Kubernetes组件_Scheduler_02_二次调度
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes组件_Scheduler_02_二次调度相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
Descheduler所有资料:https://www.syjshare.com/res/V2RS2PUM
二、二次调度/运行期间调度Descheduler
2.1 机器上安装helm


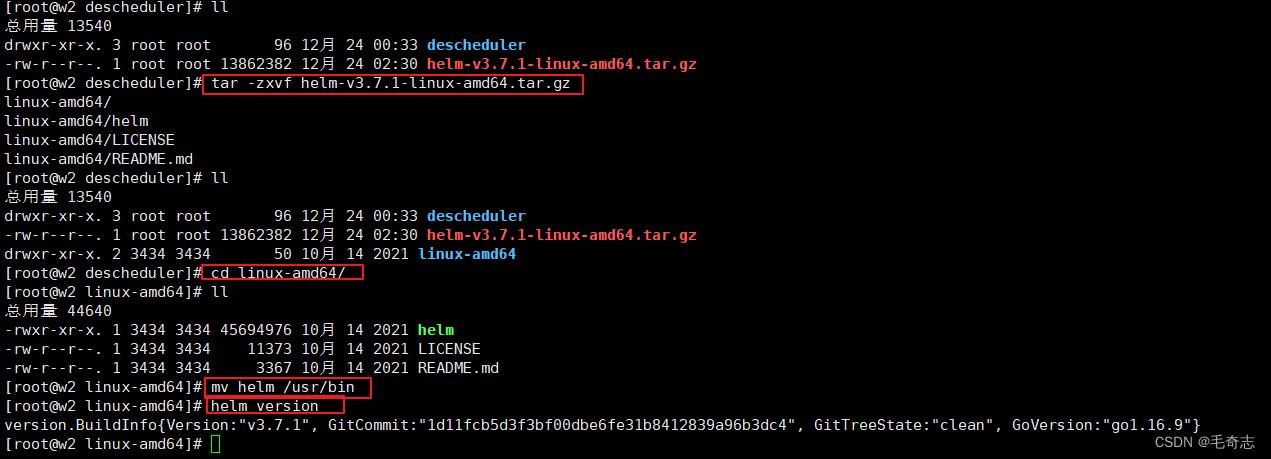
小结精简命令:
1.helm包下载地址:
wget https://get.helm.sh/helm-v3.7.1-linux-amd64.tar.gz
2.解压 && 移动到 /usr/bin 目录下:
tar -xvf helm-v3.7.1-linux-amd64.tar.gz && cd linux-amd64/ && mv helm /usr/bin
3.执行 helm 显示如下说明安装成功:
#查看版本
helm version
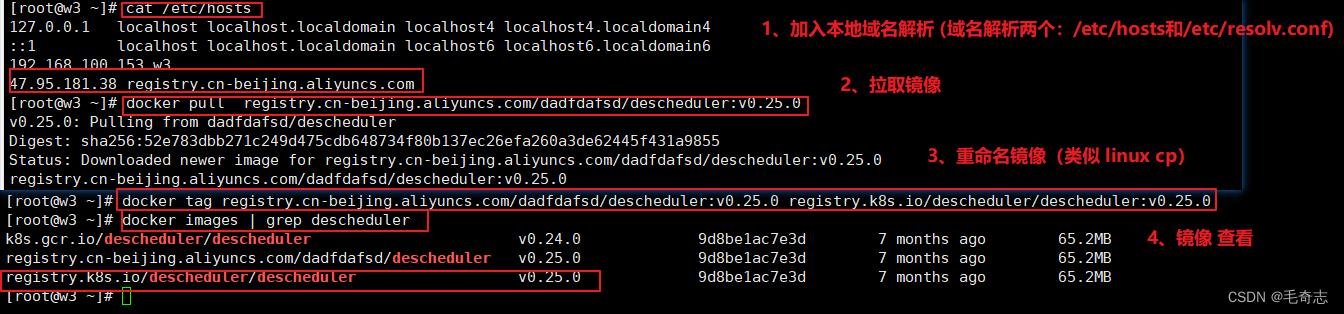
2.2 每个机器都要准备好镜像
每个机器都要准备好镜像

这里笔者将镜像放到自己的阿里云镜像仓库,并公开权限,读者只需要下载就好了
vi /etc/hosts
47.95.181.38 registry.cn-beijing.aliyuncs.com
docker pull registry.cn-beijing.aliyuncs.com/dadfdafsd/descheduler:v0.25.0
docker tag registry.cn-beijing.aliyuncs.com/dadfdafsd/descheduler:v0.25.0 registry.k8s.io/descheduler/descheduler:v0.25.0
docker images | grep descheduler
2.3 使用helm部署
descheduler-master的源代码也有,需要的那个上面提供了,镜像无法修改源代码,这里打成这个镜像的压缩包也有

helm install releaseName mychartName
helm install descheduler descheduler ( 第一个 descheduler 是helm对象名,第二个descheduler 是mychart名称,也就是目录名)
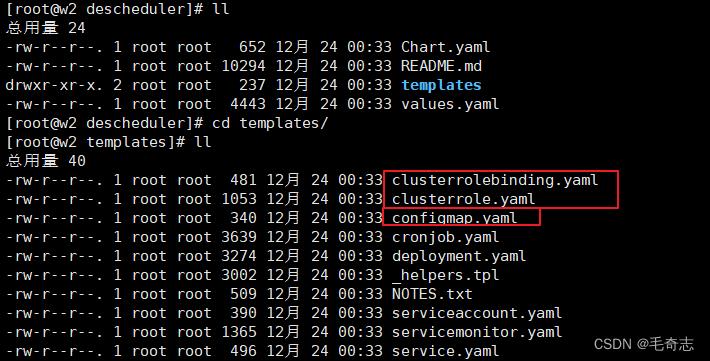
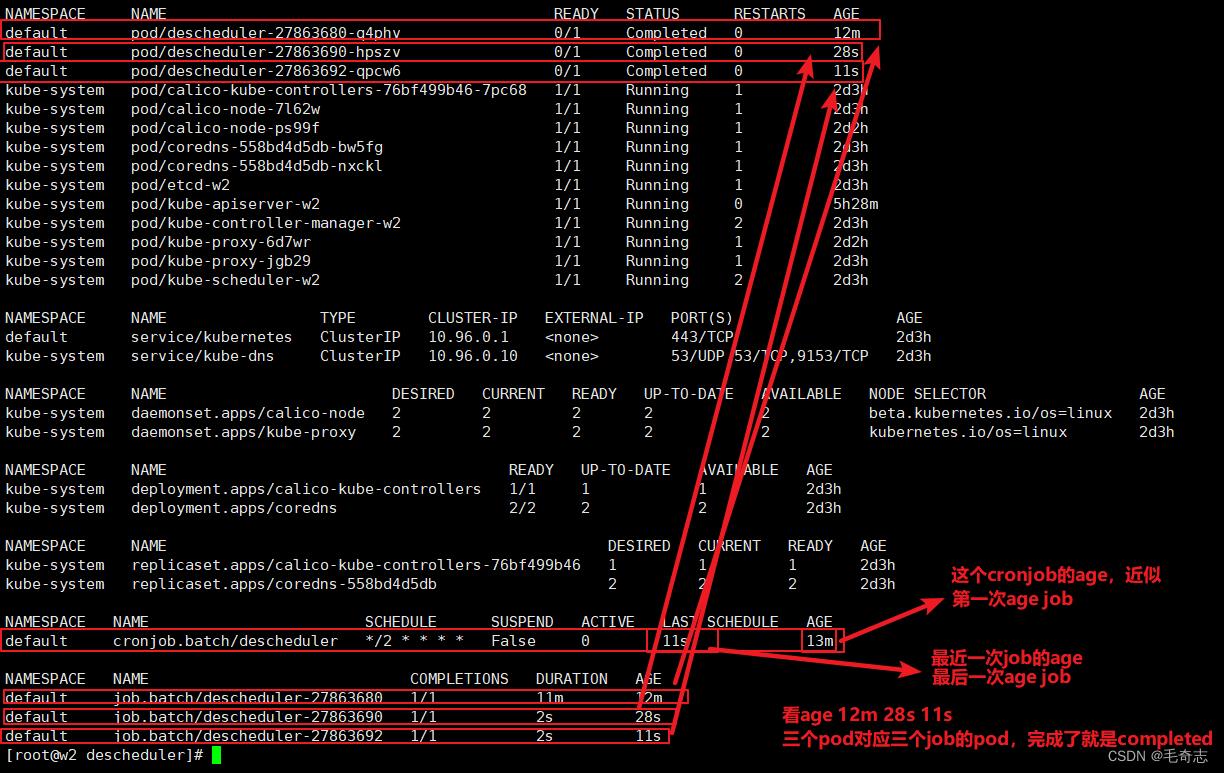
kubectl get all -A
