Oracle第二话之调优工具
Posted yaoyangding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle第二话之调优工具相关的知识,希望对你有一定的参考价值。
Oracle第二话之调优工具
目录
1、告警日志
数据库出现任何问题,第一件事就是先看告警日志文件。
1)告警日志内容:
(1)启动时间以及操作模式的启动和关闭命令。
(2)涉及物理结构的操作,使用ALTER DATABASE命令。
(3)表空间操作。
(4)所有日志切换与归档,包括所影响文件的名称。
(5)用于启动实例的非默认初始化参数,含ALTER SYSTEM修改的参数。
(6)告警日志包含了影响数据库结构和实例的各种操作的连续历史记录。
(7)告警日志不包含SQL语句(DML,DDL)
2)告警日志包含常见的告警与错误:
(1)检查点不完全:说明日志文件过小而引起日志切换频繁。
(2)无法打开文件:在数据库启动过程中产生。
(3)块讹误:某个数据文件损坏引起。与DBA_EXTENTS视图一起查看。
(4)归档存在问题:归档目的地满或不可用。
(5)死锁。
3)查看告警日志
(1)SQL> show parameter dump --查看告警日志存放地址
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
background_core_dump string partial
background_dump_dest string /u01/app/oracle/oradata/PROD/b
dump
core_dump_dest string /u01/app/oracle/oradata/PROD/c
dump
max_dump_file_size string UNLIMITED
shadow_core_dump string partial
user_dump_dest string /u01/app/oracle/oradata/PROD/u
dump
(2)[oracle@gc1 ~]$ cd /u01/app/oracle/oradata/PROD/bdump
(3)[oracle@gc1 bdump]$ ls
alert_PROD.log prod_arc1_2547.trc prod_arc2_2576.trc prod_lgwr_2533.trc prod_rvwr_2542.trc
(4)[oracle@gc1 bdump]$ tail -f alert_PROD.log --查看告警日志
4)定期管理:时间一长,告警日志就会增多,告警日志可以删除,但操作系统日志不可删(系统会起不来的)。
删除告警日志:
$ cat /dev/null > /u01/app/oracle/oradata/PROD/bdump/alert_PROD.log
2、用户进程trace文件
用户进程trace文件一般由server进程产生。
1)SQL> show parameter trace; --查看
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_trace integer 0
sql_trace boolean FALSE --可以跟踪session中的操作,可以显示解析了几次,返回了几行数据等
trace_enabled boolean TRUE
tracefile_identifier string
用于统计用户执行的sql语句,可以通过这些统计信息,判断sql语句的执行过程和对资源调。默认,oracle对用户执行的sql语句不做跟踪。
2)实验一 --跟踪当前session
(1)SQL> grant alter session to scott; --授予更改会话权限个scott用户
(2)SQL> conn scott/tiger --用scott用户登录
(3)SQL> alter session set sql_trace=true; --在scott用户会话中打开跟踪,该为true就可以跟踪了
(4)SQL> select empno,ename,job from emp where empno=7788;
EMPNO ENAME JOB
---------- ---------- ---------
7788 SCOTT ANALYST
(4)SQL> select empno,ename,job from emp where empno=7900;
EMPNO ENAME JOB
---------- ---------- ---------
7900 JAMES CLERK
(4)SQL> alter session set sql_trace=false; --关闭跟踪
(5)sys用户查询追踪信息
SQL> col machine for a10
SQL> col username for a10
SQL> select p.spid,s.machine,s.username,s.sid,s.serial#,s.status from v$session s,v$process p where s.sid in (select sid from v$session where username is not null) and s.paddr=p.addr;
SPID MACHINE USERNAME SID SERIAL# STATUS
------------ ---------- ---------- ---------- ---------- --------
2585 gc1 SYS 289 3 ACTIVE
2618 gc1 SCOTT 275 8 INACTIVE
另一种查询方法:
SQL> select username,sid,serial# from v$session where username is not null;
USERNAME SID SERIAL#
---------- ---------- ----------
SCOTT 275 8
SYS 289 3
(6)查看文件内容
$ cd /u01/app/oracle/oradata/PROD/udump --到udump下
$ ls -lht
