7.5 高级数据源
Posted nxf-rabbit75
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.5 高级数据源相关的知识,希望对你有一定的参考价值。
一、Kafka简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息。Kafka可以同时满足在线实时处理和批量离线处理。
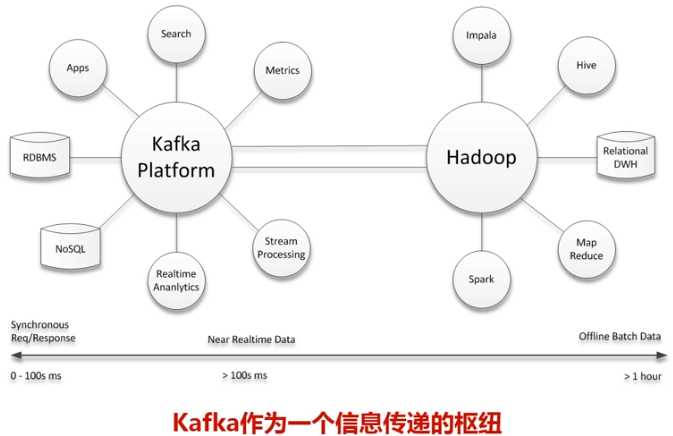
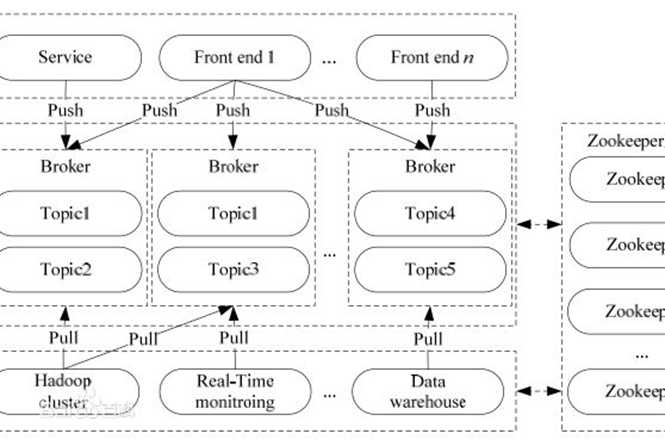
在公司的大数据生态系统中,可以把Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据库、NoSQL数据库、流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。
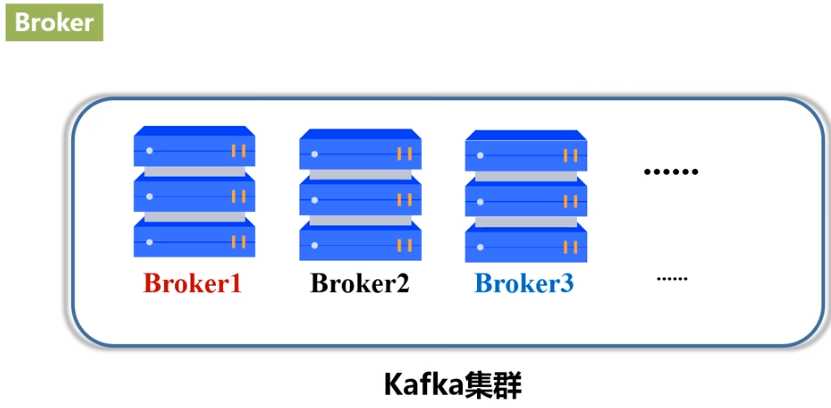