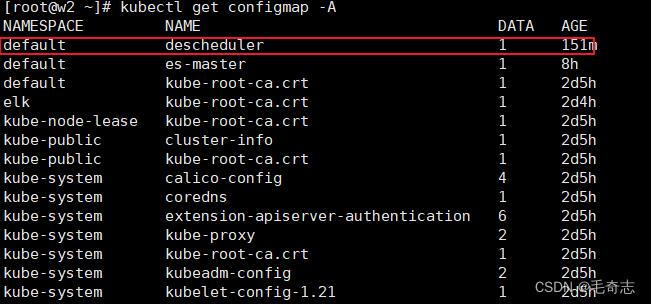
kubectl get configmap -A
kubectl get clusterrole -A
kubectl get clusterrolebinding -A
查询kubectl get all -A,如下:


k8s中,查看机器硬件使用情况的两条命令
# 查看集群所有机器的硬件资源使用情况 (这个top命令必须安装metrics-server才能使用)
kubectl top nodes
# 查看集群内指定机器的硬件资源使用情况 (一般还是使用这个,describe node命令没有限制)
kubectl describe node xxx
三、Descheduler需要注意的点(相关理论知识)
3.1 descheduler 调度策略
descheduler 调度策略:为了方便理解,可以类比apiserver的审计策略,表示哪些日志应该打印,这里表示那种情况需要被重调度。
查看官方仓库推荐的默认策略配置:
cat kubernetes/base/configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: descheduler-policy-configmap
namespace: kube-system
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: true
"RemovePodsViolatingInterPodAntiAffinity":
enabled: true
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
默认开启了 RemoveDuplicates、RemovePodsViolatingInterPodAntiAffinity、LowNodeUtilization 策略。我们可以根据实际场景需要进行配置。
descheduler 目前提供了如下几种调度策略:
-
RemoveDuplicates
驱逐同一个节点上的多 Pod -
LowNodeUtilization
查找低负载节点,从其他节点上驱逐 Pod -
HighNodeUtilization
查找高负载节点,驱逐上面的 Pod -
RemovePodsViolatingInterPodAntiAffinity
驱逐违反 Pod 反亲和性的 Pod -
RemovePodsViolatingNodeAffinity
驱逐违反 Node 反亲和性的 Pod -
RemovePodsViolatingNodeTaints
违反 NoSchedule 污点的 Pod -
RemovePodsViolatingTopologySpreadConstraint
驱逐违反拓扑域的 Pod -
