Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge(翻译)(
Posted yfqh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge(翻译)(相关的知识,希望对你有一定的参考价值。
摘要:
近年来,机器人自动货仓技术逐步成为焦点,尤其在亚马逊挑战赛(APC). 一个全自动化货仓抓取系统(picking-and-place system)要求robust vision从而能够在复杂环境,自遮挡,传感器噪声以及大量物体的情况下准确的识别放置物体。在这篇文章,我们提出一种利用multi-view RGB-D data, self-supervised, data-driven learning的方法来克服这些困难。
在该方法中,我们通过全卷积网络(fully convolutional neural network)分割和标记场景中多个视角,然后拟合预先扫描的3D模型和分割结果得到6D位姿。训练用于分割的深度学习网络需要大数据量,我们提出自监督方法(self-supervised method)来生成大量带标签的数据集,省去了繁琐的人工分割。我们在多种场景下证明该方法可以可靠地估计6D物体姿态。
I. Introduction
近二十年来,自动货仓技术快速发展,满足了电商的需求,提供了更快、更经济的传送。然而,一些任务仍很难实现自动化。亚马逊致力于解决以下两个任务:1)picking an instance of a given product ID out of a populated shelf and place it into a tote; 2)stowing a tote full of products into a populated shelf.
这篇文章描述了普林斯顿的视觉系统,该系统在2016年亚马逊挑战赛装载和放置任务中分别获得3rd和4rd。该视觉算法可以在具有挑战性的场景下估计6D位姿:
- 复杂环境(Clutter environments)
- 自遮挡(Self-occlusion)
- 数据丢失(Missing data)
- 小物体/形变物体(Small or deformable objects)
- 速度(Speed)
我们的方法精心利用已知约束条件--可能物体和预期背景的列表。首先,通过多视角图(multiple-view images)将物体从场景中分割出来,然后拟合3D model和segmented point cloud得到物体的6D pose。
训练深度神经网络需要大量的标签数据集。我们通过自监督训练自动生成130,000张逐像素标签的图片
论文的主要贡献:
- A robust multi-view vision system to estimate the 6D pose of objects;
- A self-supervised method that trains deep networks by automatically labeling training data;
- A benchmark dataset for estimating object pose
II. 相关工作
机器人操作的视觉算法通常输出2D bounding boxes, pixel-level segmentation, 6D pose.
- 目标分割(Object segmentation) 2015年APC冠军团队使用直方图方向投影方法(histogram backprojection method)手工定义特征。计算机视觉的最新研究表明深度学习大大提高了目标分割的结果。在这项工作中,我们扩展用于图像分割的深度学习网络,使其与深度和多视图信息结合(depth and multi-view information)。
- Pose estimation(位姿估计) 物体位姿估计有两种基本方法。第一种是匹配3D model和3D点云,例如ICP;第二种是利用局部描述子,如SIFT或3DMatch。前者主要与深度传感器一起使用,用于照明显著变化,或无纹理对象等场景。另一方面,高纹理和刚性物体受益于局部描述子。
- 6D位姿估计基准(Benchmark for 6D pose estimate)
III. Amazon Picking Challenge 2016
2016年APC提出一个简易化货仓抓取和集装任务。执行抓取任务时,机器人在货架前一个2*2 平方米的范围内自动抓取12件物品,并将其放置到收纳箱;执行集装任务时,机器人将收纳箱中所有物品放到架子上。
IV.系统描述
视觉系统输入多视角RGB-D图像(RGB-D from multiple views),输出6D pose和a segmented point cloud使机器人完成抓取和集装任务。
 l相机安装在 6DOF工业机器手ABB IRB1600id末端执行器,并且指向尖端(Fig 1)。
l相机安装在 6DOF工业机器手ABB IRB1600id末端执行器,并且指向尖端(Fig 1)。
V.6D Object Pose Estimation
场景中物体位姿估计分两阶段(Fig.2):首先,通过深度学习网络将从多视角获取的RGB-D点云分割为不同的目标;然后,匹配3D模型与分割点云来估计6D pose.

