MQ实现消息的幂等性
Posted snail-gao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MQ实现消息的幂等性相关的知识,希望对你有一定的参考价值。
一、什么是幂等性
可以参考数据库乐观锁机制,比如执行一条更新库存的 SQL 语句,在并发场景,为了性能和数据可靠性,会在更新时加上查询时的版本,并且更新这个版本信息。可能你要对一个事情进行操作,这个操作可能会执行成百上千次,但是操作结果都是相同的,这就是幂等性。
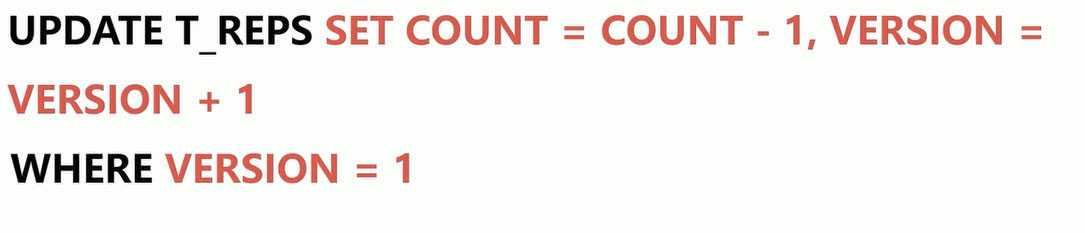
二、消费端的幂等性保障
在海量订单生成的业务高峰期,生产端有可能就会重复发生了消息,这时候消费端就要实现幂等性,这就意味着我们的消息永远不会被消费多次,即使我们收到了一样的消息。
业界主流的幂等性有两种操作:
1.唯一 ID + 指纹码 机制,利用数据库主键去重
2.利用redis的原子性去实现
三、唯一 ID + 指纹码 机制
大家肯定懂唯一 ID 的,就不多说了,为什么需要指纹码呢?这是为了应对用户在一瞬间的频繁操作,这个指纹码可能是我们的一些规则或者时间戳加别的服务给到的唯一信息码,它并不一定是我们系统生成的,基本都是由我们的业务规则拼接而来,但是一定要保证唯一性,然后就利用查询语句进行判断这个id是否存在数据库中。
好处:实现简单,就一个拼接,然后查询判断是否重复。
坏处:在高并发时,如果是单个数据库就会有写入性能瓶颈
解决方案 :根据 ID 进行分库分表,对 id 进行算法路由,落到一个具体的数据库,然后当这个 id 第二次来又会落到这个数据库,这时候就像我单库时的查重一样了。利用算法路由把单库的幂等变成多库的幂等,分摊数据流量压力,提高性能。
四、redis的原子性去实现
我们都知道redis是单线程的,并且性能也非常好,提供了很多原子性的命令。比如可以使用 setnx 命令。
在接收到消息后将消息ID作为key执行 setnx 命令,如果执行成功就表示没有处理过这条消息,可以进行消费了,执行失败表示消息已经被消费了。
使用 redis 的原子性去实现主要需要考虑两个点
第一:我们是否要进行数据落库,如果落库的话,关键解决的问题是数据库和缓存如何做到原子性?
采用延时双删策略
伪代码如下:
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}转化为中文描述就是
(1)先淘汰缓存
(2)再写数据库(这两步和原来一样)
(3)休眠1(根据业务自己设定)秒,再次淘汰缓存
这么做,可以将1秒内所造成的缓存脏数据,再次删除。
url:https://www.cnblogs.com/rjzheng/p/9041659.html
第二:如果不进行落库,那么都存储到缓存中,如何设置定时同步的策略(同步到关系型数据库)?缓存又如何做到数据可靠性保障呢
关于不落库,定时同步的策略,
目前主流方案有两种:
第一种为双缓存模式,异步写入到缓存中,也可以异步写到数据库,但是最终会有一个回调函数检查,这样能保障最终一致性,不能保证100%的实时性。
第二种是定时同步,比如databus同步。
以上是关于MQ实现消息的幂等性的主要内容,如果未能解决你的问题,请参考以下文章