浏览器解码顺序
Posted p0laris
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器解码顺序相关的知识,希望对你有一定的参考价值。
0x00 个人理解;不觉得很对;看看就好;自己思考;
0x01 试验
一个正常的html页面解码的顺序是URL->HTML->CSS->JS;正常的意思就是一个get请求一个界面;
使用下面的例子来说明各种解码;
为了方便贴上a字符的各种编码;
| 字符 | ASCII八进制 | ASCII十进制 | ASCII十六进制 | Base64 | URL编码 |
|---|---|---|---|---|---|
| a | 141 | 97 | 61 | YQ== | %61 |
| JSUnicode | JS八进制 | JS十六进制 | HTML字符实体 | HTML十进制实体 | HTML十六进制实体 |
| u0061 | 141 | x61 | null | a | a |
eg:<a href=javascript:alert(‘a‘)>code</a>
进行如下变形:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
HTML十六进制实体编码1:<a href=javascript:alert('a')>code</a></br>
URL编码2:<a href=j%61vascript:alert('%61')>code</a></br>
URL编码3:<a href=javascript:%61lert('%61')>code</a></br>
JS十六进制编码4:<a href=javascript:alert('x61')>code</a></br>
JS十六进制编码5:<a href=javascript:&x61lert('x61')>code</a></br>
先URL后JS十六进制6:<a href=javascript:alert('x25x06x01')>code</a></br>
先JS十六进制后URL7:<a href=javascript:alert('%5c%78%36%31')>code</a></br>
双重HTML8:<a href=javascript:alert('&#x61;')>code</a></br>
</body>
</html>经过浏览器一次渲染后的结果:
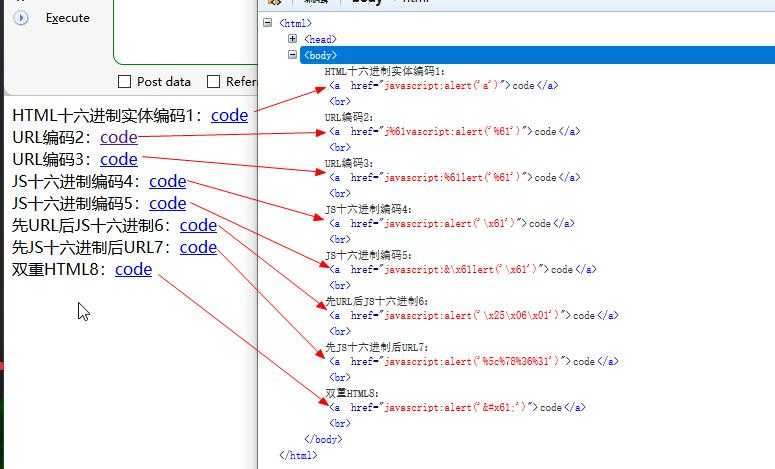
如表:
| 1 | 2 | |
|---|---|---|
| 源代码 | <a href=javascript:alert(‘a‘)>code</a> |
<a href=j%61vascript:alert(‘%61‘)>code</a> |
| 一次渲染 | <a href="javascript:alert(‘a‘)">code</a> |
<a href="j%61vascript:alert(‘%61‘)">code</a> |
| 二次点击 | 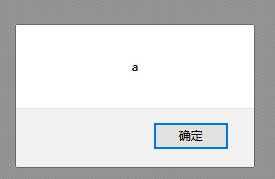 |
无法访问403 |
| 解释 | 一次渲染解码HTML;点击执行JS弹框 | 一次渲染没有进行URL解码;超链接伪协议不完整,不会触发js弹窗;直接403; |
| 3 | 4 | |
| 源代码 | <a href=javascript:%61lert(‘%61‘)>code</a> |
<a href=javascript:alert(‘x61‘)>code</a> |
| 一次渲染 | <a href="javascript:%61lert(‘%61‘)">code</a> |
<a href="javascript:alert(‘x61‘)">code</a> |
| 点击 | 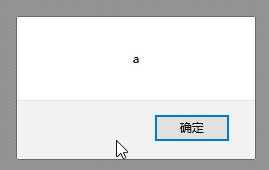 |
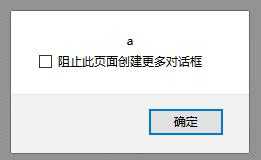 |
| 解释 | 一次渲染没有解码;点击弹窗说明执行了URL解码,对比2,伪协议完整,本身没有编码,对后面进行URL解码; | 一次渲染无解码;点击执行URL和JS解码; |
| 5 | 6 | |
| 源代码 | <a href=javascript:&x61lert(‘x61‘)>code</a> |
<a href=javascript:alert(‘x25x06x01‘)>code</a> |
| 一次渲染 | <a href="javascript:&x61lert(‘x61‘)">code</a> |
<a href="javascript:alert(‘x25x06x01‘)">code</a> |
| 点击 | 点击无响应,页面无变化 | 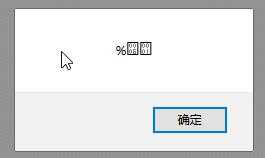 |
| 解释 | 一次无解码;二次点击页面无变化没有403,对比2,说明这里伪协议是正常的;只是无法执行js | 对比7 |
| 7 | 8 | |
| 源代码 | <a href=javascript:alert(‘%5c%78%36%31‘)>code</a> |
<a href=javascript:alert(‘&#x61;‘)>code</a> |
| 一次渲染 | <a href="javascript:alert(‘%5c%78%36%31‘)">code</a> |
<a href="javascript:alert(‘a‘)">code</a> |
| 点击 | 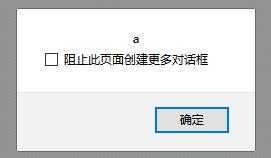 |
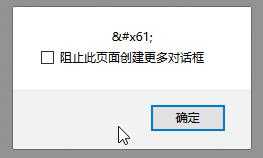 |
| 解释 | 渲染无解码;对比6,说明一次渲染只执行了HTML解码,点击做了URL和JS的解码,并且解码顺序为先URL后JS | 二次点击没有执行HTMl解码 |
0x02 总结
解析编码的时候是先构建DOM树,我的理解就是在自己环境中是不能编码自己的,编码其他类似不影响解析HTMLDOM树的元素,就可以进行解码,而且需要完整的环境执行起来才可以进行解析;
HTMl实体字符是为了在HTML文档中能够显示一些预定义的字符;其他的一些编码,为了转义显示或者是传输方便,可以类比HTML实体编码套用,就是不能编码‘自己‘的或者自己的‘爸爸‘;
JSUnicode编码,需要u开头,四位,不足位补0;表中的a的JSUnicode编码;
所以:要正常解析HTML的DOM节点的话,就不能对构成DOM的元素进行HTML编码;其他编码类似;
当执行到什么环境的时候,组成这个环境的元素还在编码的状态就会出现错误,环境不完整,造成无法解析;普通的值一般都是可以编码的;
符号什么的还没有试验;
以上是关于浏览器解码顺序的主要内容,如果未能解决你的问题,请参考以下文章