-rw-r----- 1 oracle oinstall 82K May 3 12:50 prod_ora_2618.trc
$ more prod_ora_2618.trc --看不懂,需要借助工具
$ tkprof --查看tkprof使用方法,将文件变为可读形式
$ tkprof prod_ora_2618.trc /home/oracle/scott.txt sys=no sort=fchela --将源文件变换后保存在/home/oracle/scott.txt 中,sys=no表示把sys用户的操作排除在外,sort=fchela 表示排序。
$ more /home/oracle/scott.txt --查看信息
select empno,ename,job
from
emp where empno=7788
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.01 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 2 2 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.01 2 2 0 1 --返回行数4行
Misses in library cache during parse: 1 --硬解析一次
Optimizer mode: ALL_ROWS
Parsing user id: 25
3)实验二 --跟踪其他session
(1)SQL> select username,sid,serial# from v$session where username is not null;
USERNAME SID SERIAL#
---------- ---------- ----------
SCOTT 275 8
SYS 289 3
(2)SQL> exec dbms_system.set_sql_trace_in_session(275,8,sql_trace=>true); --在sys用户下开起跟踪scott用户的会话
(3)在scott用户下,使用绑定变量查询
SQL> variable enum number;
SQL> exec :enum:=7788; --引用变量进行赋值
SQL> select empno,deptno,job,sal,deptno from emp where empno=:enum;
EMPNO DEPTNO JOB SAL DEPTNO
---------- ---------- --------- ---------- ----------
7788 20 ANALYST 3000 20
SQL> exec :enum:=7900; --在赋值
SQL> select empno,deptno,job,sal,deptno from emp where empno=:enum;
EMPNO DEPTNO JOB SAL DEPTNO
---------- ---------- --------- ---------- ----------
7900 30 CLERK 950 30
(4)SQL> exec dbms_system.set_sql_trace_in_session(275,8,sql_trace=>false); --关闭追踪
(5)sys用户查询追踪信息
SQL> col machine for a10
SQL> col username for a10
SQL> select p.spid,s.machine,s.username,s.sid,s.serial#,s.status from v$session s,v$process p where s.sid in (select sid from v$session where username is not null) and s.paddr=p.addr;
SPID MACHINE USERNAME SID SERIAL# STATUS
------------ ---------- ---------- ---------- ---------- --------
2585 gc1 SYS 289 3 ACTIVE
2618 gc1 SCOTT 275 8 INACTIVE
另一种查询方法:
SQL> select username,sid,serial# from v$session where username is not null;
USERNAME SID SERIAL#
---------- ---------- ----------
SCOTT 275 8
(6)查看文件内容
$ cd /u01/app/oracle/oradata/PROD/udump --到udump下
$ ls -lht
-rw-r----- 1 oracle oinstall 82K May 3 12:50 prod_ora_2618.trc
$ more prod_ora_2618.trc --看不懂,需要借助工具
$ tkprof --查看tkprof使用方法,将文件变为可读形式
$ tkprof prod_ora_2618.trc /home/oracle/scott.txt sys=no sort=fchela --将源文件变换后保存在/home/oracle/scott.txt 中,sys=no表示把sys用户的操作排除在外,sort=fchela 表示排序。
$ more /home/oracle/scott.txt --查看信息
select empno,deptno,job,sal,deptno
from
emp where empno=:enum
BEGIN :enum:=7788; END;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.00 0.00 0 0 0 1 --返回两行数据
Misses in library cache during parse: 1 --解析1次
Misses in library cache during execute: 1
Optimizer mode: ALL_ROWS
Parsing user id: 25
4)搜集统计信息
(1)对表进行分析获取最新数据