A. Object Segmentation with Fully Convolution Networks
近年来,卷积网络在计算机视觉任务上取得显著进步。我们利用这些方法分割相机数据得到场景中不同物体。明确地说,我们训练一个VGG-FCN网络来实现2D目标分割。输入RGB图像到FCN,输出一组40幅维度与输入图像相同的密集标记像素概率图(densely labeled pixel probability maps)(one for each of the 39 objects and one for the background)
Object segmentation using multiple views(多视角目标分割)
既定目标的单视角信息受杂乱(clutter),自遮挡(self-occlusions)以及不良反射(bad reflections)因素的限制。在模型拟合阶段我们通过多视角信息融合增强物体表面可识别度,从而解决信息损失这一问题。我们将每个视角的RGB图像输入到训练好的FCN,输出40类别的概率图。根据场景中预期目标进行筛选后,我们对概率图设置阈值(高于所有视点平均概率三个标准差),并忽略低于阈值的像素。我们将每个对象类的分割掩膜投影到三维空间,并利用机械臂运动学正反馈将其与分割点云结合。
Reduce noise in point cloud (去除点云噪声)
受噪声影响,直接拟合扫描模型与分割点云结果较差。我们分三个步骤处理这个问题:第一,为降低传感器噪声,通过剔除k邻域内超出阈值的点来消除分割点云的空间离群点;第二,为降低分割噪声,特别是目标边界处,我们剔除收纳箱外的点,以及靠近预扫描模型背景模型的点;第三,进一步通过找出沿主轴的最大的连续点集过滤分割结果的离群点,剔除与该点集不相邻的所有点。
Handle object duplicates (处理对象副本)
仓库通常包含多个同一物体。分割RGB-D数据会将两个具有相同标签的不同物体当成同一物体。我们已知仓库的存货清单以及场景中预期物品。我们利用k-means聚类(k-means clustering)将点云分离成合适数目的种类。在模型拟合分别处理每个分组。
B. 3D Model-fitting (模型拟合)
我们在分割点云上使用迭代最近点(iterative closest point, ICP)算法来拟合预扫描模型,估计姿态。在多种场景下,基础ICP算法产生无意义的结果。针对一些缺陷给出我们的解决方法。
Point clouds with non-uniform density(密度不均匀)
典型的点云,垂直于传感器光轴的表面点云更为稠密;表面颜色改变红外光谱的反射率,这会影响到点云的密度;由于ICP算法更倾向于稠密区域,密度不均匀不利于ICP算法的使用。利用3D均匀平均网格过滤(3D uniform average grid filter)点云,在三维空间得到连续分布。
Pose initialization (初始位姿)
ICP是一种迭代局部最优方法,对初始状态敏感。
为解决这个问题,我们将预扫描模型沿RGB-D相机光轴方向向后移动bounding box的一半作为初始位姿
Coarse to fine ICP(由粗到细ICP)
即使在分割阶段降低噪声,其结果中仍可能存在噪声。我们通过在点云不同子集上进行两次ICP解决这一问题:将ICP迭代的iterative threshold定义为L2距离的百分率,忽略超出部分。第一次90%;第二次45%
C. Handling Objetcs with Missing Depth
APC 很多物体(零售仓库的典型物体)的表面会对基于红外深度传感器造成困难。如塑料包装会返回噪声或者多重反射,或者透明,网格塑料可能无法注册。这些物体采集到的点云有噪声,且稀疏,位姿估计的方法表现很差。
我们利用多视角分割技术(multi-view segmentation)对分割后的RGB-D图像进行体素三维网格化,估计一个物体的凸包。这个过程产生一个封装真实物体的3D掩膜。我们利用这个凸包来估计物体的几何中心和方向(假设物体是轴对齐的)
VI. Self-supervised Training (自监督训练)
深度学习提高了本方法的鲁棒性。但是,却需要大量的训练集去学习模型的参数。收集和人工标注这些数据集代价很大。现有的用于深度学习的大规模数据集大多是网络图片,这与仓库不同。
为了自动获取和逐像素标注图片,我们基于三个观察提出自监督方法(self-supervised method):
- 对场景中单一物体的批训练产生的deep model可以在多物体下表现良好
- 准确的机械臂和相机标定可以使我们任意控制相机视点
- 已知背景和相机视点的单一物体场景下,我们可以通过前景掩膜自动获取精确的分割
获取的训练集包含39中物体,136,575 RGB-D图像,均是自动标注。
Semi-automatic data gathering
为了半自动获取大量的训练数据,我们以任意姿态将单一已知物体放入架子或收纳箱内,控制机器人移动相机,获得不同视角的RGB-D图像。架子/收纳箱的位置和相机视点对机器人是已知。获取几百张RGB-D图像后,人工重置物体的姿态,并重复几次这个过程。
Automatic data labeling
为得到像素级目标分割标签,我们创建一个object mask将前景从背景中分离出来。整个过程由2D pipeline和3D pipeline组成(Fig. 5)。2D pipeline对薄的以及没有深度信息的物体鲁棒,3D pipeline对未对准的大物体鲁棒。结合两个通道的结果自动标注object mask。
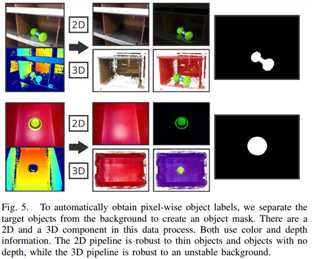
2D通道开始以多模态2D配准来对齐两幅RGB-D图像,以修复可能存在的图像错位。然后将对齐的彩色图像从RGB转换为HSV,逐像素对比HSV和深度通道来分离并标注前景。
3D通道通过多视角来创建预扫面3D model。然后利用ICP算法匹配训练图像和
Training neural network
利用在大数据集上训练得到的特征:
- use the sizable FCN-VGG network architecture
- initialize the network weights using a model pre-trained on ImageNet for 1000-way object classification
- fine-tune the network over the 40-class output classifier (39 classes for each APC object and 1 class for background) using stochastic gradient desent with momentum.
