最新整理Spring面试题2023
Posted 波波烤鸭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新整理Spring面试题2023相关的知识,希望对你有一定的参考价值。
Spring面试专题
1.Spring应该很熟悉吧?来介绍下你的Spring的理解
有些同学可能会抢答,不熟悉!!!

好了,不开玩笑,面对这个问题我们应该怎么来回答呢?我们给大家梳理这个几个维度来回答
1.1 Spring的发展历程
先介绍Spring是怎么来的,发展中有哪些核心的节点,当前的最新版本是什么等

通过上图可以比较清晰的看到Spring的各个时间版本对应的时间节点了。也就是Spring从之前单纯的xml的配置方式,到现在的完全基于注解的编程方式发展。
1.2 Spring的组成
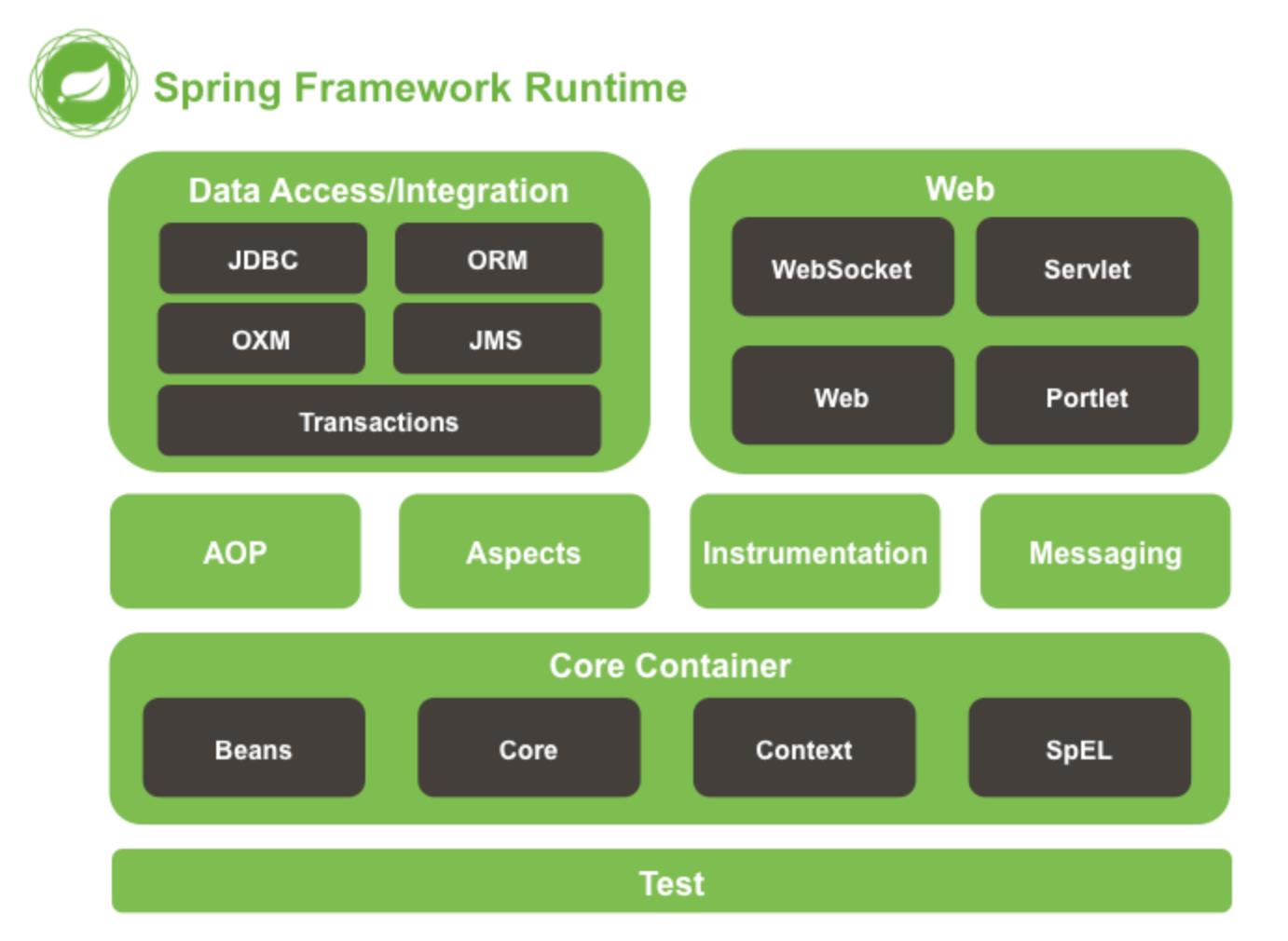
Spring是一个轻量级的IoC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。常见的配置方式有三种:基于XML的配置、基于注解的配置、基于Java的配置.
