burpsuite15分钟能破解一个6位验证码吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了burpsuite15分钟能破解一个6位验证码吗相关的知识,希望对你有一定的参考价值。
参考技术A 可以Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具。Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程。
如何用机器学习在15分钟内破解网站验证码系统?
我们今天以破解世界上最流行的WordPress验证码插件为例。

每个人都很讨厌验证码吧?这些烦人的小照片里有很多文本信息,只有输入它们后才能访问网站。人们设计验证码系统的初衷是为了验证访问网站的用户是一个真实的人。但随着深度学习和计算机视觉技术的进步,我们很容易就能打败这些验证码系统。(除非你遇到 12306 那种骚骚的图片识别验证,有时真的会陷入绝望)

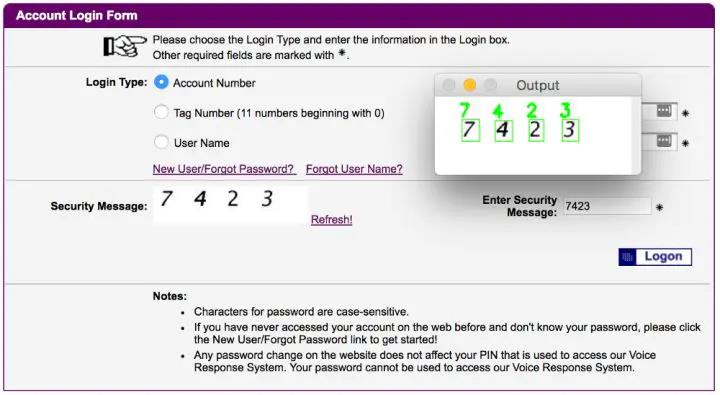
Adrian 没有访问网站生成验证码照片的工具的源代码,所以为了破解验证码,他必须下载几百个示例图像,然后手动用它们训练自己创建的机器学习系统。
但如果我们想破解一个我们能访问源代码的开源验证码系统呢?
然后到 WordPress 的插件注册网站上搜了一下“captcha”,第一条搜索结果是“Really Simple CAPTCHA”,有超过1百万的活动安装量:
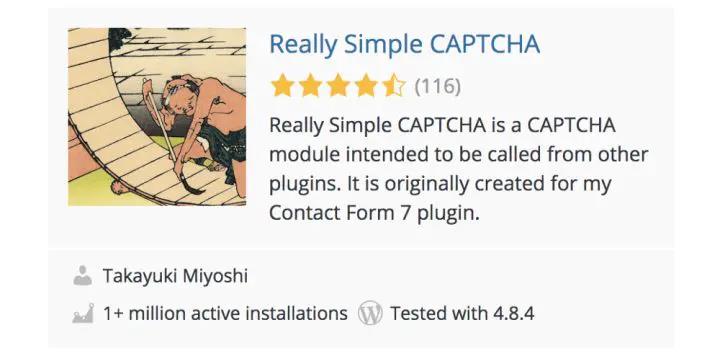
最棒的是它提供了源代码。因为我们能获取生成验证码的源代码,那破解它就比较容易了。我们可以再提高点难度,变得更有挑战性一点,比如在限定时间内完成破解。
我们能在15分钟内完全破解这个验证码系统吗?试试看!

特此声明:这么做完全没有批评“Really Simple CAPTCHA”插件及其作者的意思。插件作者自己也曾说过这款插件已经不是很安全了,建议换用其它插件。因此这纯属一次好玩的快速技术挑战。不过,如果你也是这款插件的用户,或许你真的该换其它的了。
挑战开始
在“发动进攻”前,我们先看看“Really Simple CAPTCHA”能生成什么样的验证码照片。在演示网站上,我们看到这样:
OK,那么验证码似乎是4个字母和数字的组合形式。我们在PHP源代码中验证一下:
public function __construct() {
/* Characters available in images */
$this->chars = 'ABCDEFGHJKLMNPQRSTUVWXYZ23456789';
/* Length of a word in an image */
$this->char_length = 4;
/* Array of fonts. Randomly picked up per character */
$this->fonts = array(
dirname( __FILE__ ) . '/gentium/GenBkBasR.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasI.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasBI.ttf',
dirname( __FILE__ ) . '/gentium/GenBkBasB.ttf',
);
没错,它以随机混合 4 个不同字体的形式生成 4 个字的验证码。我们也能发现它从不用字母“O”和“I”,因为这俩字母比较容易被用户搞混。所以我们需要识别 24 个英文字母和 10 个阿拉伯数字,也就是 32 个字混合组成的验证码。没问题!
迄今用时:2 分钟
使用工具
在正式开始挑战前,先讲一下我们会用到的工具:
Python 3
Python 是一种很有意思的编程语言,有很多用于机器学习和计算机视觉的很不错的程序库。
OpenCV
OpenCV 是计算机视觉和图像处理中一个很流行的框架。我们会用 OpenCV 处理验证码照片。它有一个 Python API,所以我们可以直接从 Python 中使用它。
Keras
Keras 是一个用 Python 编写的深度学习框架。用 Keras 可以只需编写少量代码就能很容易地定义、训练和使用深度神经网络。
TensorFlow
TensorFlow 是谷歌出品的一款用于机器学习的程序库。我们会在 Keras 上的编程,但 Keras 自己并不会实际使用神经网络逻辑,相反它会在幕后使用谷歌的 TensorFlow 程序库挑起重担。
OK,我们回到挑战中!
创建我们的数据集
不管是训练什么机器学习系统,我们都要有训练数据。要破解一个验证码系统,我们希望能有这样的训练数据:

