ES中高级检索(Query)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES中高级检索(Query)相关的知识,希望对你有一定的参考价值。
参考技术AES官方提供了两中检索方式: 一种是通过 URL 参数进行搜索,另一种是通过 DSL(Domain Specified Language) 进行搜索 。 官方更推荐使用第二种方式第二种方式是基于传递JSON作为请求体(request body)格式与ES进行交互,这种方式更强大,更简洁 。
GET /ems/emp/_search?q= &sort=age:asc*
GET /ems/emp/_search?q=*&sort=age:desc&size=5&from=0&_source=name,age,bir
NOTE1: 通过使用term查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词 。
NOTE2: 通过使用term查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词 , 只有text类型分词 。
索引区:name:[张:0:1,张:1:1]在0号文档中,出现1次,在1号文档中出现1次。
好玩的ES--第二篇之高级查询,索引原理和分词器
好玩的ES--第二篇
高级查询
说明
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL ,Query DSL是利用Rest API传递JSON格式的请求体(Request Body)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。
语法
# GET /索引名/_doc/_search json格式请求体数据
# GET /索引名/_search json格式请求体数据
- 测试数据
# 1.创建索引 映射
PUT /products/
"mappings":
"properties":
"title":
"type": "keyword"
,
"price":
"type": "double"
,
"created_at":
"type":"date"
,
"description":
"type":"text"
# 2.测试数据
PUT /products/_doc/_bulk
"index":
"title":"iphone12 pro","price":8999,"created_at":"2020-10-23","description":"iPhone 12 Pro采用超瓷晶面板和亚光质感玻璃背板,搭配不锈钢边框,有银色、石墨色、金色、海蓝色四种颜色。宽度:71.5毫米,高度:146.7毫米,厚度:7.4毫米,重量:187克"
"index":
"title":"iphone12","price":4999,"created_at":"2020-10-23","description":"iPhone 12 高度:146.7毫米;宽度:71.5毫米;厚度:7.4毫米;重量:162克(5.73盎司) [5] 。iPhone 12设计采用了离子玻璃,以及7000系列铝金属外壳。"
"index":
"title":"iphone13","price":6000,"created_at":"2021-09-15","description":"iPhone 13屏幕采用6.1英寸OLED屏幕;高度约146.7毫米,宽度约71.5毫米,厚度约7.65毫米,重量约173克。"
"index":
"title":"iphone13 pro","price":8999,"created_at":"2021-09-15","description":"iPhone 13Pro搭载A15 Bionic芯片,拥有四种配色,支持5G。有128G、256G、512G、1T可选,售价为999美元起。"
常见检索
查询所有[match_all]
match_all关键字: 返回索引中的全部文档
GET /products/_search
"query":
"match_all":
关键词查询(term)
term 关键字: 用来使用关键词查询,还可以用来查询没有被进行分词的数据类型
GET /products/_search