SQL> analyze table scott.emp compute statistics; --对小表用compute
SQL> analyze table scott.emp estimate statistics; --对大表用estimate
(2)
a)
![]()
b)

c)

d)粘贴如下信息
DBMS_STATS.GATHER_TABLE_STATS (
(3)SQL> exec DBMS_STATS.GATHER_TABLE_STATS (‘SCOTT‘,‘EMP‘); --用包收集SCOTT用户的EMP表的统计信息
(4)收集索引统计信息
SQL> analyze index scott.pk_emp validate structure; --收集索引统计信息
或
SQL> exec DBMS_STATS.GATHER_INDEX_STATS(‘SCOTT‘,‘PK_EMP‘); --用包收集SCOTT用户EMP表上的索引的统计信息
(5)收集用户统计信息
SQL> exec DBMS_STATS.GATHER_SCHEMA_STATS(‘SCOTT‘);
(6)收集数据库统计信息
SQL> exec DBMS_STATS.GATHER_DATADASE_STATS( --格式不清除,看官方文档
3、动态性能视图
1)静态视图: --体系第一章表空间段区块的查询
在数据库open状态下访问,用于了解数据库的物理结构信息。
大部分以dba,all,user打头,并多用复数形式。例如表和索引的统计信息。
User_:存储当前用户所拥有的对象的相关信息
All_:存储当前用户能够访问的对象(包括用户所拥有的对象和别的用户授权访问的对象)的信息。
Dba_:存储所有用户对象的信息(默认只能有sys/system用户访问)
2)动态视图:
大部分在mount下就可以访问,反映数据库实时的状态。
大部分以v$开头,多用单数,从控制文件和内存中读出。
从v$fixed_table这个视图查到所有的动态视图的名称
用于调优和数据库监控
SQL> select name from v$tablespace; --查询表空间
NAME
------------------------------
SYSTEM
UNDOTBS
SYSAUX
TEMPTS
USERS
SQL> select file#,name from v$datafile; --查询数据文件
FILE# NAME
---------- --------------------------------------------------
1 /u01/app/oracle/oradata/PROD/disk3/system01.dbf
2 /u01/app/oracle/oradata/PROD/disk4/undotbs01.dbf
3 /u01/app/oracle/oradata/PROD/disk4/sysaux01.dbf
4 /u01/app/oracle/oradata/PROD/disk3/users01.dbf
SQL> select file#,name from v$tempfile; --查询临时文件
FILE# NAME
---------- --------------------------------------------------
1 /u01/app/oracle/oradata/PROD/disk5/temp01.dbf
3)系统统计信息
统计信息大部分都记录在v$sysstat中。
(1)SQL> desc v$sysstat;
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
STATISTIC# NUMBER
NAME VARCHAR2(64)
CLASS NUMBER
VALUE NUMBER
STAT_ID NUMBER
(2)SQL> select count(*) from v$sysstat;
COUNT(*)
----------
363
(4)SQL> select name,value from v$sysstat;
(5)查看SGA里的统计信息
SQL> select * from v$sgastat where name like ‘log%‘;
POOL NAME BYTES
------------ -------------------------------------------------- ----------
log_buffer 2973696
shared pool log_simultaneous_copies 248
shared pool log file size history arr 168
shared pool log_checkpoint_timeout 12360
(6)查看各个池的大小
SQL> select name,bytes/1024/1024 m from v$sgainfo;
NAME M
-------------------------------------------------- ----------
Fixed SGA Size 1.16325378
Redo Buffers 2.8359375
Buffer Cache Size 276
Shared Pool Size 112
Large Pool Size 4
Java Pool Size 4
Streams Pool Size 0
Granule Size 4
Maximum SGA Size 400
Startup overhead in Shared Pool 40
Free SGA Memory Available 0
4)等待事件统计信息
(1)查询等待事件
SQL> desc v$event_name;
SQL> select name from v$event_name where name like ‘log%‘;
SQL> select name from v$event_name where name like ‘buffer busy wait%‘;
NAME
--------------------------------------------------
buffer busy waits
(2)查询等待事件的值
