Unity游戏项目性能优化总结 (难度3 推荐4)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unity游戏项目性能优化总结 (难度3 推荐4)相关的知识,希望对你有一定的参考价值。
原文地址:
https://zhuanlan.zhihu.com/p/24392681
本文就Unity游戏项目性能优化作出了总结。包括Profile工具、Unity使用、机制设计、脚本编写等方面内容。
本文的测试机型皆为iPhone6。为方便找出瓶颈目标帧率先提高为60fps,后面再看实际情况是否限帧30fps。
本文的Unity版本为5.5.0f3或更新版本。
本文将持续更新。
Profiler工具
在Unity项目中,可能使用到的Profiler工具分3种:
- 长期性能数据监控工具
- Unity Profiler
- XCode和Instruments
长期性能数据监控工具会至少每天都对游戏单局、或游戏资源进行自动化性能测试,并上报结果到服务器。能从“整体”去对比不同时段、不同版本间的性能差别。
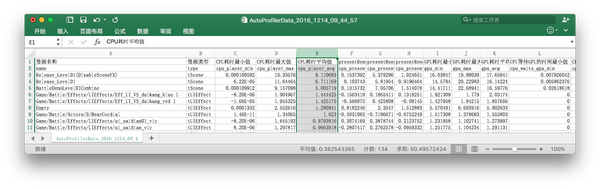 游戏资源长期性能监控工具报表
游戏资源长期性能监控工具报表
Unity Profiler能定量地找到C#的GC Alloc问题;其Timeline视图也能从地整体(但不太定量)找到CPU瓶颈。
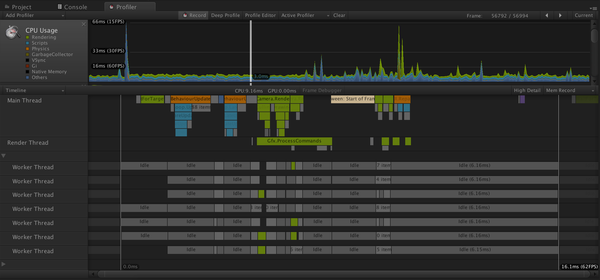 Unity Timeline Profiler
Unity Timeline Profiler
XCode的GPU Report视图能从整体(但不太定量)找到游戏的瓶颈阶段。当Frame Time中CPU大于GPU时,表示CPU是瓶颈,否则表示GPU是瓶颈;当Utilization中的TILER比RENDERER高时,表示顶点处理是GPU的瓶颈,否则表示像素处理是GPU的瓶颈。
帧率受限于瓶颈,应优先优化瓶颈阶段,非瓶颈阶段优化得再快都无法提高帧率。
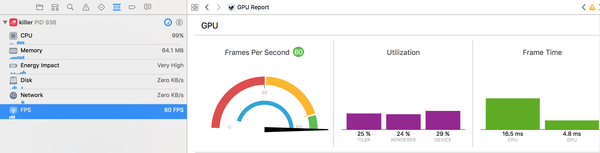 GPU Report
GPU Report
XCode的Capture GPU frame功能能高效且定量地定位到GPU中shader的消耗。
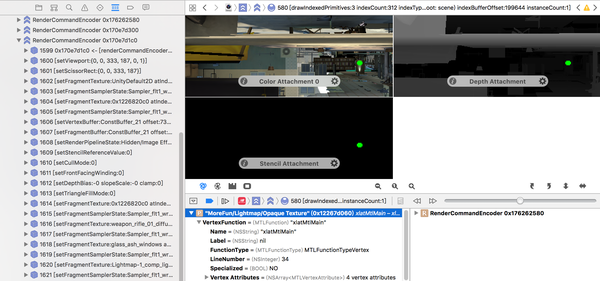 XCode Capture GPU frame
XCode Capture GPU frame
Instruments的TimeProfiler能高效且定量地定位C#脚本(IL2CPP后的C++代码)的CPU占用,甚至包括部分Unity引擎代码的CPU占用函数消耗,而不必麻烦地添加BeginSample()、EndSample()。
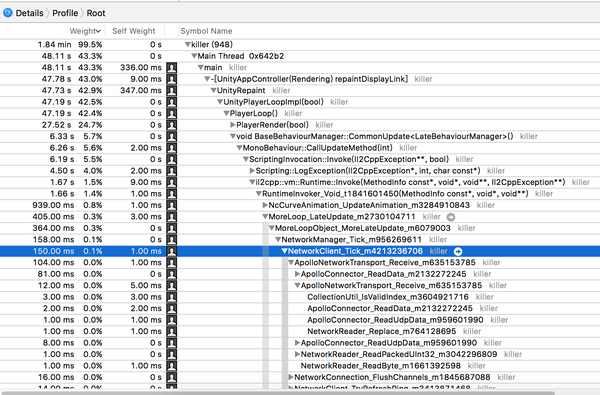 Instruments Time Profiler
Instruments Time Profiler
Unity使用/机制优化小结
GameObject的SpawnPool应支持“移出屏幕”功能
GameObject(比如特效)可能会被频繁的在“使用中”、“不使用”的状态间切换。我们的SpawnPool不应过快地把“刚刚不使用”的GameObject立刻Deactivate掉,否则会引起不必要的Deactivate/Activate的性能消耗。应有一个“从热变冷”的过程:“刚刚不使用”只是移出屏幕;只有“不使用一段时间”的GameObject,才会得以Deactivate。可能的实现方式如下:
