drools 决策引擎介绍开发
Posted renfeihn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了drools 决策引擎介绍开发相关的知识,希望对你有一定的参考价值。
1. 背景介绍
1.1 何为规则引擎
很多企业的IT业务系统中,经常会有大量的业务规则配置,而且随着企业管理者的决策变化,这些业务规则也会随之发生更改,为了适应这样的需求,IT业务系统应该能够快速且低成本的更新,通常做法是将业务规则的配置单独拿出来,使之与业务系统保持低耦合,实现这样功能的程序,叫做规则引擎。
接受数据输入,解释业务规则,并根据业务规则作出业务决策,从而实现了将业务决策从应用程序中分离出来。
1.2 一个实际的例子
银行贷款业务中,每种贷款类型都有不同的业务规则,并且这些规则也可能会根据实际应用情况进行调整,如觉得网贷产品类型有如下判定规则:
- 如果公积金缴存基数大于6000则进入白领贷
- 如果公积金缴存基数小于6000但单位性质是国家机关/事业单位也进入白领贷
- 如果公积金缴存基数小于6000且单位性质为非国家机关/事业单位则进入市民易贷
- 如果公积金缴存基数小于6000并且单位性质缺失则进入公积金贷
如果在代码中处理这类业务逻辑,会有很多的IF/ELSE,并且如果规则发生变化,还需要重新编写代码、编译、部署才能上线。
而通过规则引擎,可以方便的将这类业务强相关的逻辑放到规则引擎中执行

1.3 规则引擎的优点
对系统的使用人员
l 把业务策略(规则)的创建、修改和维护的权利交给业务经理
l 提高业务灵活性
l 加强业务处理的透明度,业务规则可以被管理
l 减少对IT人员的依赖程度
l 避免升级的风险
对IT开发人员
l 简化系统架构,优化应用
l 提高系统的可维护性和维护成本
l 方便系统的整合
l 减少编写“硬代码”业务规则的成本和风险
2. Drools简介
Drools是一款基于Java的开源规则引擎,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件或特定的数据库中,使得业务规则的变更不需要修改代码即可在线上环境生效。
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用代码中分离出来,并使用预定义的语义模块编写业务决策。接收数据输入,解释业务规则,并根据业务规则作出业务决策。
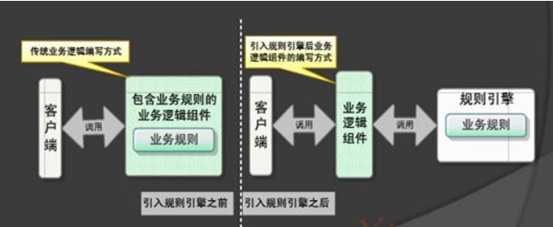
3. Drools基本概念
3.1 工作流程
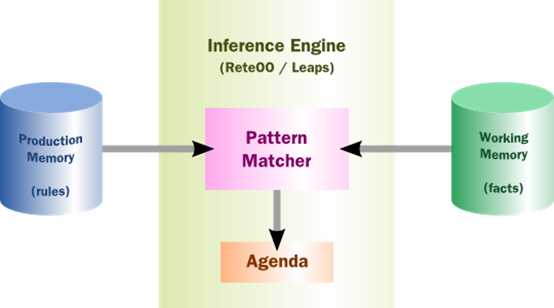
需要判定的规则加载进ProductionMemory
需要判定的fact对象插入到WorkingMemory
推理引擎(Inference Engine)通过模式匹配器(Pattern Matcher)对规则和fact对象进行批评,如果有规则匹配成功,则将待执行的规则放入Agenda(议事日程)队列中等待执行。
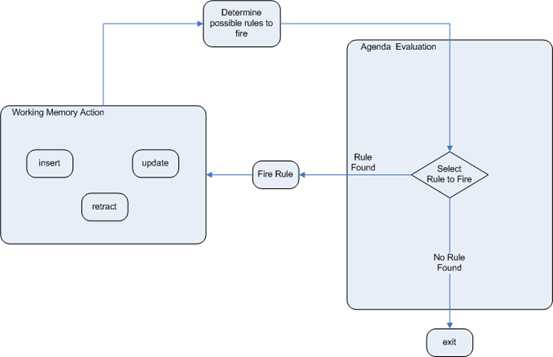