"query":
"term":
"price":
"value": 4999
NOTE1: 通过使用term查询得知ES中默认使用分词器为
标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词。
NOTE2: 通过使用term查询得知,
在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
范围查询[range]
range 关键字: 用来指定查询指定范围内的文档
GET /products/_search
"query":
"range":
"price":
"gte": 1400,
"lte": 9999
前缀查询[prefix]
prefix 关键字: 用来检索含有指定前缀的关键词的相关文档
GET /products/_search
"query":
"prefix":
"title":
"value": "ipho"
通配符查询[wildcard]
wildcard 关键字: 通配符查询 ? 用来匹配一个任意字符 * 用来匹配多个任意字符
GET /products/_search
"query":
"wildcard":
"description":
"value": "iphon*"
多id查询[ids]
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /products/_search
"query":
"ids":
"values": ["verUq3wBOTjuBizqAegi","vurUq3wBOTjuBizqAegk"]
模糊查询[fuzzy]
fuzzy 关键字: 用来模糊查询含有指定关键字的文档
GET /products/_search
"query":
"fuzzy":
"description": "iphooone"
注意:
fuzzy 模糊查询 最大模糊错误 必须在0-2之间
搜索关键词长度为 2 不允许存在模糊
搜索关键词长度为3-5 允许一次模糊
搜索关键词长度大于5 允许最大2模糊
布尔查询[bool]
bool 关键字: 用来组合多个条件实现复杂查询
must: 相当于&& 同时成立
should: 相当于|| 成立一个就行
must_not: 相当于! 不能满足任何一个
GET /products/_search
"query":
"bool":
"must": [
"term":
"price":
"value": 4999
]
多字段查询[multi_match]
可以根据字段类型,决定是否使用分词查询
GET /products/_search
"query":
"multi_match":
"query": "iphone13 毫",
"fields": ["title","description"]
注意: 字段类型分词,将查询条件分词之后进行查询改字段 如果该字段不分词就会将查询条件作为整体进行查询
默认字段分词查询[query_string]
GET /products/_search
"query":
"query_string":
"default_field": "description",
"query": "屏幕真的非常不错"
注意: 查询字段分词就将查询条件分词查询 查询字段不分词将查询条件不分词查询
高亮查询[highlight]
highlight 关键字: 可以让符合条件的文档中的关键词高亮
GET /products/_search
"query":
"term":
"description":
"value": "iphone"
,
"highlight":
"fields":
"*":
自定义高亮html标签: 可以在highlight中使用
pre_tags和post_tags
GET /products/_search
"query":
"term":
"description":
"value": "iphone"
,
"highlight":
"post_tags": ["</span>"],
"pre_tags": ["<span style='color:red'>"],
"fields":
"*":
多字段高亮 使用
require_field_match开启多个字段高亮----字段必须能够分词
