ThingJS官方示例(十一):大数据矢量及贴图url开发OD线
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThingJS官方示例(十一):大数据矢量及贴图url开发OD线相关的知识,希望对你有一定的参考价值。
参考技术A #前端# #三维可视化# #OD线开发#1. 基础图层创建
2. OD线创建(矢量与贴图)
3. 大数据量对接
简介:数字孪生体已经从制造领域逐步延伸拓展至城市空间,数字孪生城市又比工业制造复杂得多,与物理城市相对应。做不到100%逼真,而是构建统一的城市信息模型,让数字城市和现实城市进行“虚实结合”!3D城市动态模型包含点、线、面等地理要素,组合成信息化数字地图,有助于提升城市规划、建筑、交通、能源等领域的数字化水平。
Demo链接: http://www.thingjs.com/guide/?m=sample
OD线 (Origin-Destination Line) 指的是起点和终点的连线,用于表示两点之间的某种关系,如航班线路、人口迁徙、交通流量、经济往来等。从本周起中国缓慢进入春运高峰期,堪称一次爆发式人口迁徙事件,春运迁徙地图通常使用OD线表示:
迁入来源地,OD线汇聚到一个方向,比如海口市,作为人口迁入的终点位置。
迁出目的地,OD线扩散到不同方向,但是起点是同一个位置,比如人口从哈尔滨市迁出。
GeoLine是带有地理位置的线要素,可以添加属性字段来存储其他信息,可以分为三种不同的线条类型,OD线不同在于限制了起点和终点,GIS里面就能够形成,绘制三维OD线需要哪些注意事项?创建OD线与其他线条有何区别?
这里详解OD线开发步骤,体验见demo: http://www.thingjs.com/guide/?m=sample
动态加载地球组件之后,获取不同图层叠加,在ThingLayer业务图层进行更灵活的二次开发。创建一个ThingLayer图层,并将ThingLayer添加到底图中,获取起点的坐标位置startPos,展示由点及面的向外扩散效果。
var startPos = [116.39139175415039, 39.906082185995366];
ThingJS渲染器提供两种渲染类型,矢量渲染vector以及贴图渲染image;获取OD线先从ThingJS图层中查询迁徙路径,如北京-济南,接下来就这条路径做样式修改。
渲染器renderer设置Vector矢量线的颜色,示例显示rgb数组【255,0,0】的使用方法,还可以使用rgb字符串“rgb (255,0,0)”、十六进制字符串"#ff0000"。
流动效果速度默认为0,静止效果;数值可正可负,代表正反两种流动方向,贴图样式也同样适用。
renderer:
lineType: 'Line',
type: 'vector', // 代表纯色渲染
color: [255, 0, 0],
// opacity:0.2 ,// 设置不透明度 默认是1
// speed: 1 ,// 流动效果速度, 默认是0 不流动;speed 可正可负,正负代表流动方向
// effect: true // 线发光效果 默认为 false 不开启
);
获取url来生成贴图类型的OD线,颜色及其他样式是贴图本身所具备的,通过修改贴图通道叠加数numPass来扩充线宽度,一般来说该数值越大,线越亮。
利用effect函数开启线发光特效,在地图上起到重要的强调作用。
renderer:
lineType: 'Line',
type: 'image', // 代表贴图渲染
imageUrl: '/guide/image/uGeo/path.png',
numPass: 3,
speed: 0.5, // 流动效果速度, 默认是0 不流动;speed 可正可负,正负代表流动方向
// effect: true // 线发光效果 默认为 false 不开启
值得注意的是,大数据量的OD线一般需要浏览器端渲染至少几十万或上百万以上,不管数据传输还是数据渲染都需要采取更高效的方式—— ThingJS平台 提供生成动态大数据的接口,利用WebSocket(百万量级), MQTT(单机千万级)数据接口实现流畅的双工通信,配合前端SDK轻松在线开发!
ThingJS提供物联网3D可视化组件,让3D开发更轻松!直接javascript调用3D脚本,基于200个3D开发源码示例,让你全面了解物联网可视化开发逻辑。利用场景搭建-3D脚本开发-数据对接-项目部署的一站式服务让开发更高效,与20万个开发者一同成为数字孪生技术创新者!
Hadoop MapReduce介绍官方示例及执行流程
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家一起来开始学Spark!
▼往期内容汇总:
- 大数据导论
- Linux操作系统概述
- VMware Workstation虚拟机使用
- Linux常用基础命令、系统命令
- Apache Hadoop概述
- Apache Hadoop集群搭建
- HDFS分布式文件系统基础
- Hadoop技术之HDFS shell操作
- Hadoop技术之HDFS工作流程与机制
一、理解MapReduce思想
- MapReduce的思想核心是“先分再合,分而治之”。
- 所谓 “分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果, 然后把各部分的结果组成整个问题的最终结果。
- 这种思想来源于日常生活与工作时的经验。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。