当Agenda队列中的规则执行的过程中如果对WorkingMemory中的Fact对象进行了insert/update/delete操作时,需要重新进行推理判定,刷新Agenda队列中的执行序列。
当Agenda队列中所有规则执行完毕后,结束当前任务。
3.2 Fact对象
Fact对象指传递给Drools脚本的对象,是一个普通的POJO,可以对该Fact对象进行读写操作,并调用该对象的方法。
当一个POJO插入到WorkingMemory中变成Fact之后,Fact对象不是对原来POJO对象进行Clone,而是对原有对象的引用。规则通过对fact对象的读写,实现对应用数据的读写,对其中的属性,需要提供get/set方法,通过这些getter 和setter 方法可以方便的实现对Fact 对象的读写操作,所以我们可以简单的把Fact 对象理解为规则与应用系统数据交互的桥梁或通道。
规则中可以动态的在WorkingMemory中插入删除新的fact对象。
3.3 Rete算法简介
Rete算法是Charles Forgy博士在1979年的论文中首次提出的,针对基于规则知识表现的模式匹配算法。当前,大部分规则引擎都是基于Rete算法为核心。
Rete算法是一个用于产生式系统的高效模式匹配算法。在一个产生式系统中,被处理的数据叫做WorkingMemory,用于判定的规则分为两个部分LHS(left-hand-side)和RHS(right hand side),分别表示前提和结论。主要流程可以分为以下步骤:
- Match:找出符合LHS部分的WorkingMemory集合
- Confilict resolution:选出一个条件被满足的规则
- Act:执行RHS的内容
- 返回第一步
Rete算法主要改进Match的处理过程,通过构建一个网络进行匹配。
3.4 基础语法
Drools文件中最重要的是:包路径、引用、规则体
一个DRL文件的例子HelloWorld.drl
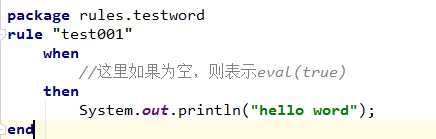
package:包路径。该路径是逻辑路径,可以随便写,但不能不写,已.的方式隔开,规则文件中永远是第一行
import:引用。导入规则文件需要使用到的外部变量,可以导入类,也可以是类中的静态方法
rule:规则体。以rule开头,以end结尾,每个文件可以包含多个rule,规则体分为3个部分:LHS、RHS、属性。
LHS:(Left Hand Side),条件部分,在一个规则当中”when”和”then”中间的部分就是LHS部分,在LHS当中,可以包含0~N个条件,如果LHS为空的话,那么引擎会自动添加一个eval(true)的条件。
RHS:(Right Hand Side),是规则真正做事情的部分,满足条件触发动作的操作部分,在RHS中可以使用LHS部分当中定义的绑定变量名、设置的全局变量、或者是直接编写的java代码,也可以使用import的类,虽然可以,但不建议在RHS中有条件判断。
RHS中可以使用insert/update/modify/delete实现对当前WorkingMemory中Fact对象的新增/修改/删除。
3.5 KIE API