主要由以下几个模块组成:
- Spring Core:核心类库,提供IOC服务;
- Spring Context:提供框架式的Bean访问方式,以及企业级功能(JNDI、定时任务等);
- Spring AOP:AOP服务;
- Spring DAO:对JDBC的抽象,简化了数据访问异常的处理;
- Spring ORM:对现有的ORM框架的支持;
- Spring Web:提供了基本的面向Web的综合特性,例如多方文件上传;
- Spring MVC:提供面向Web应用的Model-View-Controller实现。
1.3 Spring的好处
| 序号 | 好处 | 说明 |
|---|---|---|
| 1 | 轻量 | Spring 是轻量的,基本的版本大约2MB。 |
| 2 | 控制反转 | Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,<br>而不是创建或查找依赖的对象们。 |
| 3 | 面向切面编程(AOP) | Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开。 |
| 4 | 容器 | Spring 包含并管理应用中对象的生命周期和配置。 |
| 5 | MVC框架 | Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品。 |
| 6 | 事务管理 | Spring 提供一个持续的事务管理接口,<br>可以扩展到上至本地事务下至全局事务(JTA)。 |
| 7 | 异常处理 | Spring 提供方便的API把具体技术相关的异常 <br>(比如由JDBC,Hibernate or JDO抛出的)转化为一致的unchecked 异常。 |
| 8 | 最重要的 | 用的人多!!! |
2.Spring框架中用到了哪些设计模式
2.1 单例模式
单例模式应该是大家印象最深的一种设计模式了。在Spring中最明显的使用场景是在配置文件中配置注册bean对象的时候设置scope的值为singleton 。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.dpb.pojo.User" id="user" scope="singleton">
<property name="name" value="波波烤鸭"></property>
</bean>
</beans>
2.2 原型模式
原型模式也叫克隆模式,Spring中该模式使用的很明显,和单例一样在bean标签中设置scope的属性prototype即表示该bean以克隆的方式生成
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.dpb.pojo.User" id="user" scope="prototype">
<property name="name" value="波波烤鸭"></property>
</bean>
</beans>
2.3 模板模式
模板模式的核心是父类定义好流程,然后将流程中需要子类实现的方法就抽象话留给子类实现,Spring中的JdbcTemplate就是这样的实现。我们知道jdbc的步骤是固定
- 加载驱动,
- 获取连接通道,
- 构建sql语句.
- 执行sql语句,
- 关闭资源
在这些步骤中第3步和第四步是不确定的,所以就留给客户实现,而我们实际使用JdbcTemplate的时候也确实是只需要构建SQL就可以了.这就是典型的模板模式。我们以query方法为例来看下JdbcTemplate中的代码.

2.4 观察者模式
观察者模式定义的是对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。使用比较场景是在监听器中而spring中Observer模式常用的地方也是listener的实现。如ApplicationListener.
2.5 工厂模式
简单工厂模式:
简单工厂模式就是通过工厂根据传递进来的参数决定产生哪个对象。Spring中我们通过getBean方法获取对象的时候根据id或者name获取就是简单工厂模式了。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd">
<context:annotation-config/>
<bean class="com.dpb.pojo.User" id="user" >
<property name="name" value="波波烤鸭"></property>
</bean>
</beans>
工厂方法模式:
在Spring中我们一般是将Bean的实例化直接交给容器去管理的,实现了使用和创建的分离,这时容器直接管理对象,还有种情况是,bean的创建过程我们交给一个工厂去实现,而Spring容器管理这个工厂。这个就是我们讲的工厂模式,在Spring中有两种实现一种是静态工厂方法模式,一种是动态工厂方法模式。以静态工厂来演示
/**
* User 工厂类
* @author dpb[波波烤鸭]
*
*/
public class UserFactory
/**
* 必须是static方法
* @return
*/
public static UserBean getInstance()
return new UserBean();
application.xml文件中注册
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 静态工厂方式配置 配置静态工厂及方法 -->
<bean class="com.dpb.factory.UserFactory" factory-method="getInstance" id="user2"/>
</beans>
2.6 适配器模式
将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作。这就是适配器模式。在Spring中在AOP实现中的Advice和interceptor之间的转换就是通过适配器模式实现的。
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable
@Override
public boolean supportsAdvice(Advice advice)
return (advice instanceof MethodBeforeAdvice);
@Override
public MethodInterceptor getInterceptor(Advisor advisor)
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
// 通知类型匹配对应的拦截器
return new MethodBeforeAdviceInterceptor(advice);
2.7 装饰者模式
装饰者模式又称为包装模式(Wrapper),作用是用来动态的为一个对象增加新的功能。装饰模式是一种用于代替继承的技术,无须通过继承增加子类就能扩展对象的新功能。使用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。
spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。基本上都是动态地给一个对象添加一些额外的职责。
具体的使用在Spring session框架中的SessionRepositoryRequestWrapper使用包装模式对原生的request的功能进行增强,可以将session中的数据和分布式数据库进行同步,这样即使当前tomcat崩溃,session中的数据也不会丢失。
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session</artifactId>
<version>1.3.1.RELEASE</version>
</dependency>
2.8 代理模式
代理模式应该是大家非常熟悉的设计模式了,在Spring中AOP的实现中代理模式使用的很彻底.