/// On each timer, we try to make parts of "hot" items to be "cool" by deactivating them.
internal void OnTimer()
{
if(teleportCache.items.Count > 0) {
if(Time.realtimeSinceStartup - teleportCache.lastSpawnTime < SpawnPool.TeleportThenDeactivateDuration &&
teleportCache.items.Count <= 3) {
this.MoreLogInfo("this prefab is recently spawned, and the teleport cache is not too large, we don‘t deactivate these remaining items");
}
else {
int deactivateCount = Mathf.Max(1, teleportCache.items.Count / 3);
SpawnIdentity oneId;
while(deactivateCount > 0) {
--deactivateCount;
oneId = teleportCache.items.Pop();
if(null != oneId) {
this.MoreLogInfo("Deactivate from teleportCache:" + oneId);
oneId.gameObject.MoreSetActive(false, this);
oneId.gameObject.transform.SetParent(null, true);
deactivateCache.Push(oneId);
SpawnPoolProfiler.AddDeactivateCount(oneId.gameObject);
}
}
}
}
}
Transform的孩子不应过多
当Transform包含不该有的孩子Transform或其他组件时,为该Transform进行position、rotation赋值,会引起消耗,特别是包含粒子系统的时候。
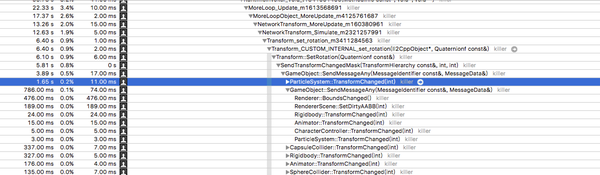 对Transform进行rotation赋值时,由于其孩子包含粒子系统所产生的消耗
对Transform进行rotation赋值时,由于其孩子包含粒子系统所产生的消耗
但考虑到切换Transform的parent本身也会有消耗,因此,我们对此也应有“从热变冷”的过程:“刚刚不使用”依然保留在父亲Transform里;只有“不使用一段时间”的GameObject,才从父亲Transform移出。
应减少粒子系统的Play()的调用次数
每次调用ParticleSystem.Play()都会有消耗,如果粒子系统本身没有明显“前摇”阶段,应先检查ParticleSystem.isPlaying,例子如下:
ParticleSystem ps;
for (int i = 0; i < num; ++i) {
//m_particleSystemLst[i].Stop();
ps = m_particleSystemLst[i];
/// CAUTION! WE SHOULD CHECK isPlaying before calling Play()! OR, IT WILL AFFECT PERFORMANCE!