3.5.1什么是KIE
KIE是jBoss里面一些相关项目的统称,下图就是KIE代表的一些项目,其中我们比较熟悉的就有jBPM和Drools。
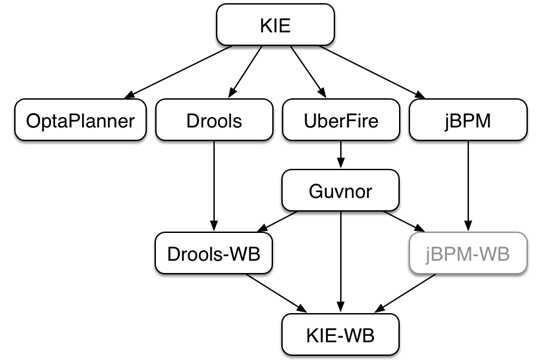
jBPM:工作流引擎
Drools:规则引擎
OptaPlanner:规划引擎
Guvnor:业务规划管理系统(Drools 6.0后已被WorkBench替换)
这些项目都有一定的关联关系,并且存在一些通用的API,比如说涉及到构建(building)、部署(deploying)和加载(loading)等方面的,这些API就都会以KIE作为前缀来表示这些是通用的API。
总的来说,就是jBoss通过KIE将jBPM和Drools等相关项目进行了一个整合,统一了他们的使用方式。像KieServices这些KIE类就是整合后的结果,在Drools中这样使用,在jBPM里面也是这样使用。
在Drools当中,规则的编译与运行要通过Drools提供的各种API来实现,这些API总体来讲可以分为三类:规则编译、规则收集和规则执行。完成这些工作的API主要有KnowledgeBuilder、KnowledgeBase、StatefulKnowledgeSession、StatelessKnowledgeSession等,它们起到了对规则文件进行收集、编译、查错、插入fact、设置global、执行规则或规则流等作用。
3.5.2 KnowledgeBuilder
KnowledgeBuilder的作用是用来在业务代码当中收集已经编写好的规则,然后对这些规则文件进行编译,最终产生一批编译好的规则包(KnowledgePackage)给其他的应用程序使用。
KnowledgeBuilder在编译规则的时候可以通过其提供的hasErrors()方法得到编译规则过程中发现规则是否有错误,如果有的话通过其提供的getErrors()方法将错误打印出来,以帮助我们找到规则当中的错误信息。
通过KnowledgeBuilder编译的规则文件的类型有很多种,如.drl文件或一个xls文件等。产生的规则包可以是具体的规则文件行程的,也可以是规则流(rule flow)文件形成的,在添加规则文件时,需要通过使用ResourceType枚举值来指定规则文件的类型;同时在指定规则文件的时候drools还提供了一个名为ResourceFactory的对象,通过该对象可以实现从Classpath、URL、File、ByteArray、Reader或诸如XLS的二进制文件里加载规则。
3.5.3 KnowledgeBase
KnowledgeBase是Drools提供的用来收集应用当中知识(Knowledge)定义的知识库对象,在一个KnowledgeBase当中可以包含普通的规则(rule)、规则流(rule flow)、函数定义(function)、用户自定义的对象(type model)等。
业务对象都是插入到由KnowledgeBase产生的两种类型的session 对象当中(StatefulKnowledgeSession 和StatelessKnowledgeSession,后面会有对应的章节对这两种类型的对象进行介绍),通过session 对象可以触发规则执行或开始一个规则流执行。