SQL> desc v$system_event;
SQL> col event for a30
SQL> select EVENT,TOTAL_WAITS,TOTAL_TIMEOUTS,TIME_WAITED,AVERAGE_WAIT from v$system_event where event like ‘log%‘;
EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED AVERAGE_WAIT
------------------------------ ----------- -------------- ----------- ------------
log file sequential read 8 0 0 .05
log file single write 8 0 0 .04
log file parallel write 2570 0 453 .18
log file sync 19 2 256 13.48
5)会话统计信息
(1)SQL> desc v$session --查询当前登录用户信息。
(2)SQL> select username,sid,serial# from v$session where username is not null;
USERNAME SID SERIAL#
---------- ---------- ----------
SCOTT 275 8
SYS 289 3
(3)查询更详细的信息
col username for a10
col name for a30
select se.sid,se.serial#,se.username,st.class,st.name,ses.value;
from v$session se,v$statname st,v$sesstat ses
where se.sid=ses.sid
and ses.statistic#=st.statistic#
and se.username is not null
and ses.value<>0
and se.username<>‘SYS‘;
或
col username for a10
col name for a30
select se.sid,se.serial#,se.username,st.class,st.name,ses.value
from v$session se,v$statname st,v$sesstat ses
where se.sid=ses.sid
and ses.statistic#=st.statistic#
and se.username is not null
and ses.value<>0
and se.username=‘&username‘; --可以动态查看某个用户的会话统计信息
(4)class
1 代表实例活动
2 代表redo buffer活动
4 代表锁
8 代表数据缓冲活动
16 代表并行活动
64 代表表访问
128 代表调试信息
在本session中查询,pga超过300k的用户信息。
select username,name,trunc(value/1024) k
from v$statname n,v$session s,v$sesstat t
where s.sid=t.sid
and n.statistic#=t.statistic#
and s.type=‘USER‘
and s.username is not null
and n.name=‘session pga memory‘
and t.value>300000;
USERNAME NAME K
---------- -------------------- ----------
SYS session pga memory 1403
4、statspack 安装产生报告
报告就是各个快照统计值比较的结果
statspack的由来——statistics package
Inspect 检查
Expect 期望
Respect 尊重
Prospect 展望
运行statspack 期间必须session 上设置TIMED_STATISTICS=TRUE,否则统计的数据将失真。
Job_queue_processes=15,该参数不大于1就生成不了报告。
两个重要参数:
(1)SQL> show parameter job;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
job_queue_processes integer 15 --该参数不大于1就生成不了报告
(2)SQL> show parameter timed;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
timed_os_statistics integer 0
timed_statistics boolean TRUE --设置TIMED_STATISTICS=TRUE,否则统计的数据将失真
1)创建表空间
(1)SQL> select tablespace_name,contents,status from dba_tablespaces;
TABLESPACE_NAME CONTENTS STATUS
------------------------------ --------- ---------
SYSTEM PERMANENT ONLINE
UNDOTBS UNDO ONLINE
SYSAUX PERMANENT ONLINE
TEMPTS TEMPORARY ONLINE
USERS PERMANENT ONLINE
(2)SQL> select file#,name from v$datafile;
FILE# NAME
---------- --------------------------------------------------
1 /u01/app/oracle/oradata/PROD/disk3/system01.dbf
2 /u01/app/oracle/oradata/PROD/disk4/undotbs01.dbf
3 /u01/app/oracle/oradata/PROD/disk4/sysaux01.dbf