if(!ps.isPlaying) {
ps.Play();
}
}
应减少每帧Material.GetXX()/Material.SetXX()的次数
每次调用Material.GetXX()或Material.SetXX()都会有消耗,应减少调用该API的频率。比如使用C#对象变量来记录Material的变量状态,从而规避Material.GetXX();在Shader里把多个uniform half变量合并为uniform half 4,从而把4个Material.SetXX()调用合并为1个Material.SetXX()。
应使用支持Conditional的日志输出机制
简单使用Debug.Log(ToString() + "hello " + "world");,其实参会造成CPU消耗及GC。使用支持Conditional的日志输出机制,则无此问题,只需在构建时,取消对应的编译参数即可。
/// MoreDebug.cs,带Conditional条件编译的日志输出机制
[Conditional("MORE_DEBUG_INFO")]
public static void MoreLogInfo(this object caller) { DoMoreLog(MoreLogLevel.Info, false, caller); }
/// 用户代码.cs,调用方简单正常调用即可。正式构建时,取消MORE_DEBUG_INFO编译参数。
this.MoreLogInfo("writerSize=" + writer.Position, "channelId=" + channelId);
脚本优化小结
依然需要减少GetComponent()的频率
即使在Unity5.5中,GetComponent()会有一定的GC产生,有少量的CPU消耗。如有可能,我们依然需要规避冗余的GetComponent()。另,自Unity5起,Unity已就.transform进行了cache,我们不需再为.transform担心,见《UNITY 5: API CHANGES & AUTOMATIC SCRIPT UPDATING》最后一段。
应减少UnityEngine.Object的null比较
因为Unity overwrite掉了Object.Equals(),《CUSTOM == OPERATOR, SHOULD WE KEEP IT?》也说过unityEngineObject==null事实上和GetComponent()的消耗类似,都涉及到Engine层面的机制调用,所以UnityEngine.Object的null比较,都会有少许的性能消耗。对于基础功能、调用栈叶子节点逻辑、高频功能,我们应少null比较,使用assertion来处理。只有在调用栈根节点逻辑,有必要的时候,才进行null比较。

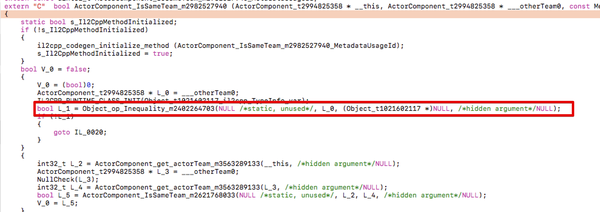 上面C#代码对应的IL2CPP代码
上面C#代码对应的IL2CPP代码
而且,从代码质量来看,无脑的null保护也是不值得推崇的,因为其将错误隐藏到了更偏离错误根源的逻辑。理论上,当错误发生了,应尽早报错,从而帮助开发者能更快速地定位错误根源。所以,多用assertion,少用null保护,无论是对代码质量,还是代码性能,都是不错的实践。
应减少不必要的Transform.position/rotation等访问
每次访问Transform.position/rotation都有相应的消耗。应能cache就cache其返回结果。
应尽量减少创建C#堆内存对象
建议使用成员变量,或者Pool来规避高频创建C#堆内存对象的创建。而且堆内存对象创建本身就是个相对较慢的过程。
应为struct对象重载所有object函数
为了普适性,C#的struct的默认Equals()、GetHashCode()和ToString()都是较慢实现,甚至涉及反射。用户自定义的struct,都应重载上述3个函数,手动实现,比如:
public struct NetworkPredictId{
int m_value;
public override int GetHashCode(){
return m_value;
}
public override bool Equals(object obj){
return obj is NetworkPredictId && this == (NetworkPredictId)obj;
}
public override string ToString(){