- Map表示第一阶段,负责“拆分”:即把复杂的任务分解为若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reduce表示第二阶段,负责“合并”:即对map阶段的结果进行全局汇总。
- 这两个阶段合起来正是MapReduce思想的体现。

一个比较形象的语言解释MapReduce
要数停车场中的所有停放车的总数量。
你数第一列,我数第二列 …这就是Map阶段, 人越多,能够同时数车的人就越多,速度就越快。
数完之后,聚到一起,把所有人的统计数加在一起。这就是Reduce合并汇总阶段。

二、Hadoop MapReduce设计构思
(1)如何对付大数据处理场景
对相互间不具有计算依赖关系的大数据计算任务,实现并行最自然的办法就是采取MapReduce分而治之的策略。
首先Map阶段进行拆分, 把大数据拆分成若干份小数据,多个程序同时并行计算产生中间结果;然后是Reduce聚合阶段,通过程序对并行的结果进行最终的汇总计算,得出最终的结果。
不可拆分的计算任务或相互间有依赖关系的数据无法进行并行计算!

(3)构建抽象编程模型
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。 map: 对一组数据元素进行某种重复式的处理;
reduce: 对Map的中间结果进行某种进一步的结果整理。

- MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → (k2; v2)
reduce: (k2; [v2]) → (k3; v3)
- 通过以上两个编程接口, 大家可以看出MapReduce处理的数据类型是<key,value>键值对。
( 3)统一架构、隐藏底层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此, MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层 面的处理细节。
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(howtodo)分开了,为程序员提供一个抽象和高层的编程接口和框架。
程序员仅需要关心其应用层的具体计算问题, 仅需编写少量的处理应用本身计算问题的业务程序代码。
至于如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
三、 Hadoop MapReduce介绍
分布式计算概念
分布式计算是一种计算方法,和集中式计算是相对的。
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。
分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
MapReduce介绍
Hadoop MapReduce是一个分布式计算框架,用于轻松编写分布式应用程序, 这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点) 上的大量数据(多TB数据集)。
MapReduce是一种面向海量数据处理的一种指导思想,也是一种用于对大规模数据进行分布式计算的编程模型。

MapReduce产生背景
MapReduce最早由Google于2004年在一篇名为《MapReduce:Simplified Data Processingon Large Clusters》的论文中提出。
论文中谷歌把分布式数据处理的过程拆分为Map和Reduce两个操作函数(受到函数式编程语言的启发), 随后被Apache Hadoop参考并作为开源版本提供支持,叫做Hadoop MapReduce。
它的出现解决了人们在最初面临海量数据束手无策的问题, 同时它还是易于使用和高度可扩展的,使得开发者无需关系分布式系统底层的复杂性即可很容易的编写分布式数据处理程序,并在成千上万台普通的商用服务器中运行。

MapReduce特点
- 易于编程
Mapreduce框架提供了用于二次开发的接口; 简单地实现一些接口,就可以完成一个分布式程序。任务计算交给计算 框架去处理,将分布式程序部署到hadoop集群上运行,集群节点可以扩展到成百上千个等。
- 良好的扩展性
当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算能力。基于MapReduce的分布式计算得特点可 以随节点数目增长保持近似于线性的增长,这个特点是MapReduce处理海量数据的关键,通过将计算节点增至几百或 者几千可以很容易地处理数百TB甚至PB级别的离线数据。
MapReduce特点
- 高容错性
Hadoop集群是分布式搭建和部署得,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行, 不影响整个作业任务得完成,过程完全是由Hadoop内部完成的。
- 适合海量数据的离线处理
可以处理GB、TB和PB级别得数据量
MapReduce局限性
MapReduce虽然有很多的优势,也有相对得局限性, 局限性不代表不能做,而是在有些场景下实现的效果比较差,并 不适合用MapReduce来处理,主要表现在以下结果方面:
- 实时计算性能差
MapReduce主要应用于离线作业,无法作到秒级或者是亚秒级得数据响应。
- 不能进行流式计算
流式计算特点是数据是源源不断得计算,并且数据是动态的;而MapReduce作为一个离线计算框架,主要是针对静态 数据集得,数据是不能动态变化得。
MapReduce实例进程
- 一个完整的MapReduce程序在分布式运行时有三类
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程