es默认只有被搜索的字段才可以高亮,如果想要其他指定的高亮字段,也进行高亮显示,就需要开启多字段高亮
GET /products/_search
"query":
"term":
"description":
"value": "iphone"
,
"highlight":
"require_field_match": "false",
"post_tags": ["</span>"],
"pre_tags": ["<span style='color:red'>"],
"fields":
"*":
返回指定条数[size]
size 关键字: 指定查询结果中返回指定条数。 默认返回值10条
GET /products/_search
"query":
"match_all":
,
"size": 5
分页查询[form]
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
GET /products/_search
"query":
"match_all":
,
"size": 5,
"from": 0
指定字段排序[sort]
会让得分失效
GET /products/_search
"query":
"match_all":
,
"sort": [
"price":
"order": "desc"
]
返回指定字段[_source]
_source 关键字: 是一个数组,在数组中用来指定展示那些字段
GET /products/_search
"query":
"match_all":
,
"_source": ["title","description"]
索引原理
倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时底层使用的就是倒排索引。
索引模型
现有索引和映射如下:
"products" :
"mappings" :
"properties" :
"description" :
"type" : "text"
,
"price" :
"type" : "float"
,
"title" :
"type" : "keyword"
先录入如下数据,有三个字段title、price、description等
| _id | title | price | description |
|---|---|---|---|
| 1 | 蓝月亮洗衣液 | 19.9 | 蓝月亮洗衣液很高效 |
| 2 | iphone13 | 19.9 | 很不错的手机 |
| 3 | 小浣熊干脆面 | 1.5 | 小浣熊很好吃 |
在ES中除了text类型分词,其他类型不分词,因此根据不同字段创建索引如下:
title字段:
| term | _id(文档id) |
|---|---|
| 蓝月亮洗衣液 | 1 |
| iphone13 | 2 |
| 小浣熊干脆面 | 3 |
price字段
| term | _id(文档id) |
|---|---|
| 19.9 | [1,2] |
| 1.5 | 3 |
description字段
| term | _id | term | _id | term | _id |
|---|---|---|---|---|---|
| 蓝 | 1 | 不 | 2 | 小 | 3 |
| 月 | 1 | 错 | 2 | 浣 | 3 |
| 亮 | 1 | 的 | 2 | 熊 | 3 |
| 洗 | 1 | 手 | 2 | 好 | 3 |
| 衣 | 1 | 机 | 2 | 吃 | 3 |
| 液 | 1 | ||||
| 很 | [1:1:9,2:1:6,3:1:6] | ||||
| 高 | 1 | ||||
| 效 | 1 |
[1:1:9,2:1:6,3:1:6]解释:
在1号文档中出现了一次,该文档长度为九
在2号文档中出现了一次,该文档长度为六
在3号文档中出现了一次,该文档长度为六
es会根据关键字出现的次数和文档长度,对搜索出来的结果按照相关度得分进行排序
注意: Elasticsearch分别为每个字段都建立了一个倒排索引。因此查询时查询字段的term,就能知道文档ID,就能快速找到文档。
分词器
Analysis 和 Analyzer