RemovePodsHavingTooManyRestarts
驱逐重启次数太多的 Pod -
PodLifeTime
驱逐运行时间超过指定时间的 Pod -
RemoveFailedPods
驱逐失败状态的 Pod
3.2 descheduler 有哪些不足
3.2.1 基于 Request 计算节点负载并不能反映真实情况
在源码 https://github.com/kubernetes-sigs/descheduler/blob/028f205e8ccc49440bd52940eb78a737f8f5b824/pkg/descheduler/node/node.go#L253 中可以看到,descheduler 是通过合计 Node 上 Pod 的 Request 值来计算使用情况的。
这种方式可能并不太适合真实场景。如果能直接拿 metrics-server 或者 Prometheus 中的数据,会更有意义,因为很多情况下 Request、Limit 设置都不准确。有时,为了节约成本提高部署密度,Request 甚至会设置为 50m,甚至 10m。
3.2.2 驱逐 Pod 导致应用不稳定
descheduler 通过策略计算出一系列符合要求的 Pod,进行驱逐。好的方面是,descheduler 不会驱逐没有副本控制器的 Pod,不会驱逐带本地存储的 Pod 等,保障在驱逐时,不会导致应用故障。但是使用 client.PolicyV1beta1().Evictions 驱逐 Pod 时,会先删掉 Pod 再重新启动,而不是滚动更新。
在一个短暂的时间内,在集群上可能没有 Pod 就绪,或者因为故障新的 Pod 起不来,服务就会报错,有很多细节参数需要调整。
3.2.3 依赖于 Kubernetes 的调度策略
descheduler 并没有实现调度器,而是依赖于 Kubernetes 的调度器。这也意味着,descheduler 能做的事情只是驱逐 Pod,让 Pod 重新走一遍调度流程。如果节点数量很少,descheduler 可能会频繁的驱逐 Pod。
3.3 descheduler 有哪些适用场景
descheduler 的视角在于动态,其中包括两个方面:Node 和 Pod。Node 动态的含义在于,Node 的标签、污点、配置、数量等发生变化时。Pod 动态的含义在于,Pod 在 Node 上的分布等。
根据这些动态特征,可以归纳出如下适用场景:
(1) 新增了节点
(2) 节点重启之后
(3) 修改节点拓扑域、污点之后,希望存量的 Pod 也能满足拓扑域、污点
(4) Pod 没有均衡分布在不同节点
三、尾声
一般用不到,知道这个东西,会用,能跑起来就好,helm工程给出了,镜像也可以docker pull 到。
以上是关于Kubernetes组件_Scheduler_02_二次调度的主要内容,如果未能解决你的问题,请参考以下文章