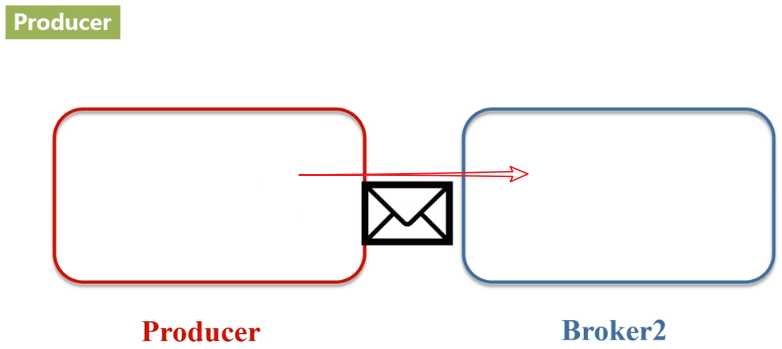
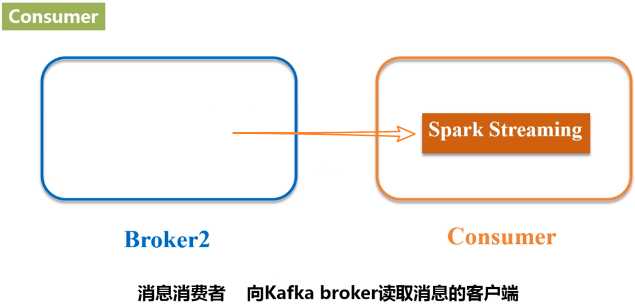
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。
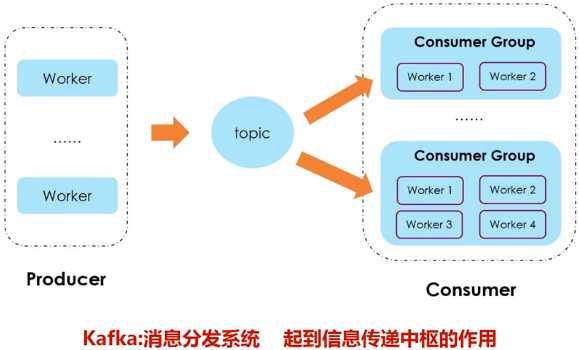
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。
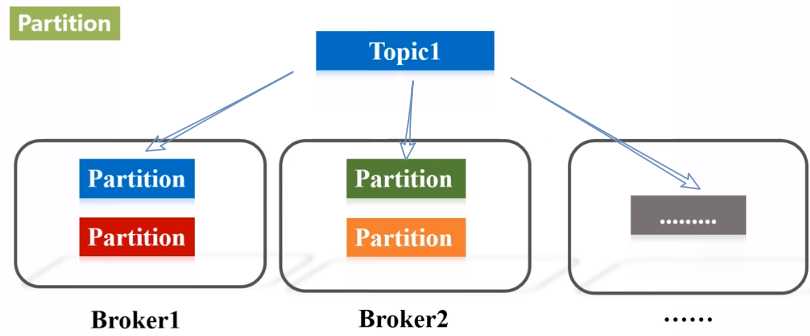
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition。
- Producer:负责发布消息到Kafka broker。
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
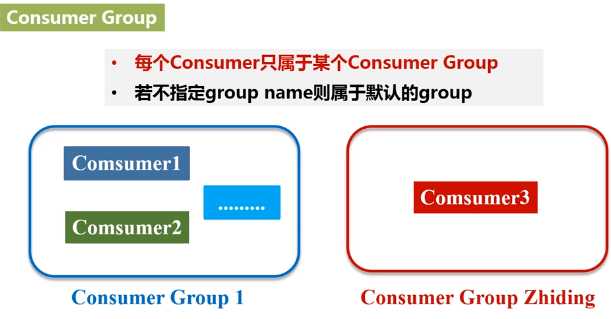
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
二、Kafka准备工作
1.安装Kafka
这里假设已经成功安装Kafka到“/usr/local/kafka”目录下
2.启动Kafka
下载的安装文件为Kafka_2.11-0.10.2.0.tgz,前面的2.11就是该Kafka所支持的Scala版本号,后面的0.10.2.0是Kafka自身的版本号。
打开一个终端,输入下面命令启动Zookeeper服务:

千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了。
打开第二个终端,然后输入下面命令启动Kafka服务:

千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了。
3.测试Kafka是否正常工作
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:

三、Spark准备工作
四、编写Spark Streaming程序使用Kafka数据源
以上是关于7.5 高级数据源的主要内容,如果未能解决你的问题,请参考以下文章