如图示:输入验证码照片用以训练模型,然后模型能够输出正确的答案。
因为我们有这款 WordPress 插件的源代码,我们可以对其修改保存出 1 万张验证码照片,以及每张照片的预期答案。
在花了几分钟修改代码和添加一个简单的 for 循环后,我获得了一个训练数据文件夹,包含了 1 万张 PNG 照片,每张照片都有正确答案作为照片的文件名:

这是本文唯一一部分没有给出我的工作示例代码的地方,因为我考虑再三后觉得,这篇教程纯粹出于一个好玩的点子,我不希望有人真的用垃圾信息去刷爆 WordPress 网站。但我会在文末提供我上面生成的这1万张照片,大家可以拿去用。
迄今用时:5分钟
将问题简单化
现在,我们已经获取了所需的训练数据,可以用它们直接训练一个神经网络: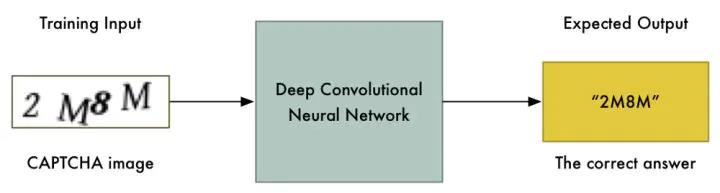
有了足够的训练数据,这种方法应该能凑效了,但我们可以让问题更简单些。问题越简单,解决问题所需的训练数据和计算力就越少。毕竟我们只有 15 分钟啊!!

幸好,这款插件生成的验证码照片都是只有 4 个字,所以我们可以以某种方式将照片分拆,每个字作为一张单独的小照片,这样我们只需训练神经网络每次识别一个单独的字:
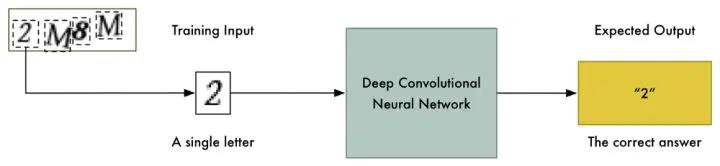
我没时间从头到尾看一遍这 1 万张训练照片,然后用 Photoshop 手动把它们分成单独的照片。这要花好几天功夫,而我只剩下 10 分钟了。我们不能仅仅将照片分成 4 个相同大小的图块,因为验证码为了避免如下情况会随机将字母和数字放在不同的水平位置: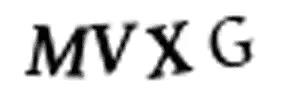
幸运的是,我们依然能将其自动化。在照片处理过程中,我们常常需要检测相同颜色像素的“斑点”(blobs)。围绕这些连续的像素斑点的界线被称为轮廓线。OpenCV 有个内置的findContours()函数,我们可以用它检测这些连续区域。
因此我们以一张原始验证码图像开始:
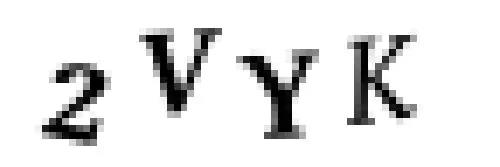
然后我们将其转为纯黑纯白的照片(这步叫做阙值化),这样就能比较容易地发现照片中的连续区域了:
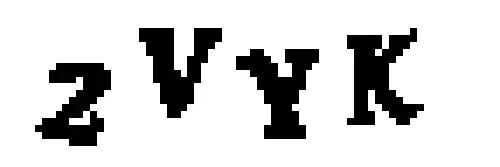
接着,我们用 OpenCV 的 findContours() 函数检测照片的单独部分,它们包含了相同颜色像素的连续斑点:

那么,把每个区域保存为单独的照片文件就是一件比较简单的工作了。因为我们知道每张照片验证码应该自左至右包含 4 个字母,我们可以根据这点在保存这些字的时候给它们打上标签。在按这种顺序保存字母时,我们应该以相应的字母名保存每个字母照片,比如以字母 a 作为照片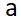 的名字
的名字
但是等等,我发现了一个问题!有时验证码会出现字母重叠的情况,比如这样:
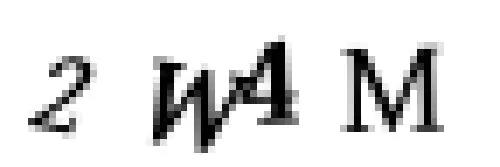
这意味着我们有可能把两个字母提取为一个区域:

如果我们不解决这个问题,我们的训练数据质量会很糟糕。我们需要解决这个麻烦,但额外再教机器将这两个压在一起的字幕识别为一个字母,会比较麻烦。
这里有个简单的技巧,如果一个轮廓线区域的宽度远大于其高度,这意味着可能有两个字母相互重叠了。在这种情况下,我们只需从中间将它们切分,作为两个分开的字母:

现在我们能准确地获取单个字母了,那就把所有的验证码照片过一遍吧。目标是收集每个字母的不同变体。为了容易整理,我们可以将每个字母保存在其自身文件夹内。
比如,下面是我提取所有字母后,字母“W”的文件夹状况:

迄今用时:10分钟
搭建和训练神经网络
因为我们只需识别单个字母和数字,我们不需要用非常复杂的神经网络架构。识别字母比识别阿狗阿猫这样的复杂照片要容易的多。 我们会用到一个简单的卷积神经网络,它有两个卷积层和两个完全相连的层:

如果你想了解更多卷积神经网络工作原理的知识,以及为何它们是用于照片识别理想工具,可以翻阅 Adrian 的书籍《Deep Learning for Computer Vision with Python》。
使用 Keras 只需几行代码就能定义这个神经网络架构:
# 搭建神经网络!
model = Sequential()
# 第一个卷积层并最大池化
model.add(Conv2D(20, (5, 5), padding="same", input_shape=(20, 20, 1), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 第二个卷积层并最大池化
model.add(Conv2D(50, (5, 5), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 包含500个节点的隐藏层
model.add(Flatten())
model.add(Dense(500, activation="relu"))
# 包含32个节点的输出层 (每个节点对应我们预测的可能的字母或数字)
model.add(Dense(32, activation="softmax"))
# 用Keras搭建TensorFlow模型
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
现在可以训练它了!
# 训练神经网络
model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, ver
在用训练数据集训练 10 次后,我们达到了接近 100% 的准确率。这时,我们就能随时自动通过这款工具的验证码了!完成任务!
迄今用时:15分钟(Bingo!)
使用训练后的模型解决填写验证码问题
现在我们有了一个训练后的神经网络,用它破解真正的验证码非常简单:
- 从使用文中这款WordPress插件的网站中抓取一张真正的验证码照片。
- 使用我们在创建训练数据集时所用的方式,将验证码照片分成4个单独的字母照片。
- 让我们的神经网络为每张字母照片做出独立的预测。
- 使用4个预测的字母填写验证码。
- 欢呼吧!
这是我们的模型破解真正的验证码系统时的样子:

或以命令行模式:
自己动手试试吧!
如果你想自己动手尝试,可以点击这里获取代码,包含了本文所用的1万张示例照片和每一步中所有的代码。查看文件夹中的 README.md 文件,获取运行代码的说明。
但是如果你真的想学习每行代码的运行知识,我还是强烈建议你看看《Deep Learning for Computer Vision with Python》这本书,讲了很多细节知识,还有大量的详细示例。这是我迄今看到的唯一一本既讲解了原理又介绍了怎样应用于解决实际问题的书籍,去看看吧!

欢迎关注我们,学习资源,趣味项目,你想看的都在这里!私信“python”
如有疑问,欢迎在评论区一起讨论!
如有不正确的地方,欢迎指导!
以上是关于burpsuite15分钟能破解一个6位验证码吗的主要内容,如果未能解决你的问题,请参考以下文章