4 /u01/app/oracle/oradata/PROD/disk3/users01.dbf
(3)SQL> create tablespace tools datafile ‘/u01/app/oracle/oradata/PROD/disk3/tool01.dbf‘ size 10m; --statspack至少需要200M,OCM考试会故意让你设小,需要将它改大。
(4)SQL> select file#,name from v$datafile;
FILE# NAME
---------- --------------------------------------------------
1 /u01/app/oracle/oradata/PROD/disk3/system01.dbf
2 /u01/app/oracle/oradata/PROD/disk4/undotbs01.dbf
3 /u01/app/oracle/oradata/PROD/disk4/sysaux01.dbf
4 /u01/app/oracle/oradata/PROD/disk3/users01.dbf
5 /u01/app/oracle/oradata/PROD/disk3/tool01.dbf
(5)SQL> alter database datafile 5 resize 200m; --将表空间改为200M
SQL> alter database datafile 5 autoextend on next 10m maxsize unlimited; --设为自动增长,无最大限制
(6)查看文集大小
SQL> select file_id,file_name,tablespace_name,bytes/1024/1024 m from dba_data_files;
FILE_ID FILE_NAME TABLESPACE M
---------- -------------------------------------------------- ---------- ----------
1 /u01/app/oracle/oradata/PROD/disk3/system01.dbf SYSTEM 325
2 /u01/app/oracle/oradata/PROD/disk4/undotbs01.dbf UNDOTBS 200
3 /u01/app/oracle/oradata/PROD/disk4/sysaux01.dbf SYSAUX 325
4 /u01/app/oracle/oradata/PROD/disk3/users01.dbf USERS 50
5 /u01/app/oracle/oradata/PROD/disk3/tool01.dbf TOOLS 200
2)跑脚本 --注意是用sys用户跑
(1)SQL> @?/rdbms/admin/spcreate
Enter value for perfstat_password: perfstat
Enter value for default_tablespace:TOOLS
Enter value for temporary_tablespace: TEMPTS
(2)查看信息
$ cd $ORACLE_HOME/rdbms/admin
$ ls |grep spcpkg
spcpkg.sql
$ more spcpkg.sql
3)调整快照级别为7
SQL> conn perfstat/perfstat
SQL> desc statspack;
SQL> exec statspack.MODIFY_STATSPACK_PARAMETER(I_SNAP_LEVEL=>7);
4)创建一个job,每隔五分钟执行
[oracle@gc1 admin]$ pwd
/u01/app/oracle/product/10.2.0/db_1/rdbms/admin
[oracle@gc1 admin]$ ls |grep spauto
spauto.sql
$ vi spauto.sql --修改参数,原本1小时生成1个快照,该为5分钟
spool spauto.lis
-- Schedule a snapshot to be run on this instance every hour, on the hour
variable jobno number;
variable instno number;
begin
select instance_number into :instno from v$instance;
dbms_job.submit(:jobno, ‘statspack.snap;‘, trunc(sysdate+1/288,‘MI‘), ‘trunc(SYSDATE+1/288,‘‘MI‘‘)‘, TRUE, :instno);
commit;
end;
/
SQL> select 12*24 from dual; --1小时有12个5分钟,1天分为24个小时
12*24
----------
288
5)执行@?/rdbms/admin/spauto --在perfstat用户中,之前已经连接
(1)SQL> @?/rdbms/admin/spauto --跑脚本
如下是脚本中的内容,不用执行:
(SQL> select job, next_date, next_sec
2 from user_jobs
3 where job = :jobno;
JOB NEXT_DATE NEXT_SEC
---------- --------- ----------------
1 04-MAY-14 09:51:00
)
(2)SQL> select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss‘) from dual; --查看时间
TO_CHAR(SYSDATE,‘YY
-------------------
2014-05-04 09:49:51
(3)SQL> select snap_id,snap_level from stats$snapshot; --查看快照信息
SNAP_ID SNAP_LEVEL
---------- ----------
1 7
(4)手动生成快照