return m_value.ToString();
}
public static bool operator ==(NetworkPredictId c1, NetworkPredictId c2){
return c1.m_value == c2.m_value;
}
public static bool operator !=(NetworkPredictId c1, NetworkPredictId c2){
return c1.m_value != c2.m_value;
}
}
如果可能,尽量用Queue/Stack来代替List
我们会习惯用List来实现数据集合的需求。但好一些情况下,我们事实上是不需对其进行随机访问,而仅仅是“增加”、“删除”操作。此时,我们应该使用增删复杂度都是O(1)的Queue或者Stack。
注意List常用接口复杂度
Add()常为O(1)复杂度,但超过Capacity时,为O(n)复杂度。故我们应注意合理地设置容器的初始化Capacity。
Insert()为O(n)复杂度。
Remove()为O(n)复杂度。RemoveAt(index)为O(n)复杂度,n=(Count - index)。故建议移除时应优先从尾部移除。当批量移除时,miloyip亦指出RemoveRange提高移除效率。
/// remove not exsiting items in O(n)
int oldCount = m_items.Count;
int newCount = 0;
Item oneItem;
for(int i = 0; i < oldCount; ++i){
oneItem = m_items[i];
if(CheckExisting(oneItem)){
m_items[newCount] = oneItem;
++newCount;
}
}
m_items.RemoveRange(newCount, removeCount);
应注意容器的初始化capacity
同理如上条目。另,Capacity增长时,除了O(n)的复杂度,也有GC消耗。
应尽量为类或函数声明为sealed
IL2CPP就sealed的类或函数会有优化,变虚函数调用为直接函数调用。详见《IL2CPP OPTIMIZATIONS: DEVIRTUALIZATION》。
C#/CPP interop时,不需为blittable的变量声明为MarshalAs
某些数值类型,托管代码和原生代码的二进制表达方式一致,这些称为blittable数值类型。blittable数值类型在interop时为高效的简单内存拷贝,故应值得推崇。C#中的blittable数值类型为byte、int、float等,但注意不包括常用的bool、string。仅有blittable数值类型组成的数组或struct,也为blittable。
blittable的变量不应声明MarshalAs。
比如下面代码,
[DllImport(ApolloCommon.PluginName, CallingConvention = CallingConvention.Cdecl)]
private static extern ApolloResult apollo_connector_readUdpData(UInt64 objId, /*[MarshalAs(UnmanagedType.LPArray)]*/ byte[] buff, ref int size);
注释前后的IL2CPP代码如下图,右侧明显避免了marhal的产生。
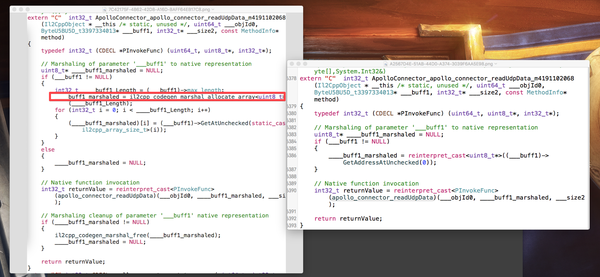
详见《IL2CPP INTERNALS: P/INVOKE WRAPPERS》。
减少Dictionary的冗余访问
我们常习惯编写这样的代码:
if(myDictionary.Contains(oneKey))
{
MyValue myValue = myDictionary[oneKey];
// ...
}
但其可减少冗余的哈希次数,优化为:
MyValue myValue;
if(myDictionary.TryGetValue(oneKey, out myValue))
{
// ...
}
(TO BE CONTINUED...)
以上是关于Unity游戏项目性能优化总结 (难度3 推荐4)的主要内容,如果未能解决你的问题,请参考以下文章
Unity性能优化专题—腾讯牛人分享经验 (难度1 推荐3)