2.9 策略模式
策略模式对应于解决某一个问题的一个算法族,允许用户从该算法族中任选一个算法解决某一问题,同时可以方便的更换算法或者增加新的算法。并且由客户端决定调用哪个算法,spring中在实例化对象的时候用到Strategy模式。XmlBeanDefinitionReader,PropertiesBeanDefinitionReader
2.10 责任链默认
AOP中的拦截器链
2.11 委托者模式
DelegatingFilterProxy,整合Shiro,SpringSecurity的时候都有用到。
…
3.Autowired和Resource关键字的区别?
这是一个相对比较简单的问题,@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
3.1 共同点
两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法.
3.2 不同点
@Autowired
@Autowired为Spring提供的注解,需要导入org.springframework.beans.factory.annotation.Autowired;只按照byType注入。
public class TestServiceImpl
// 下面两种@Autowired只要使用一种即可
@Autowired
private UserDao userDao; // 用于字段上
@Autowired
public void setUserDao(UserDao userDao) // 用于属性的方法上
this.userDao = userDao;
@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualififier注解一起使用。如下:
public class TestServiceImpl
@Autowired
@Qualifier("userDao")
private UserDao userDao;
@Resource
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略.
public class TestServiceImpl
// 下面两种@Resource只要使用一种即可
@Resource(name="userDao")
private UserDao userDao; // 用于字段上
@Resource(name="userDao")
public void setUserDao(UserDao userDao) // 用于属性的setter方法上