KnowledgeBase 创建完成之后,接下来就可以将我们前面使用KnowledgeBuilder 生成的KnowledgePackage 的集合添加到KnowledgeBase 当中。
3.5.4 StatefulKnowledgeSession
StatefulKnowledgeSession 对象是一种最常用的与规则引擎进行交互的方式,它可以与规则引擎建立一个持续的交互通道,在推理计算的过程当中可能会多次触发同一数据集。接收外部插入的数据fact对象(POJO),将编译好的规则包和业务数据通过fireAllRules()方法触发所有的规则执行。使用完成需调用dispose()方法以释放相关内存资源。
3.5.5 StatelessKnowledgeSession
对StatefulKnowledgeSession的封装实现,与其对比不需要调用dispose()方法释放内存,只能插入一次fact对象,StatelessKieSession隔离了每次与规则引擎的交互,不会维护会话状态。
4. Drools详细介绍
4.1 Drl
在Drools当中,一个标准的规则文件就是一个以”.drl”结尾的文本文件,由于它是一个标准的文本文件,所以可以通过一些记事本工具对其进行打开、查看和编辑。规则是放在规则文件当中的,一个规则文件可以存放多个规则,除此之外,在规则文件当中还可以存放用户自定义的函数、数据对象及自定义查询等相关在规则当中可能会用到的一些对象。
一个标准的规则文件的结构代码:

package package-name(包名,必须的,用于逻辑上的管理,若自定义查询或函数属于同一个包名,不管物理位置如何,都可以调用),package在规则文件中是第一行,其他的顺序可以是无序的
import(需要导入的类名)
globals(全局变量)
functions(函数)
queries(查询)
rules(规则,可以多个)

一个规则包含三部分:只有attributes部分可选,其他都是必填
4.1.1 属性attributes
定义当前规则执行的一些属性等,比如是否可被重复执行,过期时间,生效时间等。
Salience 优先级
作用:设置规则执行的优先级,值是一个数字,数字越大执行的优先级越高,它的值可以是一个负数,默认值是0。如果我们不手动设置salience属性值,则执行顺序是随机的。
no-loop 防止死循环
在一个规则中如果条件满足就对Working Memory当中的某个Fact对象进行修改,比如使用update将其更新到当前的Working Memory当中,这时候引擎会再次检查所有的规则是否满足条件,如果满足会再执行,可能会出现死循环。
作用:用来控制已经执行过的规则条件再次满足时是否再次执行,默认是false,如果属性值是true,表示该规则只会被规则引擎检查一次。
lock-on-active 规则执行一次
