提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件相关的知识,希望对你有一定的参考价值。
11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解开发套件,旨在为企业级开发者提供更领先、高效、易用的 ERNIE 应用服务,全面释放 ERNIE 的工业化价值,其中包含 ERNIE 轻量级解决方案,提速 1000倍!
今年 7 月,百度发布持续学习语义理解框架 ERNIE 2.0,在共计 16 个中英文任务上超越BERT、XLNET,取得了 SOTA 的效果。
ERNIE2.0 发布以来,ERNIE 产业化应用进程不断加速,易用性不断提升,配套产品也不断丰富和完善。目前,ERNIE2.0 在百度内部及行业内已取得了广泛应用,在多种场景下都取得了明显效果提升。这些场景的成功运用为 ERNIE 产业化应用积累了丰富的经验。

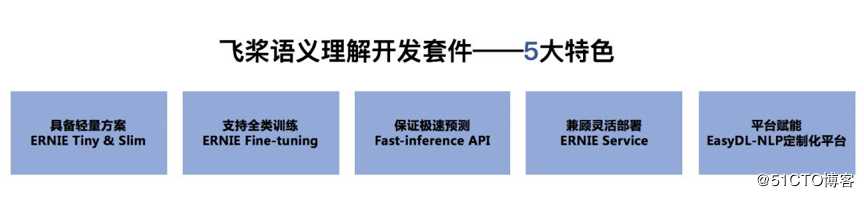
上图为 ERNIE 全景图,预置了包含 ERNIE 通用模型、ERNIE 任务模型、ERNIE 领域模型以及本次发布的 ERNIE Tiny 轻量级模型等系列预训练模型。在此基础上,构建了包含工具和平台的飞桨语义理解开发套件。全面覆盖了训练、调优、部署等开发流程,具备轻量方案、能力全面、极速预测、部署灵活、平台赋能等五大特色。接下来,我们逐一揭秘。
特色1:轻量级解决方案,预测速度提升 1000 倍
ERNIE 2.0 拥有强大的语义理解能力,而这些能力需要强大的算力才能充分发挥,这为实际应用带来了非常大的挑战。为此,百度发布轻量级预训练模型 ERNIE Tiny 以及一键式数据蒸馏工具 ERNIE Slim,预测速度提升达到 1000 倍。
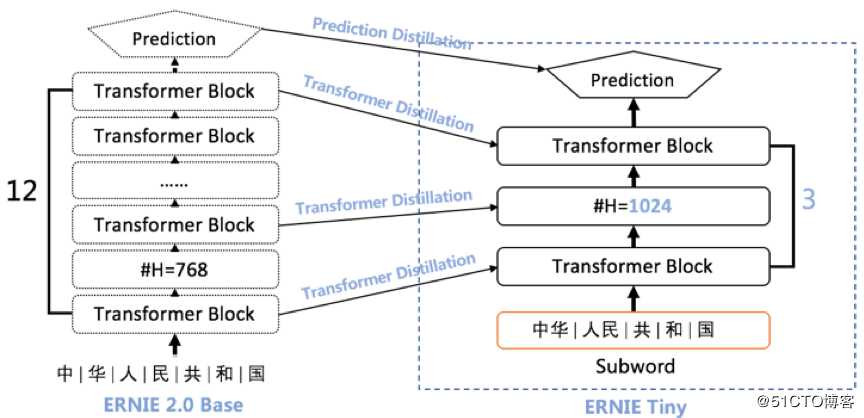
ERNIE Tiny 技术原理
ERNIE Tiny 主要通过模型结构压缩和模型蒸馏的方法,将 ERNIE 2.0 Base 模型进行压缩,其特点和优势主要包括以下四个方面:
? 浅:模型采用 3 层 Transformer 结构,线性提速 4 倍;
? 宽:模型加宽隐层参数,从 ERNIE 2.0 的 768 扩展到 1024,宽度的增加带来效果的提升 。依托飞桨的通用矩阵运算优化,『变宽』并不会带来速度线性的下降;
? 短:为缩短输入文本的序列长度,降低计算复杂度,模型首次采用中文 Subword 粒度输入,长度平均缩短 40%;
? 萃:ERNIE Tiny 在训练中扮演学生角色,利用模型蒸馏的方式在 Transformer 层和Prediction 层学习教师模型 ERNIE 2.0 模型对应层的分布和输出。