this.userDao = userDao;
@Resource装配顺序:
- 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
- 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
- 如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
- 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入。
4.Spring中常用的注解有哪些,重点介绍几个
@Controller @Service @RestController @RequestBody,@Indexd @Import等
@Indexd提升 @ComponentScan的效率
@Import注解是import标签的替换,在SpringBoot的自动装配中非常重要,也是EnableXXX的前置基础。
5.循环依赖
面试的重点,大厂必问之一:
5.1 什么是循环依赖
看下图
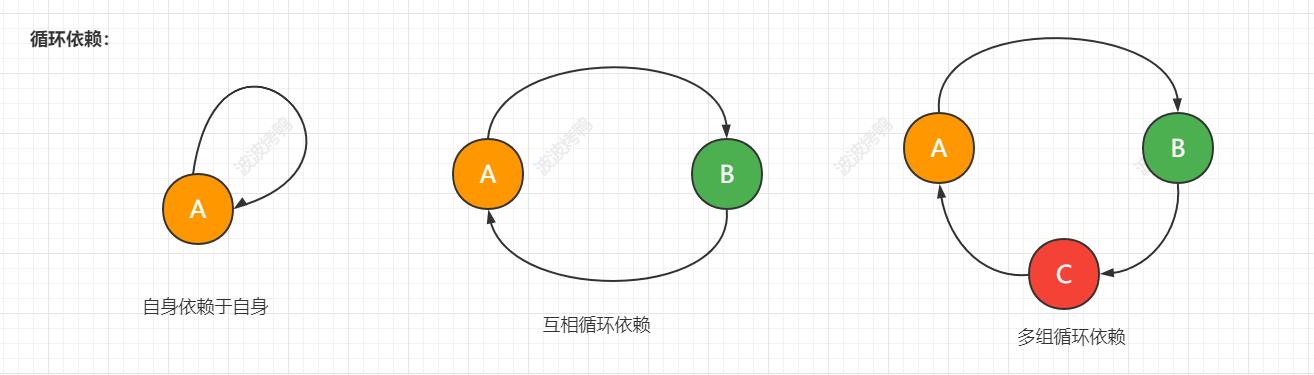
上图是循环依赖的三种情况,虽然方式有点不一样,但是循环依赖的本质是一样的,就你的完整创建要依赖与我,我的完整创建也依赖于你。相互依赖从而没法完整创建造成失败。
5.2 代码演示
我们再通过代码的方式来演示下循环依赖的效果
public class CircularTest
public static void main(String[] args)
new CircularTest1();
class CircularTest1
private CircularTest2 circularTest2 = new CircularTest2();
class CircularTest2
private CircularTest1 circularTest1 = new CircularTest1();
执行后出现了 StackOverflowError 错误
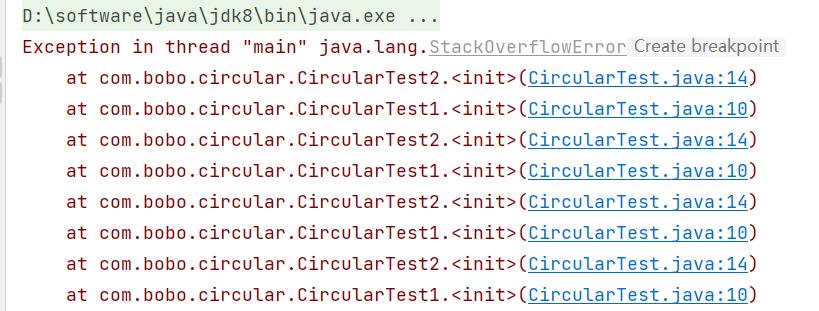
上面的就是最基本的循环依赖的场景,你需要我,我需要你,然后就报错了。而且上面的这种设计情况我们是没有办法解决的。那么针对这种场景我们应该要怎么设计呢?这个是关键!
5.3 分析问题
