Hibernate的批量处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate的批量处理相关的知识,希望对你有一定的参考价值。
参考技术AHibernate批量处理其实从性能上考虑 它是很不可取的 浪费了很大的内存 从它的机制上讲 Hibernate它是先把符合条件的数据查出来 放到内存当中 然后再进行操作 实际使用下来性能非常不理想 在笔者的实际使用中采用下面的第三种优化方案的数据是 条数据插入数据库 主流台式机的配置 需要约 分钟 呵呵 晕倒
总结下来有三种来处理以解决性能问题
绕过Hibernate API 直接通过 JDBC API 来做 这个方法性能上是比较好的 也是最快的
运用存储过程
还是用Hibernate API 来进行常规的批量处理 可以也有变 变就变在 我们可以在查找出一定的量的时候 及时的将这些数据做完操作就
删掉 session flush() session evict(XX对象集) 这样也可以挽救一点性能损失 这个 一定的量 要就要根据实际情况做定量参考了 一般为 左右 但效果仍然不理想
绕过Hibernate API 直接通过 JDBC API 来做 这个方法性能上是比较好的 也是最快的 (实例为 更新操作)
Transaction tx=session beginTransaction() //注意用的是hibernate事务处理边界
Connection conn=nnection()
PreparedStatement stmt=conn preparedStatement( update CUSTOMER as C set C sarlary=c sarlary+ where c sarlary> )
stmt excuteUpdate()
mit() //注意用的是hibernate事务处理边界
这小程序中 采用的是直接调用JDBC 的API 来访问数据库 效率很高 避免了Hibernate 先查询出来加载到内存 再进行操作引发的性能问题
运用存储过程 但这种方式考虑到易植和程序部署的方便性 不建议使用 (实例为 更新操作)
如果底层数据库(如Oracle)支持存储过程 也可以通过存储过程来执行批量更新 存储过程直接在数据库中运行 速度更加快 在Oracle数
据库中可以定义一个名为batchUpdateCustomer()的存储过程 代码如下
代码内容create or replace procedure batchUpdateCustomer(p_age in number) as begin update CUSTOMERS set AGE=AGE+ where AGE>p_age end
以上存储过程有一个参数p_age 代表客户的年龄 应用程序可按照以下方式调用存储过程
代码内容
tx = session beginTransaction()
Connection con=nnection()
String procedure = call batchUpdateCustomer(?)
CallableStatement cstmt = con prepareCall(procedure)
cstmt setInt( ) //把年龄参数设为
cstmt executeUpdate()
mit()
从上面程序看出 应用程序也必须绕过Hibernate API 直接通过JDBC API来调用存储过程
还是用Hibernate API 来进行常规的批量处理 可以也有变 变就变在 我们可以在查找出一定的量的时候 及时的将这些数据做完操作就
删掉 session flush() session evict(XX对象集) 这样也可以挽救一点性能损失 这个 一定的量 要就要根据实际情况做定量参考了……
(实例为 保存操作)
业务逻辑为 我们要想数据库插入 条数据
tx=session beginTransaction()
for(int i= i< i++)
Customer custom=new Customer()
custom setName( user +i)
session save(custom)
if(i% == ) // 以每 个数据作为一个处理单元 也就是我上面说的 一定的量 这个量是要酌情考虑的
session flush()
session clear()
这样可以把系统维持在一个稳定的范围……
在项目的开发过程之中 由于项目需求 我们常常需要把大批量的数据插入到数据库 数量级有万级 十万级 百万级 甚至千万级别的 如此数量级别的数据用Hibernate做插入操作 就可能会发生异常 常见的异常是OutOfMemoryError(内存溢出异常)
首先 我们简单来回顾一下Hibernate插入操作的机制 Hibernate要对它内部缓存进行维护 当我们执行插入操作时 就会把要操作的对象全部放到自身的内部缓存来进行管理
谈到Hibernate的缓存 Hibernate有内部缓存与二级缓存之说 由于Hibernate对这两种缓存有着不同的管理机制 对于二级缓存 我们可以对它的大小进行相关配置 而对于内部缓存 Hibernate就采取了 放任自流 的态度了 对它的容量并没有限制 现在症结找到了 我们做海量数据插入的时候 生成这么多的对象就会被纳入内部缓存(内部缓存是在内存中做缓存的) 这样你的系统内存就会一点一点的被蚕食 如果最后系统被挤 炸 了 也就在情理之中了
我们想想如何较好的处理这个问题呢?有的开发条件又必须使用Hibernate来处理 当然有的项目比较灵活 可以去寻求其他的方法
笔者在这里推荐两种方法 ( ) 优化Hibernate 程序上采用分段插入及时清除缓存的方法
( ) 绕过Hibernate API 直接通过 JDBC API 来做批量插入 这个方法性能上是最 好的 也是最快的
对于上述中的方法 其基本是思路为 优化Hibernate 在配置文件中设置hibernate jdbc batch_size参数 来指定每次提交SQL的数量 程序上采用分段插入及时清除缓存的方法(Session实现了异步write behind 它允许Hibernate显式地写操作的批处理) 也就是每插入一定量的数据后及时的把它们从内部缓存中清除掉 释放占用的内存
设置hibernate jdbc batch_size参数 可参考如下配置
<hibernate configuration> <session factory>……
<property name= hibernate jdbc batch_size > </property>……