阶段组成
一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段;
不能有诸如多个map阶段、多个reduce阶段的情景出现;
如果用户的业务逻辑非常复杂, 那就只能多个MapReduce程序串行运行。

MapReduce数据类型
注意: 整个MapReduce程序中,数据都是以kv键值对的形式流转的;
在实际编程解决各种业务问题中,需要考虑每个阶段的输入输出kv分别是什么;
MapReduce内置了很多默认属性,比如排序、分组等,都和数据的k有关,所以说kv的类型数据确定及其重要的;

四、Hadoop MapReduce官方示例
概述
一个最终完整版本的MR程序需要用户编写的代码和Hadoop自己实现的代码整合在一起才可以;
其中用户负责map、 reduce两个阶段的业务问题, Hadoop负责底层所有的技术问题;
由于MapReduce计算引擎天生的弊端(慢) ,当下企业中直接使用率已经日薄西山了,所以在企业中工作很少涉及到MapReduce直接编程,但是某些软件的背后还依赖MapReduce引擎。
可以通过官方提供的示例来感受MapReduce及其内部执行流程, 因为后续的新的计算引擎比如Spark,当中就有MapReduce深深的影子存在。
示例说明
- 示例程序路径: /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
- 示例程序: hadoop-mapreduce-examples-3.3.0.jar
- MapReduce程序提交命令: [hadoop jar|yarn jar] hadoop-mapreduce-examples-3.3.0.jar args… 提交到哪里去?
- 提交到YARN集群上分布式执行。

评估圆周率π ( PI)的值
- 运行MapReduce程序评估一下圆周率的值, 执行中可以去YARN页面上观察程序的执行的情况。
第一个参数: pi表示MapReduce程序执行圆周率计算任务;
第二个参数:用于指定map阶段运行的任务task次数, 并发度, 这里是10;
第三个参数:用于指定每个map任务取样的个数,这里是50。

评估圆周率π ( PI)的值

WordCount概述
WordCount算是大数据计算领域经典的入门案例, 相当于Hello World。
虽然WordCount业务极其简单,但是希望能够通过案例感受背后MapReduce的执行流程和默认的行为机制,这才是关键。

WordCount编程实现思路
map阶段的核心:把输入的数据经过切割,全部标记1, 因此输出就是<单词, 1>。
shuffle阶段核心: 经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对。
reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。 对所有的1进行累加求和,就是单词的总次。

WordCount程序提交
- 上传课程资料中的文本文件1.txt到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建 hadoop fs -mkdir /input
hadoop fs -put 1.txt /input
- 准备好之后,执行官方MapReduce实例,对上述文件进行单词次数统计
第一个参数: wordcount表示执行单词统计任务;
第二个参数:指定输入文件的路径;
第三个参数:指定输出结果的路径(该路径不能已存在);