SQL> exec statspack.snap();
SQL> select snap_id,snap_level from stats$snapshot;
SNAP_ID SNAP_LEVEL
---------- ----------
1 7
3 7
6)跑脚本 --用SYS用户跑
(1)SQL> show user
USER is "SYS"
(2)SQL> create table test(id number(8),name varchar2(30));
(3)插入100万行数据 --烂代码
declare
sql_text varchar2(100);
begin
for i in 1..1000000 loop
sql_text:=‘insert into test values(‘||i||‘,‘‘‘||‘zhangsan‘||i||‘‘‘)‘;
execute immediate sql_text;
if mod(i,1000)=0 then
commit;
end if;
end loop;
commit;
end;
/
7)查看statspack报告 --如下5、中的3),发现这段代码问题很多
8)清除快照
5、生成AWR ADDM ASH 报告
AWR是oracle的自动快照工具,一般每小时产生一个快照。
AWR(Automatic workload repository)工作负载自动存储报告。
AWR是ORACLE 10g后推出的一个新技术构架,其实就是9i的statspack的演变和增强版本。通过AWR,ORACLE可自动采集,保存和管理系统负载和性能统计数据,用于问题诊断分析和系统自动调整等。AWR面向的服务对象包括内部的ADDM和其他自动优化和诊断工具,以及外部的EM、SQL*PLUS等工具。AWR原理意图如下所示。
即AWR数据主要由两部分组成。
(1)保存在内存中的系统负载和性能统计数据,主要通过v$视图进行访问。
(2)ORACLE通过10g新的MMPN进程定期自动以快照(snapshot)形式将保存在内存中的AWR数据,转存到磁盘中,用于性能数据的长期保存和分析,这些数据主要通过DBA_*视图进行访问。
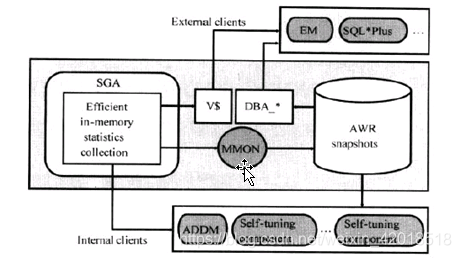
AWR(Automatic workload repository)工作负载自动存储报告。
ADDM(automatic database dignostics monitor)数据库自动诊断监控报告
ASH(active session history)历史报告
可以通过v$ACTIVE_SESSION_HISTORY视图查看内存中ASH的信息
AWR是oracle 10g中的一个新特性,类似于10g以前的statspack。不过在使用上要比statspack简单,提供的新能指标要比statspack多很多,能更好的帮助DBA来发现数据库的性能瓶颈。
AWR是oracle安装好后自动启动的,不需要特别的设置。收集的统计信息存储在SYSAUX表空间SYS模式下,以WRM$_*和WRH$_*的格式命名,默认会保留最近7天收集的统计信息。每个小时将收集到的信息写到数据库中,这一系列操作是由一个叫MMON的进程来完成的。
AWR存储的数据分类:
WRM$表存储AWR的元数据(awrinfo.sql脚本)
WRH$表存储采样快照的历史数据(awrrpt.sql脚本)
WRI$表存储同数据库建议功能相关的数据(ADDM相关数据)
awr报表实际上是statpck报表的延伸,当然10gR2中还是报留了statpack,并且statpack也增加了对stream_pool的监控,awr与statpack的区别就是awr的快照的收集与维护更加自动化,默认的保留七天的快照,并且可以通过dbms_workload_repository表修改快照的收集频率与快照的保留时间,dba要干预的已经很少了,比statpack维护更简单(sp是手动的,awr是自动的)。
awr与ash的最主要的区别在于:awr是平面的,全面的,ash是立体的,更侧重于session的event跟踪,由于业务量大的数据库的event wait是瞬息万变,awr很可能会监控不到,为了弥补这个不足,ash才可以对session的event进行跟踪。
ash与addm的区别在于:addm更侧重于基于对当数据库当前状态的分析,对存在的问题提供指导性的意见,可以说ash,addm是awr的补充,awr全面的收集数据库的状态,但ash/addm是侧重要对收集的数据进行分析,并提供一些有益的建议。
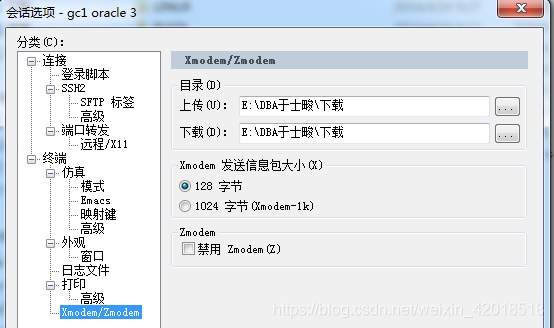
1)准备工作 --设置导出报告存放位置
如图所示:设置默认上传和下载地址,下面进行的sz操作会默认导出文件到如下目录中。
1)手工生成报告步骤
命令:手工抓取快照方式,快照级别TYPICAL ALL(采集指标更完整)
SQL> exec dbms_workload_repository.create_snapshot(‘TYPICAL‘); --手工生成快照
SQL> exec dbms_workload_repository.modify_snapshot_settings(retention => 14400,interval =>30,topnsql => 30); --保留10天10*24*60=14400分钟,30分钟一个快照,一个快照中最多保存30个SQL
2)生成AWR ADDM ASH报告:
(1)生成statspack报告
a)SQL> @?/rdbms/admin/spreport
Instance DB Name Snap Id Snap Started Level Comment
------------ ------------ --------- ----------------- ----- --------------------
PROD PROD 1 04 May 2014 09:51 7
3 04 May 2014 09:54 7
11 04 May 2014 10:51 7
Enter value for begin_snap: 3 --从3开始
Enter value for end_snap: 11 --到11结束
Enter value for report_name: /home/oracle/statspack.1st --保存地址