通过以上四个方面的压缩,ERNIE Tiny 模型的效果相对于 ERNIE 2.0 Base 平均只下降了2.37%,但相对于『SOTA Before BERT』提升了 8.35%,而速度提升了 4.3 倍。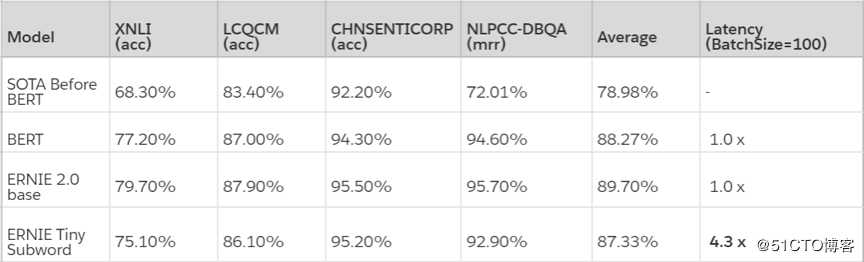
ERNIE Tiny 的预测速度在一些性能要求苛刻的场景中是不够的,这些场景中延迟响应往往要求小于 1ms,为此,套件提供了一键式数据蒸馏 ERNIE Slim 工具。该工具以数据为桥梁,将 ERNIE 的知识迁移至小模型,在效果损失很小的情况下实现预测速度上千倍的提升。
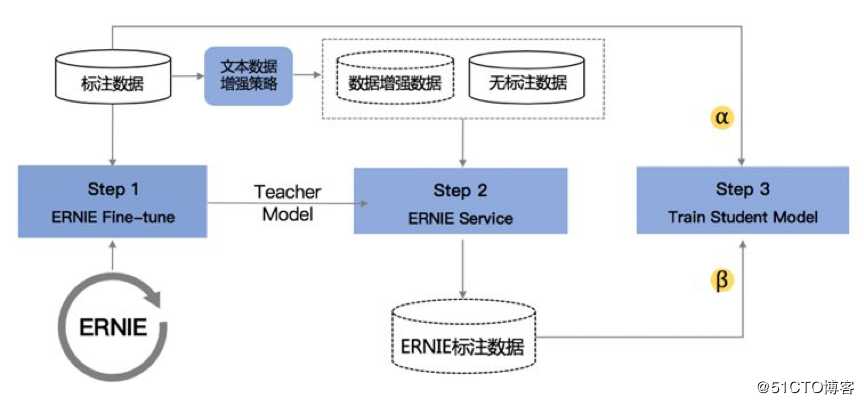
ERNIE Slim 技术原理
ERNIE Slim 原理同传统深度学习数据蒸馏的方法略有不同。首先需要使用 ERNIE 2.0 模型对输入标注数据对进行 Fine-tune 得到 Teacher Model,然后使用 Teacher Model 对无标注数据进行预测,该步骤中我们可采用添加噪声词、同词性词语替换、N-sampling 三种策略进行数据增强,最后通过 BoW、CNN 等计算复杂度小的模型进行训练。
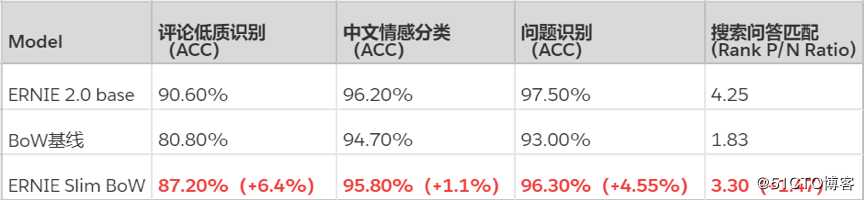
下表展示了 ERNIE Slim 的效果。从表格中可以看出,相对于 ERNIE 2.0 Base 模型,数据蒸馏后的小模型效果损失不大,预测速度提升千倍以上;而相对于简单模型,速度接近的情况下,效果会得到显著提升。
特色2:一键式高性能全类微调工具
ERNIE Fine-tune 微调工具旨在为给开发者提供一套简单好用的 Fine-tune 框架,目前覆盖 NLP 四大常用任务:单句分类、句对匹配、命名实体识别、阅读理解。工具集支持多机多卡 Fine-tune,同时使用 FP16 Tensor Core 技术在 Tesla V 系列 GPU上获得 60% 的训练速度提升。
Fine-tune 微调工具包含了一个基于飞桨的训练组织框架 Propeller,可以帮助开发者进行模型管理、参数热启动、自动多卡并行等工作,从而让开发者更专注于网络结构以及输入数据流水线的构建。
特色3:极速预测 API
ERNIE Fast-inference API 旨在解决产品应用的延迟敏感场景,为企业开发者提供极速预测的 C++ API,便于开发者集成。该工具也充分借助了最新版飞桨的高速预测优势,飞桨1.6 通过 OP 聚合算法,有效加速了 ERNIE 的预测。