Analysis: 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词(Analyzer)。Analysis是通过Analyzer来实现的。分词就是将文档通过Analyzer分成一个一个的Term(关键词查询),每一个Term都指向包含这个Term的文档。
Analyzer 组成
-
注意: 在ES中默认使用标准分词器: StandardAnalyzer 特点: 中文单字分词 单词分词
我是中国人 this is good man----> analyzer----> 我 是 中 国 人 this is good man
分析器(analyzer)都由三种构件组成的:
character filters,tokenizers,token filters。
-
character filter字符过滤器- 在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
-
tokenizers分词器- 英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
-
Token filtersToken过滤器- 将切分的单词进行加工。大小写转换(例将“Quick”转为小写),去掉停用词(例如停用词像“a”、“and”、“the”等等),加入同义词(例如同义词像“jump”和“leap”)。
注意:
- 三者顺序: Character Filters—>Tokenizer—>Token Filter
- 三者个数:Character Filters(0个或多个) + Tokenizer + Token Filters(0个或多个)
内置分词器
- Standard Analyzer - 默认分词器,英文按单词词切分,并小写处理
- Simple Analyzer - 按照单词切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
内置分词器测试
- 标准分词器
- 特点: 按照单词分词 英文统一转为小写 过滤标点符号 中文单字分词
POST /_analyze
"analyzer": "standard",
"text": "this is a , good Man 中华人民共和国"
- Simple 分词器
- 特点: 英文按照单词分词 英文统一转为小写 去掉符号 中文按照空格进行分词
POST /_analyze
"analyzer": "simple",
"text": "this is a , good Man 中华人民共和国"
- Whitespace 分词器
- 特点: 中文 英文 按照空格分词 英文不会转为小写 不去掉标点符号
POST /_analyze
"analyzer": "whitespace",
"text": "this is a , good Man"
创建索引设置分词
PUT /索引名
"settings": ,
"mappings":
"properties":
"title":
"type": "text",
"analyzer": "standard" //显示指定分词器
中文分词器
在ES中支持中文分词器非常多 如 smartCN、IK 等,推荐的就是 IK分词器。
安装IK
开源分词器 Ik 的github:https://github.com/medcl/elasticsearch-analysis-ik
注意IK分词器的版本要你安装ES的版本一致注意Docker 容器运行 ES 安装插件目录为 /usr/share/elasticsearch/plugins
# 1. 下载对应版本
- [es@linux ~]$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
# 2. 解压
- [es@linux ~]$ unzip elasticsearch-analysis-ik-6.2.4.zip #先使用yum install -y unzip
# 3. 移动到es安装目录的plugins目录中
- [es@linux ~]$ ls elasticsearch-6.2.4/plugins/
[es@linux ~]$ mv elasticsearch elasticsearch-6.2.4/plugins/
[es@linux ~]$ ls elasticsearch-6.2.4/plugins/
elasticsearch