首先我们要明确一点就是如果这个对象A还没创建成功,在创建的过程中要依赖另一个对象B,而另一个对象B也是在创建中要依赖对象A,这种肯定是无解的,这时我们就要转换思路,我们先把A创建出来,但是还没有完成初始化操作,也就是这是一个半成品的对象,然后在赋值的时候先把A暴露出来,然后创建B,让B创建完成后找到暴露的A完成整体的实例化,这时再把B交给A完成A的后续操作,从而揭开了循环依赖的密码。也就是如下图:
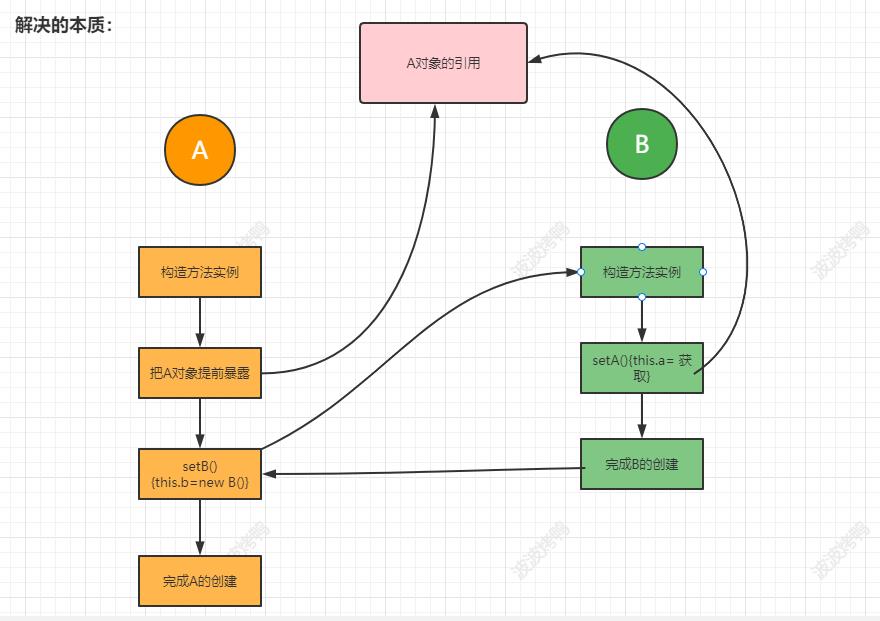
5.4 自己解决
明白了上面的本质后,我们可以自己来尝试解决下:
先来把上面的案例改为set/get来依赖关联
public class CircularTest
public static void main(String[] args) throws Exception
System.out.println(getBean(CircularTest1.class).getCircularTest2());
System.out.println(getBean(CircularTest2.class).getCircularTest1());
private static <T> T getBean(Class<T> beanClass) throws Exception
// 1.获取 实例对象
Object obj = beanClass.newInstance();
// 2.完成属性填充
Field[] declaredFields = obj.getClass().getDeclaredFields();
// 遍历处理
for (Field field : declaredFields)
field.setAccessible(true); // 针对private修饰
// 获取成员变量 对应的类对象
Class<?> fieldClass = field.getType();
// 获取对应的 beanName
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// 给成员变量赋值 如果 singletonObjects 中有半成品就获取,否则创建对象
field.set(obj,getBean(fieldClass));
return (T) obj;
class CircularTest1
private CircularTest2 circularTest2;
public CircularTest2 getCircularTest2()
return circularTest2;
public void setCircularTest2(CircularTest2 circularTest2)