b)[oracle@gc1 ~]$ ls
Desktop h PROD spauto.lis spctab.lis statspack.1st
control01.bak flash logmnr prod_bak spcpkg.lis spcusr.lis utl
c)将文件从虚拟机中取到windows下载中
$ sz statspack.1st --导出文件
d)打开“我的电脑”收藏夹里的“下载”中查看
(2)生成AWR报告
a)SQL> show user
USER is "PERFSTAT"
b)SQL> select job from dba_jobs;
JOB
----------
1
c)SQL> exec dbms_job.remove(1); --如果这句话失败,执行SQL> exec dbms_ijob.remove(1);
d)SQL> conn /as sysdba
e)SQL> @?/rdbms/admin/awrrpt
Enter value for report_type: --回车就可以,默认html格式
Enter value for num_days: 2 --查看2天内的报告
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
PROD PROD 29 04 May 2014 09:47 1
30 04 May 2014 11:00 1
31 04 May 2014 11:29 1
32 04 May 2014 11:34 1
33 04 May 2014 11:35 1
Enter value for begin_snap: 32
Enter value for end_snap: 33
Enter value for report_name: /home/oracle/myawr.html --存放地址
f)$ ls --查看
control01.bak flash logmnr PROD spauto.lis spctab.lis statspack.1st
Desktop h myawr.html prod_bak spcpkg.lis spcusr.lis utl
g)$ sz myawr.html
(3)生成ADDM报告 --默认类型TXT
a)SQL> @?/rdbms/admin/addmrpt
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
PROD PROD 29 04 May 2014 09:47 1
30 04 May 2014 11:00 1
31 04 May 2014 11:29 1
32 04 May 2014 11:34 1
33 04 May 2014 11:35 1
Enter value for begin_snap: 32 --开始
Enter value for end_snap: 33 --结束
Enter value for report_name: /home/oracle/myaddm.txt --存放地址
b)$ ls --查看
control01.bak flash logmnr myawr.html prod_bak spcpkg.lis spcusr.lis utl
Desktop h myaddm.txt PROD spauto.lis spctab.lis statspack.1st
e)$ sz myaddm.txt
(4)生成ASH报告
a)SQL> select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss‘) from dual; --查看当前时间
TO_CHAR(SYSDATE,‘YY
-------------------
2014-05-04 11:51:47
b)SQL> @?/rdbms/admin/ashrpt
Enter value for report_type: --直接回车,默认类型html
Enter value for begin_time: -30 --看30分钟前的信息
Enter value for duration: 30 --到现在的
Enter value for report_name: /home/oracle/myash.html --存储地址
c)$ ls
control01.bak flash logmnr myash.html PROD spauto.lis spctab.lis statspack.1st
Desktop h myaddm.txt myawr.html prod_bak spcpkg.lis spcusr.lis utl
d)$ sz myash.html
3)查看statspack报告 --文档补充中详细解读statspack报告,发现之前的代码问题很大。
查看统计报表,首先查看十项内容:
1)首要的5个等待事件(TOP 5 WAIT EVENTS)
2)负载简档(LOAD PROFILE)
3)实例效率点击率(INSTANCE EFFICIENCY HIT RATios)
4)等待事件(WAIT EVENTS)
5)闩锁等待(LATCH WAITS) latch activity
6)首要的SQL(TOP SQL) sql ordered by cpu
7)实例活动(INSTANCE ACTIVITY) instance activity
8)文件I/O(FILE I/O) ordered by ios
9)内存分配(MEMORY ALLOCATION) sga memory summary library cache activity
10)缓冲区等待(BUFFER WAITS) buffer pool advisory
cd /home/oracle
more statspack.1st
11)PGA统计信息(PGA STATS)pga aggr target stats pga memory advisory
4)查看AWR报告 --直接用浏览打开查看
6、explan --用来看执行计划
explan多用于开发阶段,只生成执行计划。
SQL> @?/rdbms/admin/utlxplan
也可以SQL> @?/rdbms/admin/utlxpls.sql
