据往常一样,反手一个request.get(url)
和F12看到的一点都不一样??

好吧 看一下请求数据
在控制台>network>XHR检查到每次刷新都有一个getlog的请求
拿到Request URL: https://
使用request进行get,发现返回200没问题,但是返回的也是云里雾里,要这要那,说了一堆需要认证的地方
在请求页面取cookies,放入headers,拿到了数据
爬取代码如下:
headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) Chrome/50.0.2661.102‘, ‘cookie‘: ‘emplId=888888; ak_user_timezone=A...‘}
sentence = requests.get(headers=headers, url=posturl)
#sentence = requests.post(posturl, postdata)
print(sentence.status_code)
sentence.encoding = sentence.apparent_encoding # 防止中文乱码
return sentence.text # 直接返回text
拿到数据格式如下:
`{"object":{"dataList":[{"creatorName":"楚","description":"正式环境部署成功<a href="https://abc">部署日志</a>","descriptionValues":"["预发-正式部署开始","https://abc"]","CreateTime":1575521902000,"objectType":"APP_FLOW",,"status":"成功"},{"creatorName":"楚","description":"灰度环境部署成功<a href="https://abc">部署日志</a>","descriptionValues":"["预发-灰度环境","https://abc"]","CreateTime":1575521408000,"objectType":"APP_FLOW","status":"成功"},{...},{}}`
外面的大括号代表一页的量,一页是10条日志也是用大括号隔开,暂且展示2条,目标就是去大括号,去超链接,提取需要的时间等数据进行统计
第二步 数据处理
将爬取的数据存在了本地txt文件,先读取txt
f = open("write.txt", "r") str = f.readlines() print(str)
提取dataList
使用findall对`dataList":[和],"total`之间的内容进行提取,等于拿到了每页的关键性内容
for i in str: log = re.findall(r‘dataList":[(.*?)],"total‘, i)[0]
得到的log如下,数据类型为<class ‘str‘>:
`{"creatorName":"楚","description":"正式环境部署成功<a href="https://abc">部署日志</a>","descriptionValues":"["预发-正式部署开始","https://abc"]","CreateTime":1575521902000,"objectType":"APP_FLOW",,"status":"成功"},{"creatorName":"楚","description":"灰度环境部署成功<a href="https://abc">部署日志</a>","descriptionValues":"["预发-灰度环境","https://abc"]","CreateTime":1575521408000,"objectType":"APP_FLOW","status":"成功"},{...},{}`
对花括号再进行剥除,得到list的列表,列表每个元素为一条日志
type1 = re.findall(r‘{(.*?)}‘, log)
`[‘"actionType":"重新部署"..]`
将拿到的列表中的每一条日志划分为一个列表
lengnum = len(type1) for j in range(lengnum): joblist = type1[j].split(‘,‘)
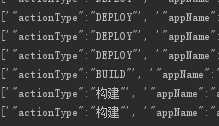
这时候的数据大部分都是key:value形式的,但有一部分是只有字符串的,把这部分筛掉
方法:有“:”我们认为格式正确,将他们放入新的dict1字典中
for k in joblist: if ‘:‘ in k: dict1[k.split(‘:‘)[0]] = k.split(‘:‘)[1]
这时候处理完后,其实超链接也会被截断,因为链接也有“:”,刚好,这时候超链接只剩下`<a href="https`这一节,只要取“<”的左边内容就OK
顺便使用strip(‘"‘)对多余的双引号进行删除,lstrip=leftstrip?
if ‘"status"‘ in dict1.keys(): dict1[‘"description"‘] = dict1[‘"description"‘].split(‘<‘)[0].lstrip(‘"‘) dict1[‘"creatorName"‘] = dict1[‘"creatorName"‘].strip(‘"‘) dict1[‘"status"‘] = dict1[‘"status"‘].strip(‘"‘)
这时候使用字典进行提取,组合
dict2 = [dict1[‘"creatorName"‘], dict1[‘"description"‘], dict1[‘"CreateTime"‘], dict1[‘"time"‘]dict1[‘"status"‘]]
拿到的就是list
[‘翔仔‘, ‘预发-灰度环境部署成功‘, ‘1575521902000‘, ‘2019-12-05 12:58:22‘,‘成功‘]
为了存入文件,将list转换为str
dict3 = ",".join(dict2)
写入txt文件,加换行符逐行写入
file_name = ‘target.txt‘ with open(file_name, ‘a+‘) as file_obj: file_obj.write(dict3 + ‘ ‘)
第三步 数据存入mysql
可以直接存的 我多此一举
#coding=utf-8 import MySQLdb #MySQL的连接 conn = MySQLdb.connect( host=‘localhost‘, port=3306, user=‘root‘, passwd=‘root‘, db=‘test‘, charset=‘utf8‘, ) cur = conn.cursor() f = open("target8.txt", "r", encoding=‘UTF-8‘) while True: line = f.readline() if line: #处理每行 line = line.strip(‘ ‘) line = line.split(",") print(line) cur.execute( "insert into test1(creatorName,description,CreateTime,runtime,status) values(%s,%s,%s,%s,%s)", [line[0], line[1], line[2], line[3], line[4]]) else: break f.close() cur.close() conn.commit() conn.close()
在mysql表里面添加一列,对每行数据添加特征值,方便匹配
添加部署记录标记 UPDATE test1 SET jobtype=‘originalPub‘ WHERE description LIKE ‘%正式部署%‘ UPDATE test1 SET jobtype=‘grayPub‘ WHERE description LIKE ‘%灰度环境部署%‘ 添加代码合并标记 UPDATE test1 SET jobtype=‘codemergefail‘ WHERE description LIKE ‘%代码合并冲突%‘ UPDATE test1 SET jobtype=‘codemergefail‘ WHERE description LIKE ‘%代码合并失败%‘ UPDATE test1 SET jobtype=‘beginChange‘ WHERE description LIKE ‘%将变更%‘ UPDATE test1 SET jobtype=‘codemergesuccess‘ WHERE description LIKE ‘%代码合并成功%‘ 新建一张表,添加第一列id自增序列,筛选出的重要数据存入该表进行运算使用 INSERT INTO test3 SELECT * FROM test1 WHERE jobtype=‘originalPub‘ OR jobtype=‘beginChange‘ OR jobtype=‘grayPub‘ OR jobtype=‘codemergefail‘ OR jobtype=‘codemergesuccess‘