pandas 有两个dataframe ,求各个分组之间的相除后的均值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas 有两个dataframe ,求各个分组之间的相除后的均值相关的知识,希望对你有一定的参考价值。
pandas 有两个dataframe ,求各个分组之间的相除后的均值。
例如:
dataA = [["A1", "t1", 5], ["A1", "t2", 8], ["A1", "t3", 7],
["A1","t4", 4], ["A1", "t5", 2], ["A1", "t6", 2],
["A2", "t1", 15], ["A2", "t2", 6], ["A2", "t3", 1],
["A2", "t4", 11], ["A2", "t5", 12], ["A2", "t6", 7],
["A3", "t1", 12], ["A3", "t2", 8], ["A3", "t3", 3],
["A3", "t4", 7], ["A3", "t5", 15], ["A3", "t6", 14]]
dataB = [["B", "t1", 2], ["B1", "t2", 9], ["B1", "t3", 17],
["B1","t4", 14], ["B1", "t5", 32], ["B1", "t6", 3],
["B2", "t1", 44], ["B2", "t2", 36], ["B2", "t3", 51],
["B2", "t4", 81], ["B2", "t5", 82], ["B2", "t6", 3]]
data1 = pd.DataFrame(data = dataA, columns=["An", "colA", "Val"])
data2 = pd.DataFrame(data = dataB, columns=["Bm", "colA", "Val"])
我想求这个结果:
GA | GB | result |
---------------------------
| A1 | B1 | val_11 |
--------------------------
| A1 | B2 | val_12 |
--------------------------
| A2 | B1 | val_21 |
--------------------------
| A2 | B2 | val_22 |
--------------------------
| A3 | B1 | val_31 |
--------------------------
| A3 | B2 | val_32 |
...........................
| An | Bm | val_nm |
为了求val 可能要定义一个函数,val都大于0,不会出现除以0的情况
val值是算法如下: val11等于 A1的列值除以B1的列值得的结果的列的均值,
注意A1列除以B1的列,对应数相除结果,如果大于0,则取倒数,然后再求结果的均值
所以无论A1除以B1还是B1除以A1,结果值一定是一样的。
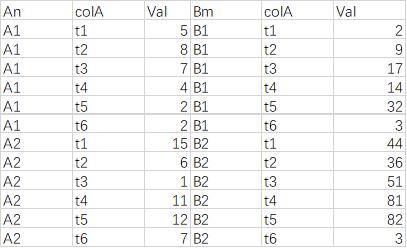
data1 和 data2 里的数值是否是如图中一样整齐一一对应的?
pandas将Series转成DataFrame
1.Series结构
pandas中,我们使用最多的两个数据结构,分别为Series与DataFrame。
Series跟一维数组比较像,可以认为是dataframe中的"一列"。与一维数组不同的是,除了数组数据以外,他还有一组与数组数据对应的标签索引。
2.将Series转成DataFrame
2.1 使用字典的方式转化
import pandas as pd
department = ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C']
group = ['g1', 'g1', 'g2', 'g3', 'g3', 'g4', 'g5', 'g5']
data = pd.DataFrame('department': department, 'group': group)
d2 = data.groupby('department')['group'].apply(lambda x: ",".join(x))
print("d2 is: ", '\\n', d2, "\\nd2 type is: ", type(d2), '\\n')
d2 = pd.DataFrame('department': d2.index, 'group': d2.values)
print("after change, d2 is: ", '\\n', d2, '\\nd2 type is: ', type(d2), '\\n')
上面的代码中,data进行groupby操作以后取group列,得到的就是一个Series结构。
d2 is:
department
A g1,g1,g2
B g3,g3,g4
C g5,g5
Name: group, dtype: object
d2 type is: <class 'pandas.core.series.Series'>
该Series的index是department列,department列的值为A,B,C。具体的值为group,上面的逻辑是将相同department的group值进行聚合。
我们想将其转成一个dataframe,可以使用字典的方式,直接创建一个新的dataframe。d2.index表示Series的索引,d2.values表示Series的数据。
after change, d2 is:
department group
0 A g1,g1,g2
1 B g3,g3,g4
2 C g5,g5
d2 type is: <class 'pandas.core.frame.DataFrame'>
2.2 使用reset_index方法
还可以使用reset_index的方式,来将Series转化为dataframe。
d3 = data.groupby('department')['group'].apply(lambda x: ','.join(x))
d3 = d3.reset_index(name='group')
d3['group'] = d3['group'].map(lambda x: ','.join(sorted(list(set(x.split(','))))))
print(d3)
上面的代码也将Series转换成了一个dataframe,与前面稍微有所区别的在于,对group还进行了去重排序操作。
最后输出的结果为
department group
0 A g1,g2
1 B g3,g4
2 C g5
3.apply,applymap, map
上面的代码中,用到了有apply方法,map方法,还有一个applymap方法,稍微总结一下这几个方法的区别:
import pandas as pd
a = [1, 2, 3, 4, 5]
b = [10, 20, 30, 40, 50]
c = [0.1, 0.2, 0.3, 0.4, 0.5]
data = pd.DataFrame('a': a, 'b': b, 'c': c)
print(data.apply(max), '\\n')
print(data.a.apply(lambda x: x * 2), '\\n')
print(data.applymap(lambda x: x+0.01), '\\n')
print(data.a.map(lambda x: x+0.02))
a 5.0
b 50.0
c 0.5
dtype: float64
0 2
1 4
2 6
3 8
4 10
Name: a, dtype: int64
a b c
0 1.01 10.01 0.11
1 2.01 20.01 0.21
2 3.01 30.01 0.31
3 4.01 40.01 0.41
4 5.01 50.01 0.51
0 1.02
1 2.02
2 3.02
3 4.02
4 5.02
Name: a, dtype: float64
apply可以用于Series,也可以用于DataFrame,可以对一列或多列进行操作。
applymap只能作用于dataframe,是对dataframe的每一个元素进行操作。
map只能作用于Series,其对Series中每个元素起作用。
以上是关于pandas 有两个dataframe ,求各个分组之间的相除后的均值的主要内容,如果未能解决你的问题,请参考以下文章