this.circularTest2 = circularTest2;
class CircularTest2
private CircularTest1 circularTest1;
public CircularTest1 getCircularTest1()
return circularTest1;
public void setCircularTest1(CircularTest1 circularTest1)
this.circularTest1 = circularTest1;
然后我们再通过把对象实例化和成员变量赋值拆解开来处理。从而解决循环依赖的问题
public class CircularTest
// 保存提前暴露的对象,也就是半成品的对象
private final static Map<String,Object> singletonObjects = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception
System.out.println(getBean(CircularTest1.class).getCircularTest2());
System.out.println(getBean(CircularTest2.class).getCircularTest1());
private static <T> T getBean(Class<T> beanClass) throws Exception
//1.获取类对象对应的名称
String beanName = beanClass.getSimpleName().toLowerCase();
// 2.根据名称去 singletonObjects 中查看是否有半成品的对象
if(singletonObjects.containsKey(beanName))
return (T) singletonObjects.get(beanName);
// 3. singletonObjects 没有半成品的对象,那么就反射实例化对象
Object obj = beanClass.newInstance();
// 还没有完整的创建完这个对象就把这个对象存储在了 singletonObjects中
singletonObjects.put(beanName,obj);
// 属性填充来补全对象
Field[] declaredFields = obj.getClass().getDeclaredFields();
// 遍历处理
for (Field field : declaredFields)