当在规则上使用ruleflow-group属性或agenda-group属性的时候,将lock-on-active属性的值设置为true,可以避免因某些Fact对象被修改而使已经执行过的规则再次被激活执行。可以看出该属性与no-loop属性有相似之处,no-loop属性是为了避免Fact修改或调用了insert,retract,update之类导致规则再次激活执行,这里lock-on-active属性也是这个作用,lock-on-active是no-loop的增强版。
作用:在使用ruleflow-group属性或agenda-group属性的时候,默认是false,设置为true,该规则只会执行一次。
ruleflow-group 规则流分组
在使用规则流的时候要用到ruleflow-group属性,该属性的值为一个字符串,作用是将规则划分为一个个的组,然后在规则流当中通过使用ruleflow-group属性的值,从而使用对应的规则。该属性会通过流程的走向确定要执行哪一条规则。
4.1.2 LHS
定义当前规则的条件,如 when Message();判断当前workingMemory中是否存在Message对象。
LHS部分是由一个或多个条件组成,条件又称为pattern(匹配模式),多个pattern之间可以使用 and 或 or来进行连接,同时还可以使用小括号来确定pattern的优先级
【绑定变量名:】Object(【filed 约束】)
对于一个pattern来说"绑定变量名"是可选的,如果在当前规则的LHS部分的其他pattern要使用这个对象,那么可以通过为该对象绑定设定一个绑定变量名来实现对其的引用,对于绑定变量的命名,通常的做法是为其添加一个 "$"符号作为前缀,可以和Fact对象区分开来。
绑定变量可以用于对象上,可以用于对象属性上,"field约束"是指当前对象里相关字段的条件限制。
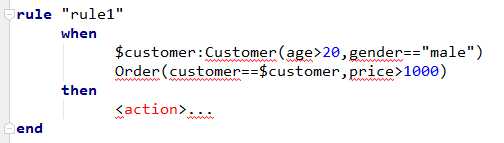
以上,
第一个pattern有三个约束
1、对象类型必须是Customer;
2、Customer的age要大于20
3、Customer的gender要是male
第二个pattern有三个约束
1、对象类型必须是Order
2、Order对应的Customer必须是前面那个Customer
3、当前这个Order的price要大于1000
这两个pattern没有符号连接,在Drools当中没有连接符号,默认是and,只有两个pattern(模式)都满足才会返回true。
4.1.3 RHS
RHS是满足LHS条件之后进行后续处理部分的统称,该部分包含要执行的操作的列表信息。RHS主要用于处理结果,因此不建议在此部分再进行业务判断。
RHS的主要功能是对working memory中的数据进行insert、update、delete或modify操作,Drools提供了相应的内置方法来帮助实现这些功能。
RHS中可以写java代码,即当前规则条件满足执行的操作,可以直接调用Fact对象的方法来操作应用。
4.1.4 Function函数
函数是将语义代码放置在规则文件中的一种方式,就相当于java类中的方法一样。使用函数的好处是可以将业务逻辑集中放置在一个地方,根据需要可以对函数进行修改。
4.2 决策表