[es@linux ~]$ ls elasticsearch-6.2.4/plugins/elasticsearch/
commons-codec-1.9.jar config httpclient-4.5.2.jar plugin-descriptor.properties
commons-logging-1.2.jar elasticsearch-analysis-ik-6.2.4.jar httpcore-4.4.4.jar
# 4. 重启es生效
# 5. 本地安装ik配置目录为
- es安装目录中/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
将解压完的压缩包删除
docker方式处理插件:
前面两步不变,还是先下载后解压缩
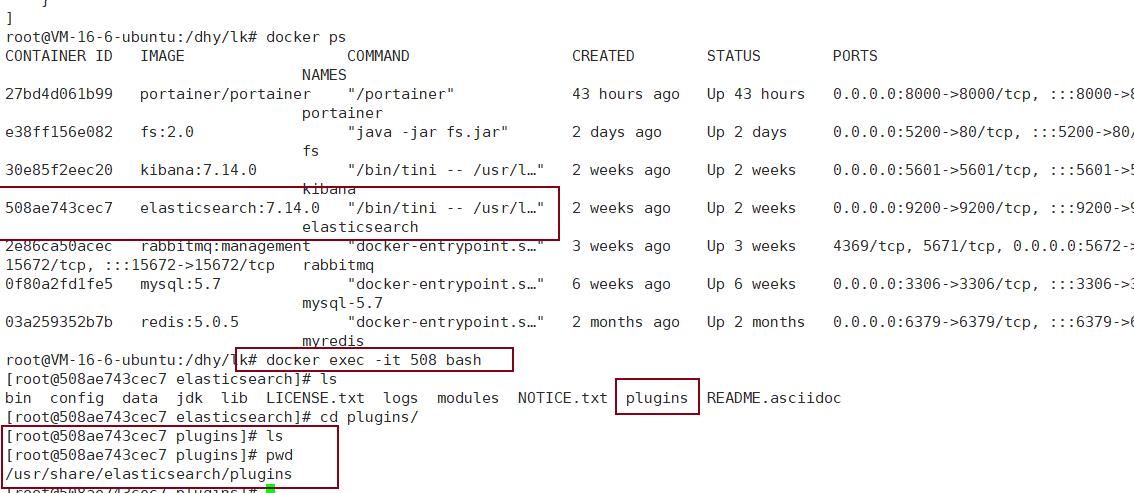
通过共享数据卷的方式,可以将lk插件放入es的plugins目录下
version: "3.0"
volumes:
data:
config:
networks:
es:
services:
elasticsearch:
image: "elasticsearch:7.14.0"
ports:
- "9200:9200"
- "9300:9300"
networks:
- "es"
environment:
- "discovery.type=single-node"
- "ES_JAVA_OPTS=-Xms512m -Xmx521m"
volumes:
#别名的方式
- "data:/usr/share/elasticsearch/data"
- "config:/usr/share/elasticsearch/config"
#指定为lk文件目录所在路径
- "/dhy/elasearch/lk:/usr/share/elasticsearch/plugins"
kibana:
image: "kibana:7.14.0"
ports:
- "5601:5601"
networks:
- "es"
这里不需要修改kinbana的配置文件,因为现在两者在同一自定义网络下面,可以通过服务名访问
IK使用
IK有两种颗粒度的拆分:
-
ik_smart: 会做最粗粒度的拆分 -
ik_max_word: 会将文本做最细粒度的拆分
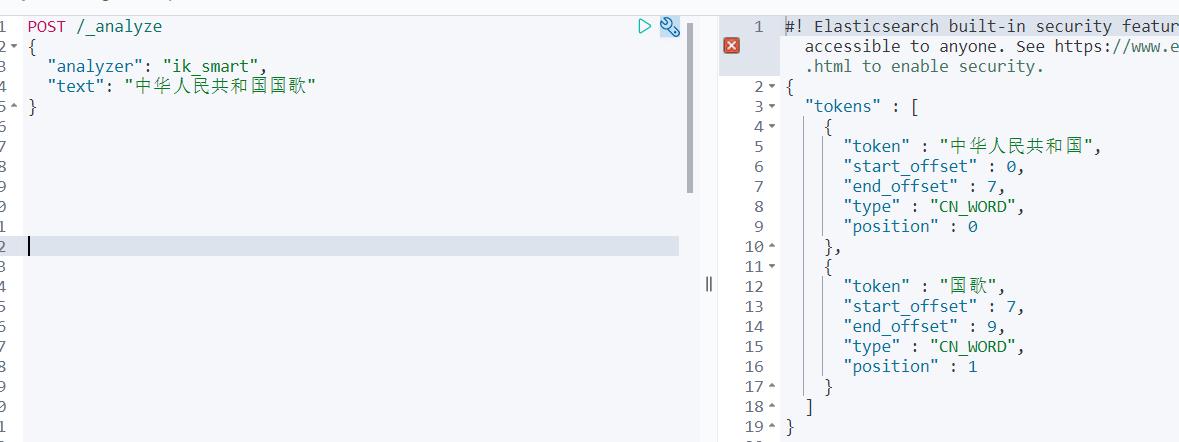
POST /_analyze
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
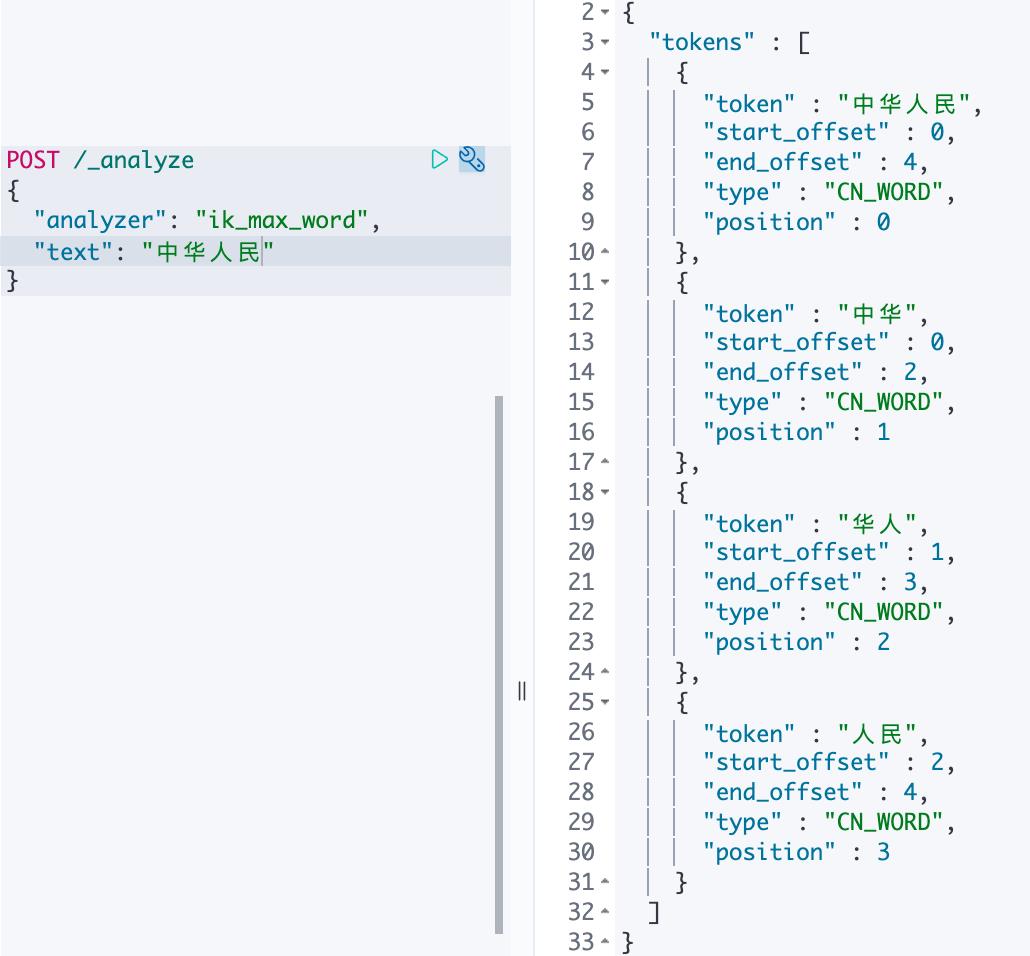
POST /_analyze
"analyzer": "ik_max_word",
"text": "中华人民"
扩展词、停用词配置
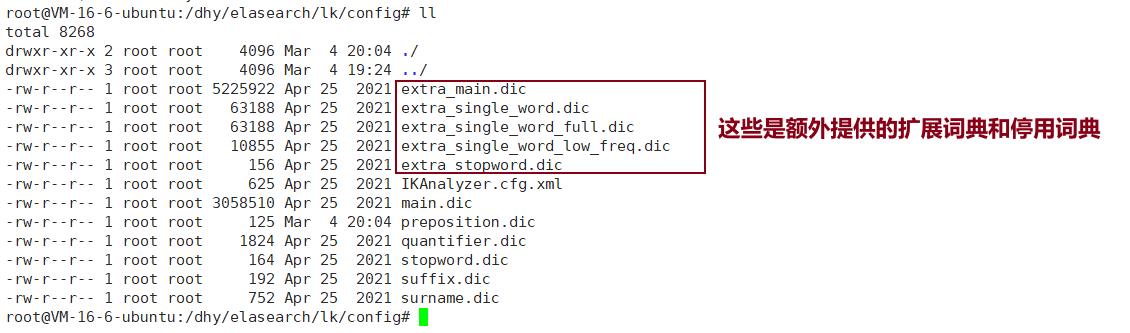
IK支持自定义扩展词典和停用词典
扩展词典就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。停用词典就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典。
定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.cfg.xml这个文件。
1. 修改vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>
2. 在ik分词器目录下config目录中创建ext_dict.dic文件 编码一定要为UTF-8才能生效
vim ext_dict.dic 加入扩展词即可
3. 在ik分词器目录下config目录中创建ext_stopword.dic文件
vim ext_stopword.dic 加入停用词即可
4.重启es生效
注意:词典的编码必须为UTF-8,否则无法生效!
以上是关于ES中高级检索(Query)的主要内容,如果未能解决你的问题,请参考以下文章
elasticSearch多条件高级检索语句,包含多个mustmust_notshould嵌套示例,并考虑nested对象的特殊检索
ES 23 - 检索和过滤的区别 (query vs. filter)