在延迟敏感场景下,对比竞品在 GPU(P4) 设备 21% 的延迟降低,ERNIE Fast-inference API 在 CPU(Intel Xeon Gold 6148 CPU)设备上的延迟降低 60%。
特色4:向量服务器,支持跨平台灵活部署
为进一步降低开发者使用成本,套件提供预测服务方案——ERNIE Service,来方便获取ERNIE 模型的向量分布以及预测打分。
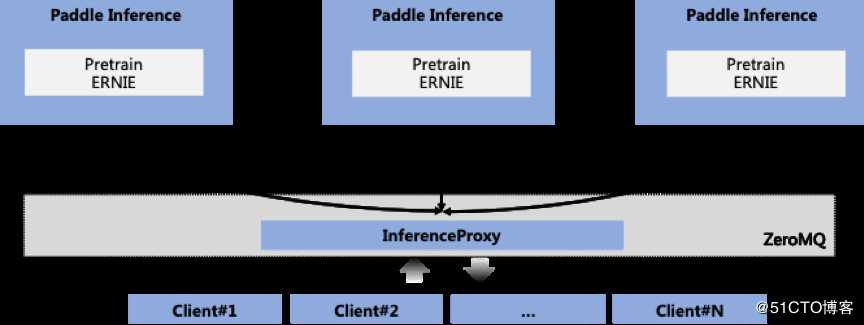
ERNIE Service 架构
ERNIE Service 是基于 Python 构建的多 GPU 预测服务,Client 端发送的请求会自动分发至 GPU 上执行 ERNIE Fast-inference API 来获取 ERNIE 向量及打分。目前 ERNIE Service 支持不同平台、不同设备、不同语言的灵活调用,具备预测性能高等特点,相比竞品 BERT-as-service 在 QPS 上提升 13%。
特色5:平台赋能
此外,套件还包含了 ERNIE 的平台化使用方案,开发者可通过 EasyDL 专业版一站式完成 NLP 任务的数据标注、处理、ERNIE 微调、优化、部署等全流程的功能,为开发者提供丰富的算法、算力服务,进一步降低 ERNIE 的产业化应用门槛。平台预置了常用的NLP 文本分类、文本匹配等经典网络,能够快速满足多层次开发者的需求。
综合来看,ERNIE的语义理解开发套件依托百度在预训练模型等自然语言处理技术和飞桨平台领先优势,为人工智能产业化大生产贡献力量,赋能各行各业。
相关链接:
? ERNIE工业级开源工具:
https://github.com/PaddlePaddle/ERNIE
? ERNIE平台化服务:
https://ai.baidu.com/easydl/pro
划重点!
11月23日,艾尼(ERNIE)的巡回沙龙将在上海加场,干货满满的现场,行业A级的导师,还有一群志同道合的小伙伴,还在等什么?感兴趣的开发者们赶快点击下方链接报名参加吧!
报名地址:https://iwenjuan.baidu.com/?code=vc78lp
扫码关注百度NLP官方公众号,获取百度NLP技术的第一手资讯!
加入ERNIE官方技术交流群(760439550),百度工程师实时为您答疑解惑!
立即前往GitHub( github.com/PaddlePaddle/ERNIE )为ERNIE点亮Star,马上学习和使用起来吧!
以上是关于提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件的主要内容,如果未能解决你的问题,请参考以下文章
加州理工华人博士提出傅里叶神经算子,偏微分方程提速1000倍,告别超算!