WordCount执行结果

五、 Map阶段执行流程
WordCount执行流程图

MapReduce整体执行流程图
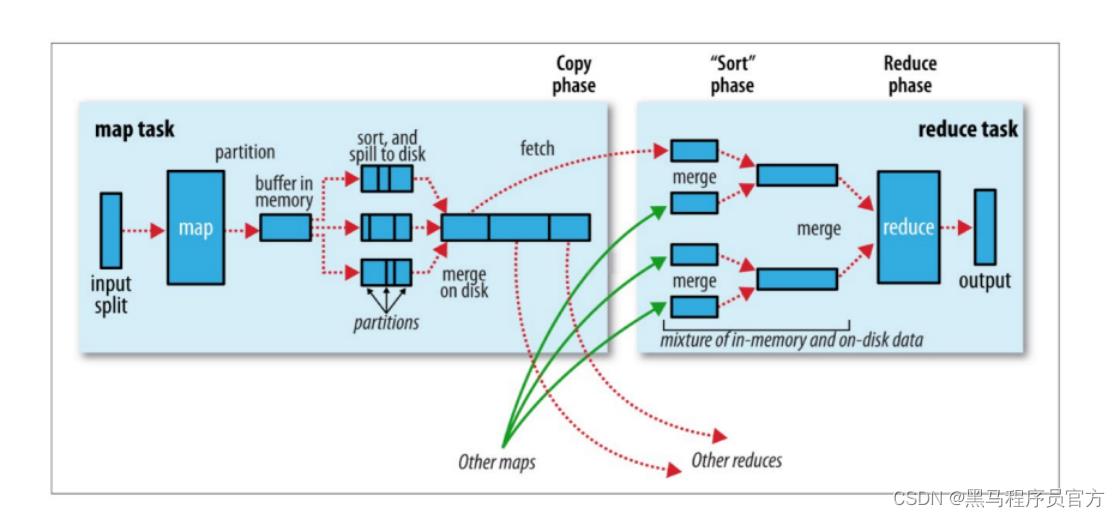
Map阶段执行过程
第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片, 形成切片规划。
默认Split size = Block size ( 128M) ,每一个切片由一个MapTask处理。(getSplits)
第二阶段:对切片中的数据按照一定的规则读取解析返回<key,value>对。
默认是按行读取数据。 key是每一行的起始位置偏移量, value是本行的文本内容。(TextInputFormat)
第三阶段:调用Mapper类中的map方法处理数据。每读取解析出来的一个<key,value>, 调用一次map方法。

Map阶段执行过程
第四阶段:按照一定的规则对Map输出的键值对进行分区partition。默认不分区,因为只有一个reducetask。 分区的数量就是reducetask运行的数量。
第五阶段: Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。
默认根据key字典序排序。
第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件。

六、Reduce阶段执行流程
WordCount执行流程图

MapReduce整体执行流程图
Reduce阶段执行过程
- 第一阶段: ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
- 第二阶段:把拉取来数据,全部进行合并merge, 即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。 最后把这些输出的键值对写入到HDFS文件中。

七、Shuffle机制
shuffle概念
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
而在MapReduce中, Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
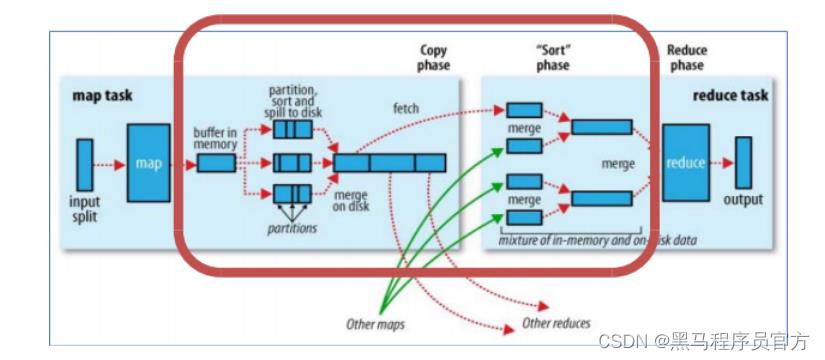
Map端Shuffle
Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算,默认Hash分区。
Spill阶段:当内存中的数据量达到一定的阀值的时候, 就会将数据写入本地磁盘, 在将数据写入磁盘之前需要对数据进行一次排序的操作, 如果配置了combiner,还会将有相同分区号和key的数据进行排序。
Merge阶段:把所有溢出的临时文件进行一次合并操作, 以确保一个MapTask最终只产生一个中间数据文件。

Reducer端shuffle
- Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时, 会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。

shuffle机制弊端
- Shuffle是MapReduce程序的核心与精髓, 是MapReduce的灵魂所在。
- Shuffle也是MapReduce被诟病最多的地方所在。 MapReduce相比较于Spark、 Flink计算引擎慢的原因, 跟Shuffle机制有很大的关系。
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
以上是关于ThingJS官方示例(十一):大数据矢量及贴图url开发OD线的主要内容,如果未能解决你的问题,请参考以下文章