决策表是一个”精确而紧凑的”表示条件逻辑的方式,非常适合商业级别的规则。目前决策表支持xls格式和csv格式。
4.2.1 何时使用决策表
如果规则能够被表达为模板+数据的格式,可以考虑使用决策表。
决策表中的每一行就是对应一行数据,将产生一个规则。
4.2.2 运行决策表
首先,决策表将转换为Drools规则语言(DRL),然后执行规则引擎需求。
4.2.3 决策表的配置
全局配置:


RuleTable部分

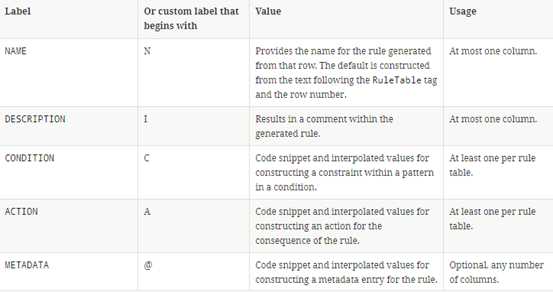
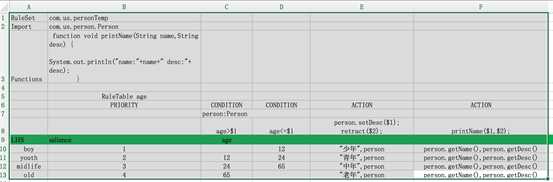
4.2.4 决策表例子
年龄分类规则如下:
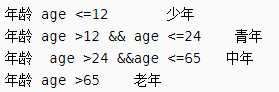
决策表设计:
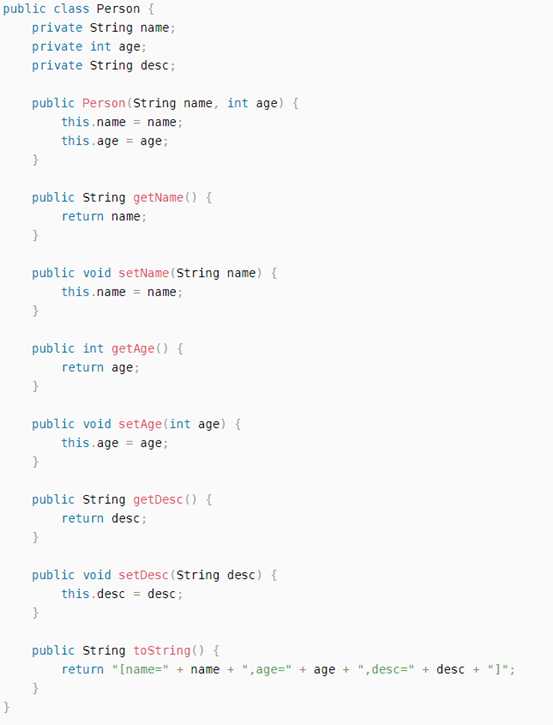
POJO对象:
测试类:

结果:

4.3 规则流
4.3.1 什么是规则流
规则流能够控制,规则中的复杂流程,在复杂业务中,很多时候并不需要触发所有的规则,很多时候需要触发的规则也需要像程序一样,符合某些逻辑,如,当X对象X 属性等于 A 时,触发 规则A 中的规则,当等于B时,触发规则B中的规则,这时候用规则流就能够很好的处理这类问题。
4.3.2 如何使用规则流
创建规则流文件如score.bpmn
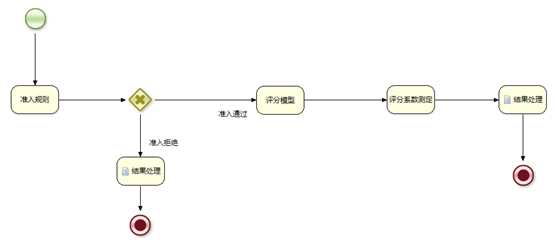
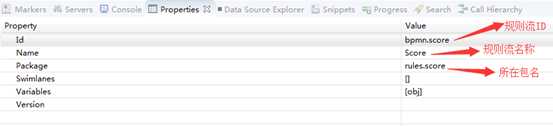
指定规则文件相关属性:
流程中指定,评分模型的规则组:
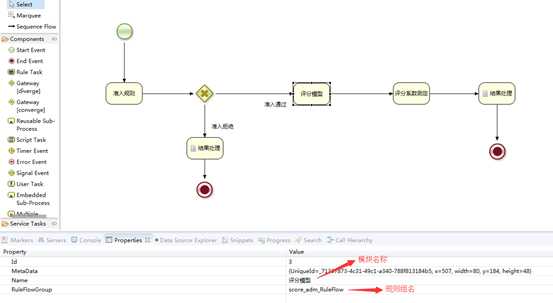
设置网关判定条件:
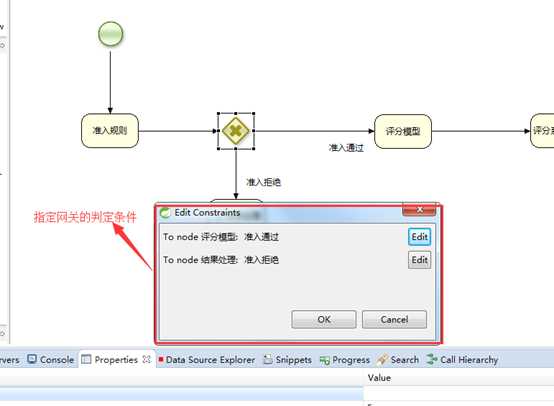
编辑各条网关连接线的判断依据:
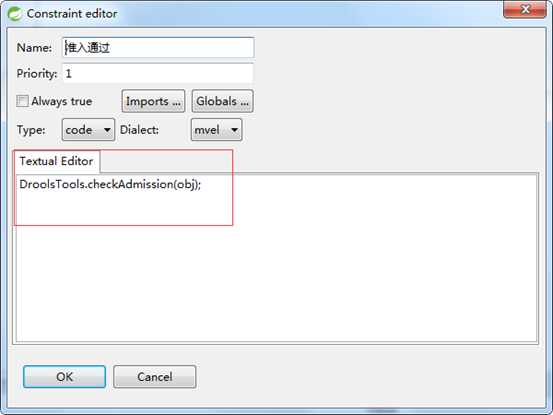
4.3.3 规则流组件
RuleTask
规则任务,可和规则文件中指定规则组关联
ScriptTask
脚本任务,可编写脚本完成指定任务
Gateway
按网关方向可分为聚合网关diverging gateway和分散网关converging gateway
按网关类型可分为:
u 唯一网关XOR网关
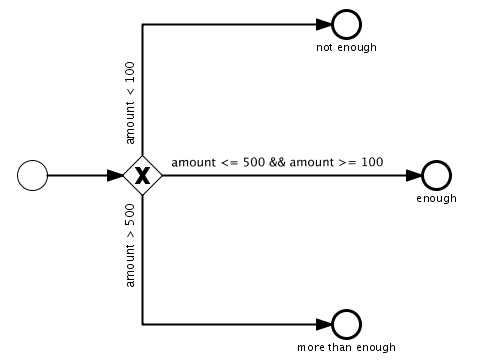
唯一网关会选择一个顺序流, 如果条件执行为true。如果多个条件 执行为true,第一个遇到的就会被使用。
u 并行网关AND网关
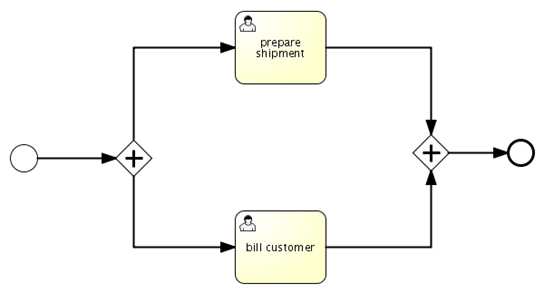
l 并行网关拥有一个进入顺序流的和多于一个的外出顺序流 叫做‘并行切分或 ‘AND-split‘。所有外出顺序流都会 被并行使用。
l 并行网关拥有多个进入顺序流和一个外出顺序流 叫做‘并行归并‘或 AND-join。所有进入顺序流需要 到达这个并行归并,在外向顺序流使用之前。
u 包含网关OR网关
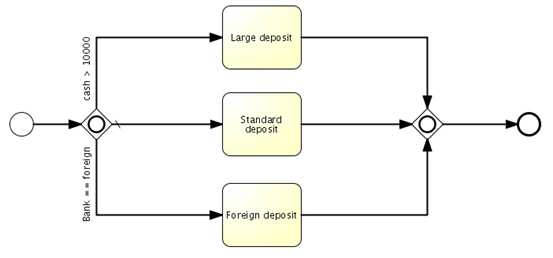
包含网关先后执行为true的分支。
5. 开发环境搭建
