爬取中国大学排名
Posted yangbiao6
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取中国大学排名相关的知识,希望对你有一定的参考价值。
爬取最好大学网上最新2019年的中国大学排名情况
1.url:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html。
2.使用requests库和bs4库实现对中国大学排名的定向爬取。
3.对包含输出的列表进行排版。
1 import requests 2 from bs4 import BeautifulSoup #对bs4库中的Beautiful类引用 3 import bs4#引入bs4库 4 #获取界面的信息 5 def gethtmlText(url) : 6 try: 7 r = requests.get(url,timeout = 30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 print("获取失败") 13 return ‘‘ 14 #将获取的信息中有用的存入列表中 15 def fillUnivlist(ulist,html): 16 soup = BeautifulSoup(html,"html.parser")#html的方式保存 17 #查看源代码,大学排行信息包含在<tbody>,<tr>,<td>标签里面 18 #先解析<tbody>的位置 19 for tr in soup.find(‘tbody‘).children: 20 #用isinstance方法检测tr标签,如果tr标签不是bs4库中的Tag类型,过滤 21 if isinstance(tr,bs4.element.Tag): 22 #查出所有的tr标签后,查出td标签,将所有的td标签存入列表当中 23 tds = tr(‘td‘) 24 #在列表中增加需要的对应字段,大学排名,大学名称,大学评分 25 ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string]) 26 27 pass 28 #打印出获得的的信息 29 def printUnivlist(ulist,num): 30 #num为自己想要获取大学的数量 31 #打印表头 32 print("{:^10} {:^6} {:^10} {:^10}".format("排名","学校名称","省市","总分")) 33 for i in range(num): 34 u = ulist[i] 35 print("{:^10} {:^6} {:^10} {:^10}".format(u[0],u[1],u[2],u[3])) 36 37 38 print(‘Suc‘+str(num)) 39 40 41 def main(): 42 uinfo=[] #定义一个存放信息的列表 43 url=‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html‘ 44 html = getHTMLText(url) 45 fillUnivlist(uinfo,html) 46 printUnivlist(uinfo,20)#查看20个大学 47 main()
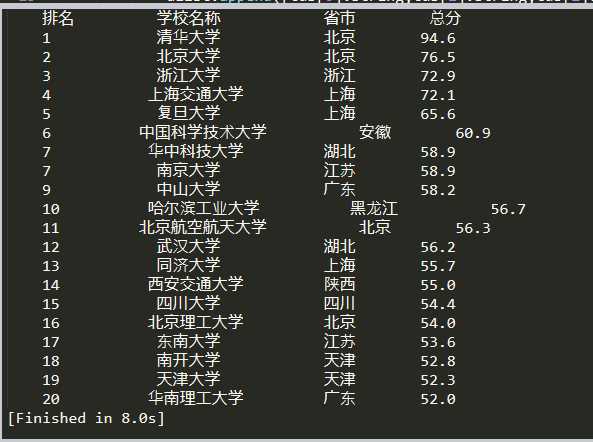
该程序主要包含四个函数:(1)def getHTMLText(url),获取URL中的所有信息;
(2)def fillUnivlist(ulist,html),j继续获取想得到的信息,并将这些信息存入列表当中;
(3)def printUnivlist(ulist,num),打印出(2)中获取的信息;
(4)def main(),初始化一些参数。
优化
中文对齐问题的解决
采用中文字 符的空格填充chr(12288)
{1:{4}^15},这个里面1和4对应format里面的顺序)(1为u[1],在1号位填充。4是四个要填充
的字符串中文空格,10为宽度),而“:” 后面的内容表示填充内容,当长度不够时将自动填充。
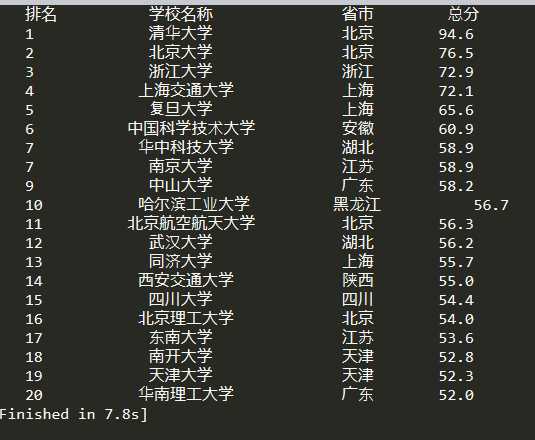
代码尚未优化完全,后期补全!
以上是关于爬取中国大学排名的主要内容,如果未能解决你的问题,请参考以下文章