field.setAccessible(true); // 针对private修饰
// 获取成员变量 对应的类对象
Class<?> fieldClass = field.getType();
// 获取对应的 beanName
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// 给成员变量赋值 如果 singletonObjects 中有半成品就获取,否则创建对象
field.set(obj,singletonObjects.containsKey(fieldBeanName)?
singletonObjects.get(fieldBeanName):getBean(fieldClass));
return (T) obj;
class CircularTest1
private CircularTest2 circularTest2;
public CircularTest2 getCircularTest2()
return circularTest2;
public void setCircularTest2(CircularTest2 circularTest2)
this.circularTest2 = circularTest2;
class CircularTest2
private CircularTest1 circularTest1;
public CircularTest1 getCircularTest1()
return circularTest1;
public void setCircularTest1(CircularTest1 circularTest1)
this.circularTest1 = circularTest1;
运行程序你会发现问题完美的解决了
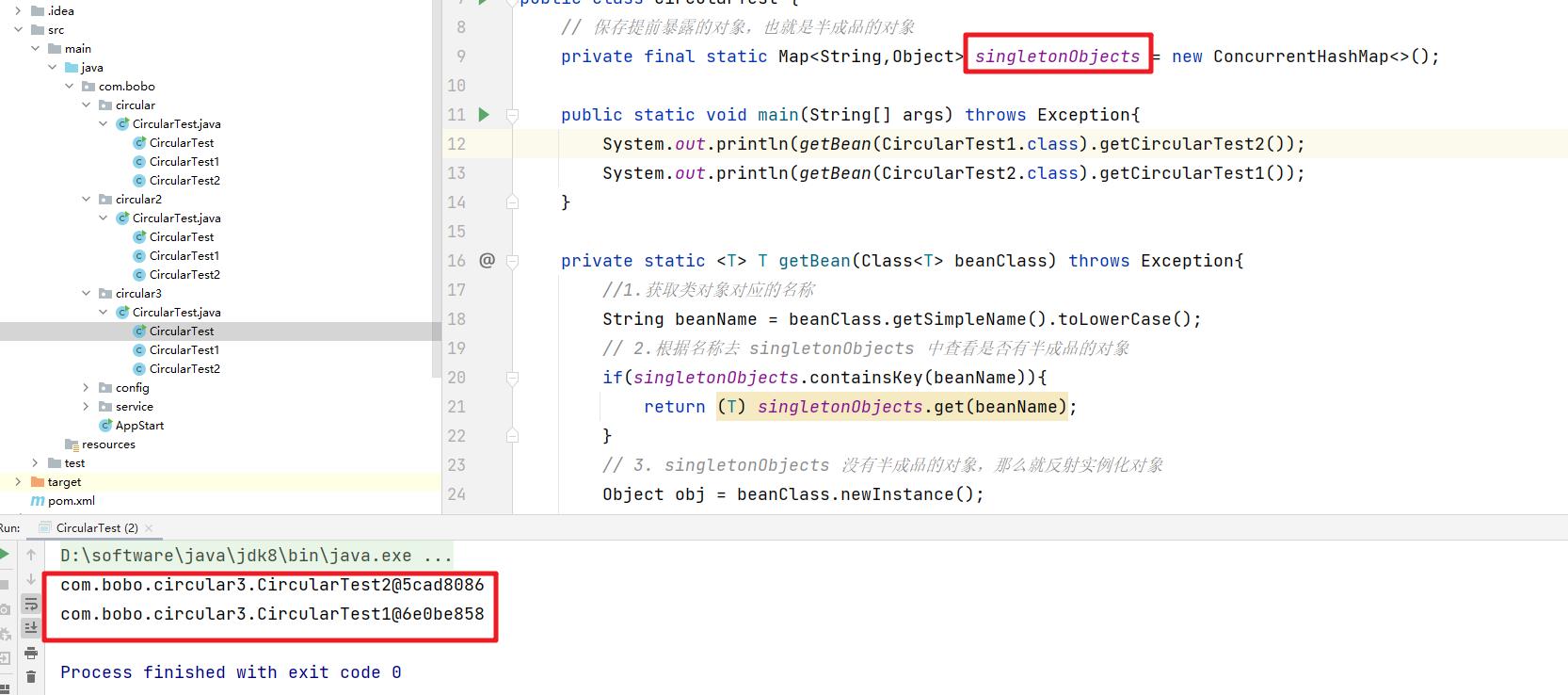
在上面的方法中的核心是getBean方法,Test1 创建后填充属性时依赖Test2,那么就去创建 Test2,在创建 Test2 开始填充时发现依赖于 Test1,但此时 Test1 这个半成品对象已经存放在缓存到 singletonObjects 中了,所以Test2可以正常创建,在通过递归把 Test1 也创建完整了。

最后总结下该案例解决的本质:
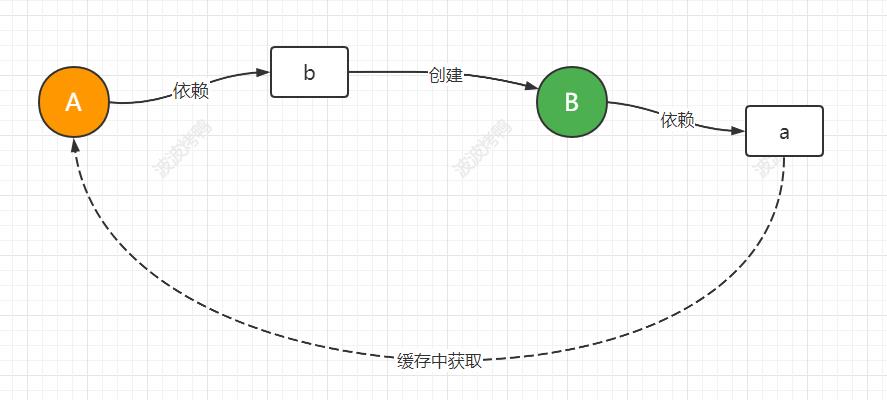
5.5 Spring循环依赖
针对Spring中Bean对象的各种场景。支持的方案不一样:
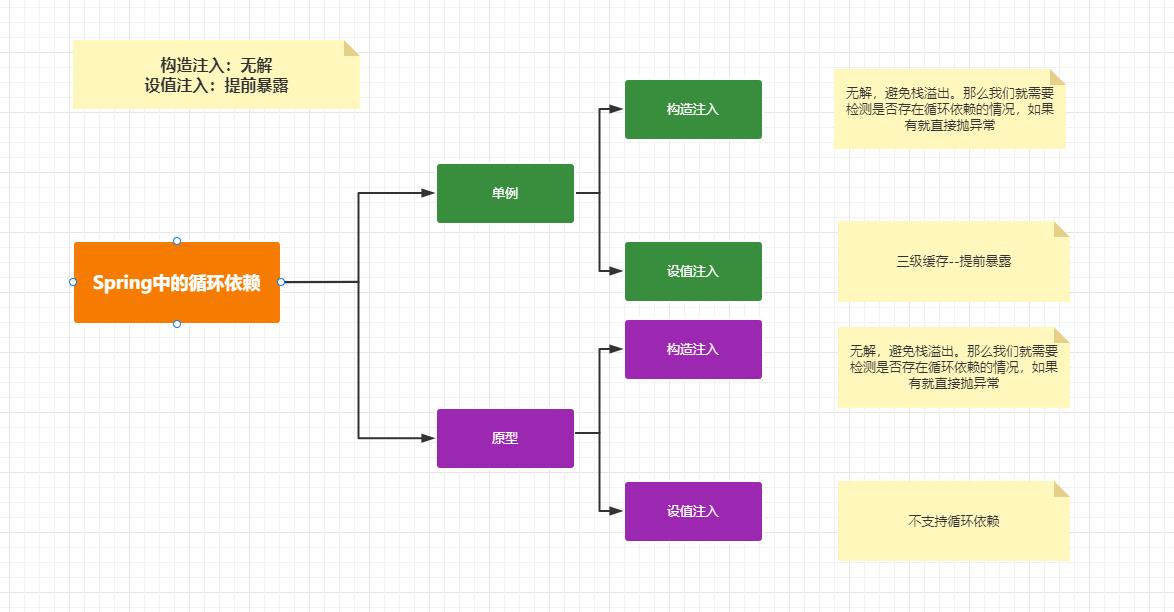