5.1安装Drools插件
5.1.1 下载Drools插件
可以去工具集中下载
5.1.2 安装Drools插件
Help->Install New Software
重启Eclipse,如果Preferences中出现Drools则说明插件安装成功。
5.2安装Drools Runtimes(Drools运行时)
5.2.1下载Drools Engine
5.2.2在Eclipse中指定Drools Runtimes
Windows->Preferences->Drools->Installed Drools Runtimes
可以新建Drools项目
6. Drools代码编写注意事项
6.1规则流部分
- 每个flow需要有至少一个进入点(Start Event)和一个退出点(End Event)
- 网关按方向有diverge(分离网关)和converge(汇聚网关),需要合理使用
- 网关按类型有唯一网关(XOR)、并行网关(AND)和包含网关(OR),需要合理使用
- 唯一网关(XOR)作为分离网关,会选择外出的多个顺序流中的一个
- 并行网关(AND)作为分离网关,拥有一个进入顺序流和多个外出顺序流,叫做“并行切分(AND-split)”,所有的外出顺序流都会被执行
- 并行网关(AND)作为汇聚网关,拥有多个进入顺序流和一个外出顺序流,叫做“并行归并(AND-join)”,所有进入顺序流都需要到达并行网关,才会执行外出顺序流
- 包含网关(OR)基本行为和唯一网关类似,区别在于,满足条件的外出顺序流都会被执行
- Id唯一的代表一个flow元素,不能重复
- 界面创建flow元素后自动生成的MetaData的UniqueId需要检查不能以数字开头,否则调用规则流引擎时会报错
- 如果规则流需要引用WorkingMemory中的Fact对象,需要在规则流的Properties中定义Variables,此变量需要在Java代码调用规则流时作为参数传入
6.2决策表部分
- 合理设置RuleSet名称,确保不重复
- 决策表编写需注意格式,如CONDINTION下第四行是第一条数据(规则)配置行
- CONDITION和ACTION中都可以使用匹配Fact变量的成员函数
- ACTION中更新WorkingMemory中Fact对象后需考虑是否规则是否会反复触发导致死循环
- 如果想规则始终进入,可使用eval(true)
- CONDITION中如果使用可能会变化的Fact对象的Map中的value,需要使用原生的get方法
- CONDITION中使用占位符匹配规则时,如果是字符串需要用双引号引起来
6.3 Java代码部分
- 需要使用session的insert方法将需要处理的对象插入到WorkingMemory
- 如果规则流需要使用Fact对象,需要在调用规则流的时候将Fact对象放入map中,作为参数传入
- 启用规则流后,还需要调用session的fireAllRules才会执行匹配的规则
有状态session使用后必须显式调用dispose方法来释放,避免内存
以上是关于drools 决策引擎介绍开发的主要内容,如果未能解决你的问题,请参考以下文章