<session factory> <hibernate configuration>
配置hibernate jdbc batch_size参数的原因就是尽量少读数据库 hibernate jdbc batch_size参数值越大 读数据库的次数越少 速度越快 从上面的配置可以看出 Hibernate是等到程序积累到了 个SQL之后再批量提交
笔者也在想 hibernate jdbc batch_size参数值也可能不是设置得越大越好 从性能角度上讲还有待商榷 这要考虑实际情况 酌情设置 一般情形设置 就可以满足需求了
程序实现方面 笔者以插入 条数据为例子 如
Session session=HibernateUtil currentSession()
Transatcion tx=session beginTransaction()
for(int i= i< i++)
Student st=new Student()
st setName( feifei )
session save(st)
if(i% == ) //以每 个数据作为一个处理单元
session flush() //保持与数据库数据的同步
session clear() //清除内部缓存的全部数据 及时释放出占用的内存
mit()
……
在一定的数据规模下 这种做法可以把系统内存资源维持在一个相对稳定的范围
注意 前面提到二级缓存 笔者在这里有必要再提一下 如果启用了二级缓存 从机制上讲Hibernate为了维护二级缓存 我们在做插入 更新 删除操作时 Hibernate都会往二级缓存充入相应的数据 性能上就会有很大损失 所以笔者建议在批处理情况下禁用二级缓存
对于方法 采用传统的JDBC的批处理 使用JDBC API来处理
些方法请参照java 批处理自执行SQL
看看上面的代码 是不是总觉得有不妥的地方?对 没发现么!这还是JDBC的传统编程 没有一点Hibernate味道
可以对以上的代码修改成下面这样
Transaction tx=session beginTransaction() //使用Hibernate事务处理
边界Connection conn=nnection()
PrepareStatement stmt=conn prepareStatement( insert into T_STUDENT(name) values(?) )
for(int j= j++ j< )
for(int i= i++ j< )
stmt setString( feifei )
stmt executeUpdate()
mit() //使用 Hibernate事务处理边界
……
这样改动就很有Hibernate的味道了 笔者经过测试 采用JDBC API来做批量处理 性能上比使用Hibernate API要高将近 倍 性能上JDBC 占优这是无疑的
批量更新与删除
Hibernate 中 对于批量更新操作 Hibernate是将符合要求的数据查出来 然后再做更新操作 批量删除也是这样 先把符合条件的数据查出来 然后再做删除操作
这样有两个大缺点 ( ) 占用大量的内存
( ) 处理海量数据的时候 执行update/delete语句就是海量了 而且一条update/delete语句只能操作一个对象 这样频繁的操作数据库 性能低下应该是可想而知的了
Hibernate 发布后 对批量更新/删除操作引入了bulk update/delete 其原理就是通过一条HQL语句完成批量更新/删除操作 很类似JDBC的批量更新/删除操作 在性能上 比Hibernate 的批量更新/删除有很大的提升
Transaction tx=session beginSession()
String HQL= delete STUDENT
Query query=session createQuery(HQL)
int size=query executeUpdate()
mit()
……
控制台输出了也就一条删除语句Hibernate delete from T_STUDENT 语句执行少了 性能上也与使用JDBC相差无几 是一个提升性能很好的方法 当然为了有更好的性能 笔者建议批量更新与删除操作还是使用JDBC 方法以及基本的知识点与上面的批量插入方法 基本相同 这里就不在冗述
笔者这里再提供一个方法 就是从数据库端来考虑提升性能 在Hibernate程序端调用存储过程 存储过程在数据库端运行 速度更快 以批量更新为例 给出参考代码
首先在数据库端建立名为batchUpdateStudent存储过程
create or replace produre batchUpdateStudent(a in number) as
begin
update STUDENT set AGE=AGE+ where AGE>a
end
调用代码如下
Transaction tx=session beginSession()
Connection conn=nnection()
String pd= ……call batchUpdateStudent(?)
CallableStatement cstmt=conn PrepareCall(pd)
cstmt setInt( ) //把年龄这个参数设为
mit()
观察上面的代码 也是绕过Hibernate API 使用 JDBC API来调用存储过程 使用的还是Hibernate的事务边界 存储过程无疑是提高批量处理性能的一个好方法 直接运行与数据库端 某种程度上讲把批处理的压力转接给了数据库
三 编后语
本文探讨了Hibernate的批处理操作 出发点都是在提高性能上考虑了 也只是提供了提升性能的一个小方面
lishixinzhi/Article/program/Java/ky/201311/28885
Hibernate批量处理数据HQL连接查询
一、批量处理操作
批量处理数据是指在一个事务场景中处理大量数据。在应用程序中难以避免进行批量操作,Hibernate提供了以下方式进行批量处理数据:
(1)使用HQL进行批量操作 数据库层面
(2)使用JDBC API进行批量操作 数据库层面
(3)使用Session进行批量操作 会进缓存
1.使用HQL进行批量操作
HQL可以查询数据,也可以批量插入、更新和删除数据。HQL批量操作实际上直接在数据库中完成,处理的数据不需要加载到Session缓存中。使用Query接口的executeUpdate()方法执行用于插入、更新和删除的HQL语句。
以Emp和Dept为例:
例:批量添加3个部门