utlxplan脚本如果装过autotrace的都跑过了。
1)执行一句话
SQL> explain plan set statement_id=‘p_emp_dept‘ for select e.empno,ename,e.sal,d.deptno from scott.emp e,scott.dept d where e.deptno=d.deptno; --id值是自己设置的名字
2)查看执行计划
SQL> col operation for a18
SQL> col options for a15
SQL> col object_name for a10
SQL> col object_type for a15
SQL> select a.operation,options,object_name,cost,object_type,id,parent_id from plan_table a where statement_id=‘p_emp_dept‘ order by id;
OPERATION OPTIONS OBJECT_NAM COST OBJECT_TYPE ID PARENT_ID
------------------ --------------- ---------- ---------- --------------- ---------- ----------
SELECT STATEMENT 2 0
NESTED LOOPS 2 1 0
TABLE ACCESS FULL EMP 2 TABLE 2 1
INDEX UNIQUE SCAN PK_DEPT 0 INDEX (UNIQUE) 3 1
另一种查看方法: --查看执行计划
SQL> select * from table(dbms_xplan.display);
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 280 | 2 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 14 | 280 | 2 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP | 14 | 238 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN| PK_DEPT | 1 | 3 | 0 (0)| 00:00:01 |
------------------------------------------------------------------------------
--但是没有统计信息,看不到读磁盘的次数。因为只产生执行计划,没有真正执行语句。
3)另一种常用的写法 --查看执行计划
SQL> set pagesize 0 linesize 200 --不分页,不换行
SQL> set timing on --查看执行所消耗的时间
SQL> alter session set statistics_level=all; --把统计级别调高
SQL> select e.empno,e.ename,e.sal,d.deptno,d.dname from scott.emp e,scott.dept d where e.deptno=d.deptno; --查数据
SQL> select * from table(dbms_xplan.display_cursor(null,null,‘allstats last‘)); --查看执行计划,没成功
4)utlbstat.sql和utlestat.sql --很少使用,也是用于查看执行计划
我们可以定义一个开始时间和结束时间,来分析一天当中的繁忙时段,这两个脚本用的较少,收集的统计信息不完整。b代表begin,e代表end。用的较多的是statspack和awr(自动快照工具)。
报告用来比较的,所以要加上一个时间段的前提才有意义。
要对比繁忙阶段和一般时段(baseline)。单个快照是看不出问题的。
5)v$sql或v$sql_plan --查看执行计划
用于根据sql_id查看相应的执行计划:
(1)SQL> select e.empno,e.ename,e.sal,d.deptno,d.dname from scott.emp e,scott.dept d where e.deptno=d.deptno;
(2)SQL> select sql_id,sql_text from v$sql where sql_text like ‘select e.empno,e.ename,e.sal,d.deptno,d.dname from scott.emp e,scott.dept d where e.deptno=d.deptno%‘;
SQL_ID SQL_TEXT
------------- ---------------------------------------------------
2hjnq24dd2khj select e.empno,e.ename,e.sal,d.deptno,d.dname from
scott.emp e,scott.dept d where e.deptno=d.deptno
(3)SQL> select plan_table_output from table(dbms_xplan.display_cursor(‘2hjnq24dd2khj‘));
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| 1 | NESTED LOOPS | | 14 | 420 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | EMP | 14 | 238 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| |
----------------------------------------------------------------------------------------
以上是关于Oracle第二话之调优工具的主要内容,如果未能解决你的问题,请参考以下文章