然后我们再来看看Spring中是如何解决循环依赖问题的呢?刚刚上面的案例中的对象的生命周期的核心就两个

而Spring创建Bean的生命周期中涉及到的方法就很多了。下面是简单列举了对应的方法
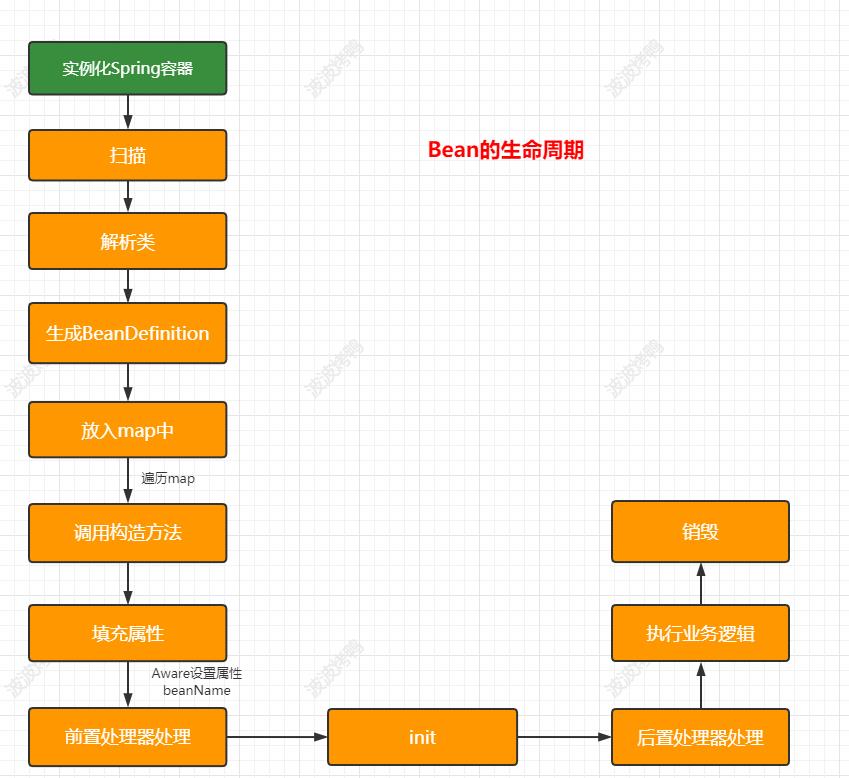
基于前面案例的了解,我们知道肯定需要在调用构造方法方法创建完成后再暴露对象,在Spring中提供了三级缓存来处理这个事情,对应的处理节点如下图:

对应到源码中具体处理循环依赖的流程如下:
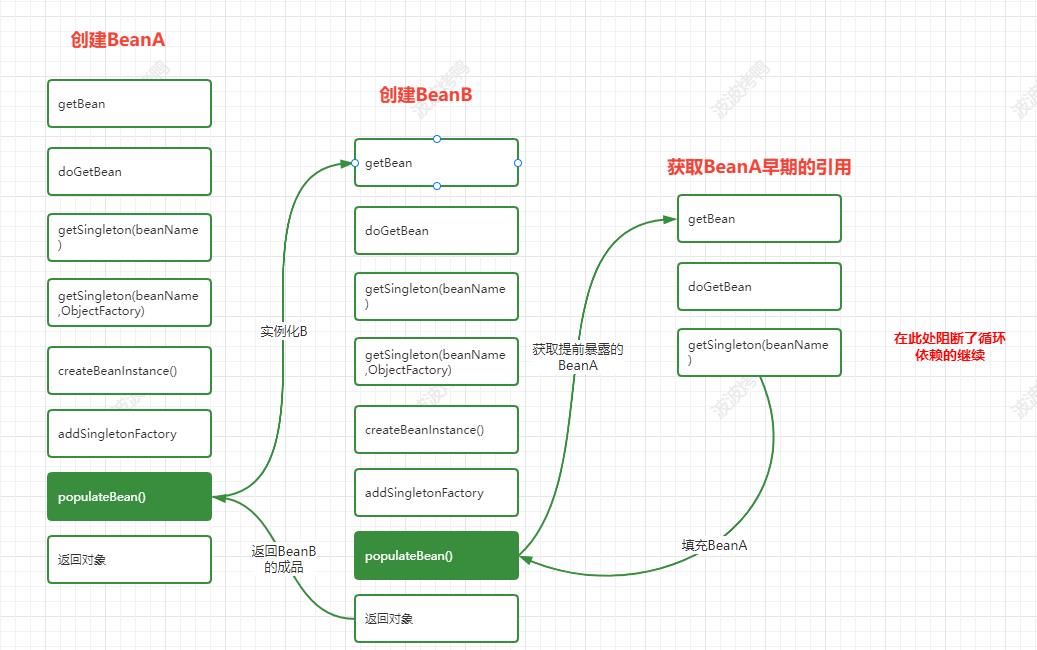
上面就是在Spring的生命周期方法中和循环依赖出现相关的流程了。那么源码中的具体处理是怎么样的呢?我们继续往下面看。
首先在调用构造方法的后会放入到三级缓存中
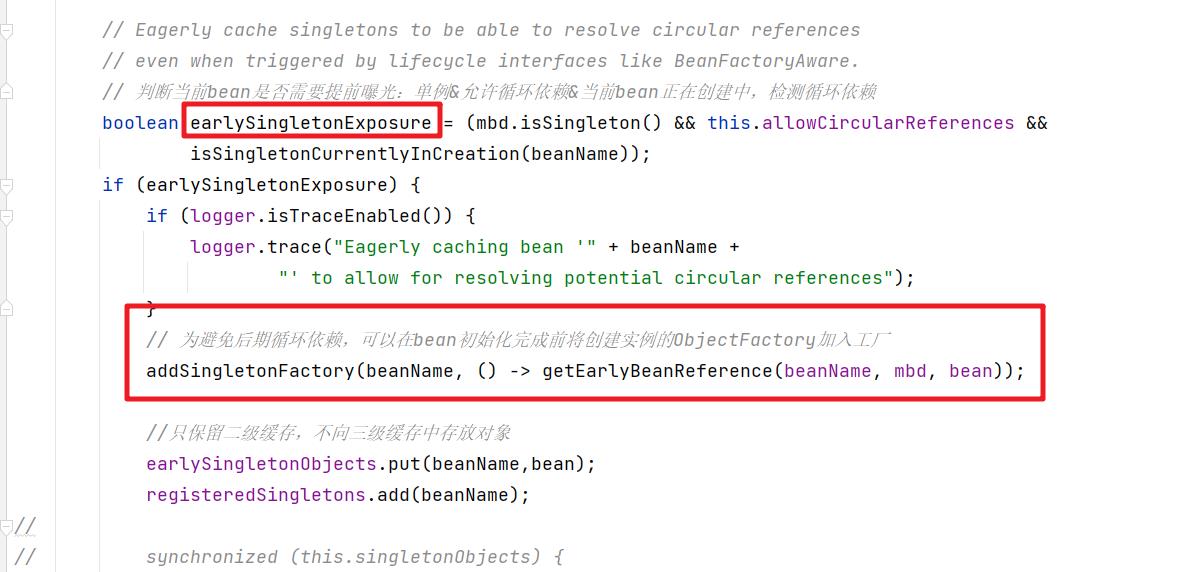
下面就是放入三级缓存的逻辑
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory)
Assert.notNull(singletonFactory, "Singleton factory must not be null");
// 使用singletonObjects进行加锁,保证线程安全
synchronized (this.singletonObjects)
// 如果单例对象的高速缓存【beam名称-bean实例】没有beanName的对象
if (!this.singletonObjects.containsKey(beanName))
// 将beanName,singletonFactory放到单例工厂的缓存【bean名称 - ObjectFactory】
this.singletonFactories.put(beanName, singletonFactory);
// 从早期单例对象的高速缓存【bean名称-bean实例】 移除beanName的相关缓存对象
this.earlySingletonObjects.remove(beanName);
// 将beanName添加已注册的单例集中
this.registeredSingletons.add(beanName);
然后在填充属性的时候会存入二级缓存中
earlySingletonObjects.put(beanName,bean);
registeredSingletons.以上是关于最新整理Spring面试题2023的主要内容,如果未能解决你的问题,请参考以下文章