MySQL表对象缓存
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL表对象缓存相关的知识,希望对你有一定的参考价值。
参考技术A 表对象缓存: 是将某个表对象的字典信息(定义内容)缓存到内存中,用来提高对表的访问效率。某个表被访问过一次后,只要服务器没有关闭且表定义没有被修改的条件下,访问该表,只需要从内存中找到这个已经缓存起来的对象做相应操作即可。用户访问表时,表对象在缓存时: 通过HASH算法找到TABLE_SHARE,然后每个线程构造各自的实例化TABLE即可。
用户访问表时,当表没有被缓存的情况下: 第一需要打开表,首先需要从系统表中将这个表的所有信息都读入内存中,这些信息包括表名、库名、所有列信息、列的默认值、表的字符集、对应的frm文件路径、所属存储引擎、主键等,将这些信息构造一个TABLE_SHARE结构体,这个结构体是表对象缓存的第一层,所有用户共享访问且为静态不允许修改,它是缓存在table_def_cache(由参数table_definition_cache控制)中的。
而真正与用户打交道的是TABLE_SHARE的衍生品,它对应结构体为TABLE,在被使用前需要将TABLE_SHARE结构体实例化TABLE才能被使用,由每个线程构造各自的实例化TABLE即可。(实例化的TABLE由table_open_cache及table_open_cache_instance控制)
注意1: DDL操作时会将所有instance锁住,而DML操作时instance之间互不干扰。
(DDL statements still require a lock on the entire cache, but such statements are much less frequent than DML statements.)
注意2: 一个线程中如果打开表过多,超过一个instance限制的大小时,是不能跨instance缓存的
(instance大小:table_open_cache / table_open_cache_instances)
表缓存涉及其他参数: 通过下面参数判断table_open_cache参数设置是否合理
table_open_cache_hit:能够从table open cache的free list中找到table则为命中,+1
table_open_cache_misses:与table_open_cache_hit相反,如果找不到则需要重新实例化则+1,通常发生在初始化第一次加载表或超过table_open_cache的设置被淘汰后需要重新实例化。
table_open_cache_overflow:table cache淘汰的数量,每次淘汰+1
opened_tables:已经打开的表数。如果Opened_tables很大,那么table_open_cache的值可能太小了。
open_tables:总的instance (table cache)的总数
MySQL进阶实战6,缓存表视图计数器表
目录
一、缓存表和汇总表
有时提升性能最好的方法是在同一张表中保存衍生的冗余数据,有时候还需要创建一张完全独立的汇总表或缓存表。
- 缓存表用来存储那些获取很简单,但速度较慢的数据;
- 汇总表用来保存使用group by语句聚合查询的数据;
对于缓存表,如果主表使用InnoDB,用MyISAM作为缓存表的引擎将会得到更小的索引占用空间,并且可以做全文检索。
在使用缓存表和汇总表时,必须决定是实时维护数据还是定期重建。哪个更好依赖于应用程序,但是定期重建并不只是节省资源,也可以保持表不会有很多碎片,以及有完全顺序组织的索引。
当重建汇总表和缓存表时,通常需要保证数据在操作时依然可用,这就需要通过使用影子表来实现,影子表指的是一张在真实表背后创建的表,当完成了建表操作后,可以通过一个原子的重命名操作切换影子表和原表。
为了提升读的速度,经常建一些额外索引,增加冗余列,甚至是创建缓存表和汇总表,这些方法会增加写的负担妈也需要额外的维护任务,但在设计高性能数据库时,这些都是常见的技巧,虽然写操作变慢了,但更显著地提高了读的性能。
二、视图与物化视图
1、视图
视图可以理解为一张表或多张表的与计算,它可以将所需要查询的结果封装成一张虚拟表,基于它创建时指定的查询语句返回的结果集。
查询者并不知道使用了哪些表、哪些字段,只是将预编译好的SQL执行,返回结果集。每次查询视图都需要执行查询语句。
2、物化视图
为了防止每次都查询,先将结果集存储起来,这种有真实数据的视图,称为物化视图。
MySQL并不原生支持物化视图,可以使用Justin Swanhart的开源工具Flexviews实现。
相对于传统的临时表和汇总表,Flexviews可以通过提取对源表的更改,增量地重新计算物化视图的内容。
三、加快alter table操作的速度
MySQL的alter table 操作的性能对大表来说是个大问题。MySQL执行大部分修改表结构的操作的方法使用新的结构创建一个空表,从旧表中查出所有数据插入新表,然后删除旧表。
这样操作可能需要花费很长时间,如果内存不足而表又很大,而且还有很多索引的情况下更为严重。
改善的方法有两种:
- 第一种是先在一台不提供服务的机器上执行alter table操作,然后和提供服务的主表进行切换;
- 第二种方式是通过影子拷贝,影子拷贝的技巧是用要求的表结构创建一张和源表无关的新表,然后通过重命名和删表的操作交换两张表。
四、计数器表
通常创建一张表来存储用户的点赞数、网站访问数等。
create table like_count(num int unsigned not null) engine=InnoDB;
每次点赞都会导致计数器进行更新:
update like_count set num = num + 1;
问题在于,对于任何想要更新这一行的事务来说,这条记录上都有一个全局的互斥锁mutex。这会使这些事务都只能串行执行,要获得更高的并发更新性能,可以将计数器保存在多行中,每次随机选择一行进行更新。
create table like_count(
slot tinyint unsigned not null primary key,
num int unsigned not null
) engine=InnoDB;
预先在这张表中新增10条数据,然后选择一个随机的槽slot进行更新:
注意:为了研究之后遇到的问题,后来又插入了一条~

update like_count set num = num + 1 where slot = floor(rand() * 10);
更新了两行,这是为什么呢?
