TTS2
Posted skydaddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TTS2相关的知识,希望对你有一定的参考价值。
语音合成系列 - SampleRNN
One WaveNet issue
前一段时间,学习了下WaveNet,一个DeepMind的信号生成模型,该模型在该领域已经众所周知。虽然据说原始博客中的WaveNet在音乐生成领域产生了非常有希望的结果,但我们无法重现这些结果,可能是因为缺乏计算资源。除了结果质量外,我们还可以看出WaveNet整体架构的一个主要问题 - 它真的很复杂。
不仅仅是理解的过程很难,然而在我们真正了解它是如何工作之后,很明显,对模型的任何修改都将会产生很多工作。实际上,在我们甚至考虑进一步开发模型之前,我们至少需要达到DeepMind的结果质量才能获得一些合理的基线。这需要一些广泛的超参数调整 - 而且由于WaveNet 实际上计算量很大,这意味着需要花费大量时间。
然而,WaveNet是一个巨大的突破 - 当我们开始研究它时,没有其他模型在逐个样本(sample-by-sample)的音频生成中有如此好的结果。
但是,有很多关于WaveNet的issues。
显然, one of WaveNet‘s issues ,它将我们引向了一个更有希望的模型。
SampleRNN
SampleRNN是“无条件的端到端的神经音频生成模型 An Unconditional End-to-End Neural Audio Generation Model”,由Soroush Mehri,Kundan Kumar,Ishaan Gulrajani,Rithesh Kumar,Shubham Jain,Jose Manuel Rodriguez Sotelo,Aaron Courville和Yoshua Bengio发明。正如描述所说,这个模型就像WaveNet一样,是一个用于逐个样本(sample-by-sample)生成音频的端到端模型。
与基于卷积层的WaveNet不同,SampleRNN基于循环层。据作者说,GRU单元效果最好,但可以使用任何类型的RNN单元。这些层layers被分组为“tiers”。这些tiers构成了一个层次结构:在每个tier中,单个时间步的输出,通过学习的上采样upsampling,从较低的tier调整几个时间步。因此,不同的tiers以不同的时钟速率运行,这意味着它们可以学习不同的抽象级别。例如,在最低tier中,一个时间步长对应于一个样本,而在最高层中,一个时间步长可以对应于四分之一秒,其可以包括一个或甚至几个单音notes。这样我们可以从表示作为一系列单音notes到一系列原始样本samples。此外,每个tier中的每个时间步长都由在同一tier中的先前时间步长中生成的样本来调节。最低tier不是recurrent的,而是一个自回归autoregressive的多层感知器MLP(multi-layer perceptron),由几个最后的样本和更高tier的输出决定。
让我们看一个例子(原始论文中的图例):
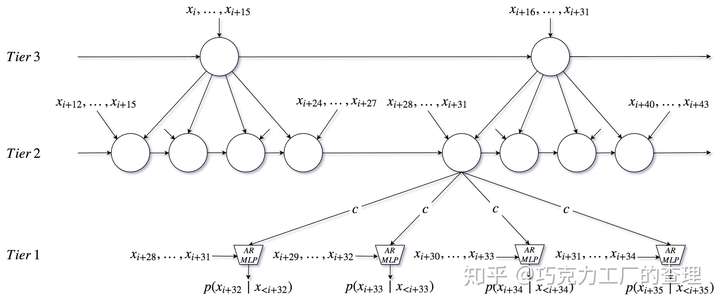
这里我们有3 tier。最低的一个是MLP,它将最后一个样本作为输入,从中间tier作为上采样输出。中间tier从最低tier开始,调整4个时间步长,并将最后生成的样本和最高tier的上采样输出作为输入。最高tier 调整了距离中间tier 4个时间步长,并将最后生成的16个样本作为输入,这是该tier的前一个时间步长生成的样本总数。
正如我们所看到的,这个模型很容易理解,因为它包含由上采样层分离的众所周知的recurrent layers,它们是普通的线性变换,以及一个多层感知器MLP。它的计算成本也很便宜,因为只有最低tier 在样本级别运行,而在较高级别会运行较慢,因此它们对总体计算时间的消耗较小。相比之下,WaveNet需要为每个样本计算每个layer的输出。
实验细节
实验:我们主要使用2-tier模型的默认参数,据作者说,这些参数最适合音乐:
- 在BPTT传递中设置为128帧(默认为64)
- 帧大小为16个样本(这是由较高tier中每个时间步长调整的样本数)
- embedding size 256
- no skip connections
- RNN和MLP的dimension设置为 1024
- 较高tier中设置为3个RNN层
- 256个quantization layers
- linear quantization
- batch size 设置为64(默认为128)
- weight normalization
- learning initial RNN state
我们使用与WaveNet实验相同的数据集:钢琴,吉他,古典音乐和环境音乐(ambient)。
实验结果
使用SampleRNN,一些有趣的输出结果:
钢琴:
http://deepsound.io/mp3/samplernn_first/piano.mp3
吉他:
http://deepsound.io/mp3/samplernn_first/guitar.mp3
古典:
http://deepsound.io/mp3/samplernn_first/classical.mp3
环境音乐 ambient:
http://deepsound.io/mp3/samplernn_first/ambient.mp3
结果肯定不是很完美,但绝对优于我们的复现WaveNet的结果,和从生成的频谱图中检索到的结果。吉他和环境音乐的样本听起来不太好,但钢琴和经典样本非常不错。至于生成的所需时间,SampleRNN远远超过WaveNet(这里只比较这两个模型,因为基于GAN的方法是完全不同的)。
正如您所听到的,与吉他音乐相比,一个令人惊讶的结果是古典音乐样本的质量。直观地说,古典音乐应该更难学,因为它包括几种具有不同演奏风格的乐器,而吉他很好学……只是吉他。听到网络模型学会演奏冲击镲(并且可以说它确实具有诀窍)以及一些清晰听到的管乐器 - 甚至可能是一些弓弦乐器,这真的很神奇(实际上非 常有趣)。
总结
正如我们可以看到的那样(或实际上听到),SampleRNN似乎在很多层面上击败了WaveNet的音乐 - 让我们只用更少的努力,更快的生成时间和非常重要的 - 简单的想法和代码,以及更好的结果。
以上是关于TTS2的主要内容,如果未能解决你的问题,请参考以下文章