训练两个分割网络(one for shelf bins and one for tote)来最优化
VII. Implementation
视觉系统的所有部件被模块化到reusable ROS packages,
CUDA GPU acceleration
deep models are trained and tested with Marvin
training our models takes up to 16 hours prior to convergence
Our robot is controlled by a computer with an Intel E3-1241 CPU 2.5 GHz and an NVIDIA GTX 1080. The run-time speeds per component are as follows:
- 10ms for ROS communication overhead
- 400ms per forward pass of VGG-FCN
- 1200ms for denoising per scene
- 800ms on model-fitting per object
- pose estimation time is 3-5 seconds per shelf bin and 8-15 seconds for the tote
Combined with multi-view robot motions, total vision perception time is 10-15 seconds per shelf bin and 15-20 seconds for the tote
VIII. Evaluation
我们在基准数据集上对不同场景下方法的变体进行评估来理解两个问题(1)在不同输入模态和训练数据集大小下分割表现如何(2)整个视觉系统表现如何
A. Benchmark Dataset
我们的基准数据集“Shelf$Tote”, 包含477个场景下多于7,000 分辨率为640×480 RGB-D图像(Fig. 6)。我们在APC的练习赛和决赛中收集数据,通过在线注释器手动标注6D物体位姿和分割(Fig. 7)。数据反映出多个仓库的困难:杂乱场景下的可反射材料,光照条件变化,局部视图以及传感器限制(噪声和深度损失)


表1和表2总结了实验结果,并强调不同覆盖场景下的不同表现:
- cptn: during competition at the APC finals
- environment: in an office (off); in the APC competition warehouse (whs)
- task: picking from a shelf bin or stowing from a tote
- clutter: with multiple objects
- occlusion: with % of object occluded by another objetc, computed from ground truth
- object peoperties: with objects that are deformable, thin, or have no depth from the RealSense F200 camera
B. Evaluating Object Segmentation
我们测试用于目标分割FCN的几个变体来回答两个问题:(1)是否可以同时利用颜色和深度分割?(2)更多的训练数据是否更有效?
Metrics
利用逐像素精度和召回率,比较FCNs预测的分割结果和ground truth分割标签。 表I显示平均F-scores 。
Depth for segmentation
我们利用HHA feature将深度信息分成三个通道:水平视差、地面高度、重力方向与表面法向夹角。 比较此条件下训练AlexNet和VGG on RGB data, 以及二者结合结果。
我们发现,加入深度信息并没有显著提升分割结果,部分原因可能是由于传感器获取的深度信息含有噪声。另一方面,我们观察到FCN在color data训练时表现更好。
Size of training data
深度学习模型取得了明显成功,特别是给出大量训练数据时。然而,物体类别很少时的实例分割,如此大的数据集是否必要。我们随机采样1%和10%的数据建立两个新的数据集,并用它们训练两个 VGG-FCN。我们可以看到,当训练数据基准类别逐步提升时,F-scores显著提升。
C. Evaluating Pose Estimation
我们验证视觉系统几个关键部件是否可以提升性能。
Metrics
Multi-view information
多视角技术使系统克服了自遮挡,其他物体遮挡以及杂乱带来的信息损失。多视角信息缓解了可反射表面的照明问题。
为验证多视角的有效性,我们在基准及上对整个视觉系统进行测试:
- [Full] All 15 views for bins a1shelf ={0...14} and all 18 views for the tote a1tote={0...17}
- [5v-10v] 5 views for shelf a2shelf ={0,4,7,10,14} and 10 for the tote a2tote={0,2,4,6,8,9,11,13,15,17}, with a sparse arrangement and a preference for wide-baseline view angles.
- [1v-2v] 1 view for shelf bins a3 shelf={7} and 2 views for the tote a3 tote={7,13}
结果表明多视角技术可以鲁棒地处理仓库的遮挡和杂乱问题(Table II [clutter] and [occlusion])。
Denosing
Part V 的去噪可以很好地提升性能。去掉这一步骤,平移和旋转地精度分别下降6.0%和4.4%。
ICP algorithm
没有这一预处理过程,平移和旋转精度分别下降0.9%和3.1%。
Performance upper bound
D. Common Failure Models
我们总结了系统中最多的错误模型。
- The FCN segmentation for objects under heavy occkusion or clutter are likely to be incomplete resulting in poor pose estimation (Fig. 8. e), or undetected (Fig. 9.m and p). This happens with more frequency at back of the bin with poor illumination.
- Objects color textures are confused with each other. Figure 9.r shows a Dove bar (white box) on top of a yellow Scotch mail envelope, which combined have a similar appearance to the outlet plugs.
- Model fitting for cuboid objects often confuses corner alignments (marker boxes in Fig. 9.o). This inaccuracy, however, is still within the range of tolerance that the robot can tolerance thanks to sensor-guarded motions.
Filtering failure modes by confidence score
IX. Discussion
两个可能提升系统结果的observations:
Make the most out of every constraint
Designing robotic and vision systems hand-in-hand
以上是关于Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge(翻译)(的主要内容,如果未能解决你的问题,请参考以下文章