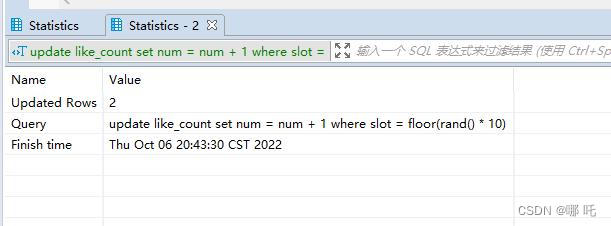
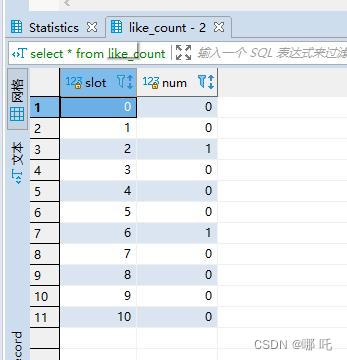
select一下,查询结果,有的时候0条,有的时候1条,有的时候2条,有的时候3条,惊呆了,这么有趣的事情,我怎么能放过,让我们一起一探究竟。
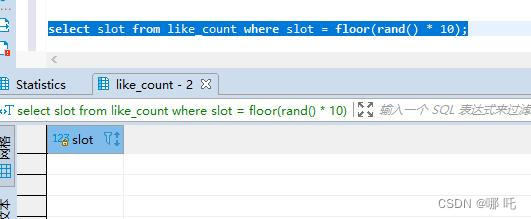
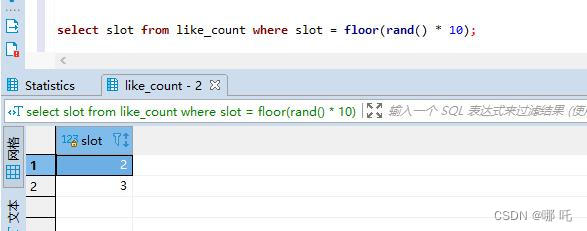
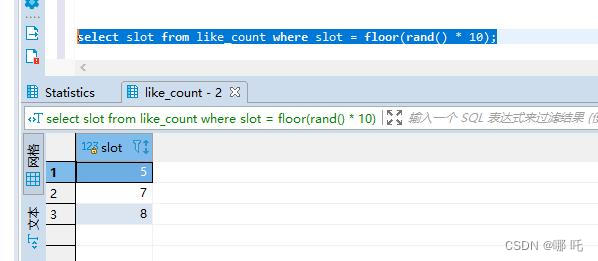
让我们一起一探究竟:
- floor() 函数的作用:返回小于等于该值的最大整数;
- rand()函数的作用:获得0到1之间的随机值;
在ORDER BY或GROUP BY子句中使用带有RAND()值的列可能会产生意想不到的结果,因为对于这两个子句,RAND()表达式都可以对同一行计算多次,每次返回不同的结果。要从一组行中随机选择一个样本,将ORDER BY RAND()和LIMIT配合使用。
在MySQL的官方手册里,针对RAND()的提示大概意思就是,在ORDER BY从句里面不能使用RAND()函数,因为这样会导致数据列被多次扫描。
这就完了?
MySQL进阶实战系列文章
哪吒精品系列文章

以上是关于MySQL表对象缓存的主要内容,如果未能解决你的问题,请参考以下文章