@Test
public void addTest(){
String hql="insert into Dept(deptName) select d.deptName||d.deptNo from Dept d where d.deptNo>0";
Query query=session.createQuery(hql);
int count=query.executeUpdate();
System.out.println("add ok!!");
}
输出结果:

2.使用JDBC API进行批量操作
在Hibernate应用中使用JDBC API批量执行插入、修改和删除语句时,需要使用Session的doWork(Work work)方法执行Work对象指定的操作,即调用Work对象的execute()方法。Session把当前使用的数据库连接传给execute()方法,执行持久化操作。
例:实现批量修改部门名称
将部门编号大于3的修改为开发部
注意:该方式使用的连接依然是最初的连接对象,并且命令对象依然是根据连接创建的,注意这里是SQL语句,不是HQL语句
@Test
public void updateTest(){
final String sql="update Dept set deptname=? where deptno>?";
Work work=new Work(){
public void execute(Connection con) throws SQLException{
PreparedStatement ps = con.prepareStatement(sql);
ps.setString(1,"开发部");
ps.setInt(2, 3);
int count=ps.executeUpdate();
//System.out.println(count);
}
};
session.doWork(work);
System.out.println("update ok!!!");
}
实现效果:

3、实现session进行批量操作
使用Session对象处理大量持久化对象,需及时从缓存中清空已经处理完毕并且不会再访问的对象。可以在处理完成一个对象或小批量对象后,调用flush()方法强制同步缓存和数据库,然后调用clear()方法清空缓存。
例:批量添加15个员工
/*
* session 实现批量添加15个员工
*/
@Test
public void addSessionTest(){
for(int i=0;i<=15;i++){
Emp emp=new Emp();
emp.setEmpName("呵呵"+i);
Dept dept=new Dept();
dept.setDeptNo(1);
emp.setDept(dept);
session.save(emp);
if(i%10==0){
session.flush();
session.clear();
}
}
System.out.println("add ok!!");
}
输出结果:

二、HQL连接查询
HQL提供的连接方式如下表所示:

内连接:
语法:
from Entity inner join Entity.property
例:使用内连接查询员工隶属的部门
list集合中的每个元素都是一个Object数组,from后面紧接的是部门 则输出的先是部门的内存地址
/*
* 内连接 员工隶属的部门
*/
@Test
public void innerTest(){
Query query=session.createQuery("from Dept d inner join d.emps");
List<Object[]> list = query.list();
for (Object[] item : list) {
//一个item就是一个数组
System.out.println(((Dept)item[0]).getDeptName()+"\\t"+((Emp)item[1]).getEmpName());
}
}
输出结果:

隐式内连接:
在HQL查询语句中,如果对Emp类赋别名为”e”,可以通过e.dept.deptName的形式访问dept对象的deptName属性。使用隐式内连接按部门查询员工信息。
例:按部门条件查询员工信息
/*
* 隐式内连接 按部门条件查询员工信息
*/
@Test
public void hideTest(){
Query query=session.createQuery("from Emp e where e.dept.deptName=\'开发部\'");
List<Emp> list = query.list();
for (Emp item : list) {
//一个item就是一个数组
System.out.println(item.getEmpName());
}
}
输出结果:

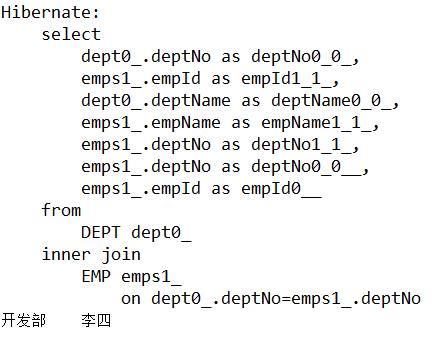
3、迫切内连接
例:查询所有的雇员名称和隶属部门名称 需使用关键字fetch
/*
* 迫切内连接 查询所有的雇员名称和隶属部门名称
*/
@Test
public void FetchTest(){
Query query=session.createQuery("from Dept d inner join fetch d.emps");
List<Dept> list=query.list();
for (Dept item : list) {
System.out.println(item.getDeptName()+"\\t"+item.getEmps().iterator().next().getEmpName());
}
}
输出结果:
以上是关于Hibernate的批量处理的主要内容,如果未能解决你的问题,请参考以下文章