谷歌浏览器直接提取的xpath,在python中为啥无法提取相应内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌浏览器直接提取的xpath,在python中为啥无法提取相应内容相关的知识,希望对你有一定的参考价值。
你的xpath写的太长了吧,很容易出错的 内容的tr的class都是provincetr,用这个筛选容易多了,//tr[@class="provincetr"]/td/a/text() xpath不熟悉,看了下wiki写出来的,写的不好 补充,这个才算真正回答你的问题,为什么浏览器可以,但是lxml不可以 因为浏览器对不标准的html文档都有纠正功能,而lxml不会 查看page source,注意是源代码,不是developer tool那个;最后一个table并没有包含tbody,浏览器会自动补充tbody,而lxml没有这么做,所以你的xpath没有找到 参考技术A 军事家吻擞采纳苍灯XPath学习用于爬虫,感觉比beautifulsuop好用一点
XPath就是通过树结构来定位元素
获取标签下的文本是用text()
还有最大的优点是能够直接通过谷歌浏览器的开发者工具直接复制XPath路径
例如
想要获得“加粗”这两个字在当前页面的XPath路径
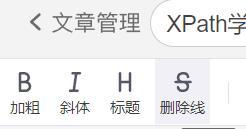
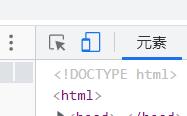
首先打开谷歌浏览器打开csdn的创作界面,然后按F12
右边出现框框的左上角的箭头点击一下之后
再去点击“加粗”
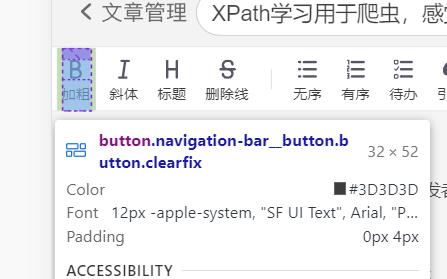
就会发现左边的框框跟着定位到了这个元素所在的html层

此时只需要单击右键选择XPath路径复制即可
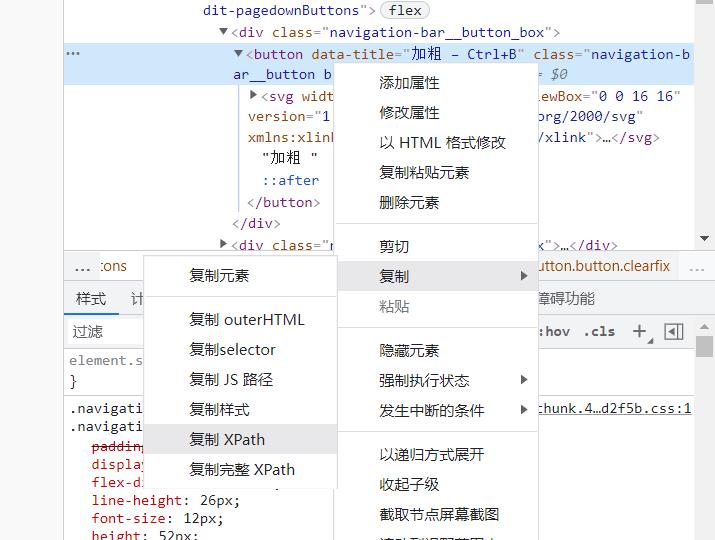
我选择完整XPath路径复制
结果如下
/html/body/div[1]/div[1]/div[2]/div/div[1]/nav/div[2]/div[1]/div[1]/button
下面学习一下XPath的一些语法(我主要用于爬虫,因此讲解的主要使用的是python中lxml包中的语法)
首先需要打开终端按一下这个lxml包
pip intsall lxml
然后毕竟实践出真知,直接上代码实例好了,自己看看运行运行马上就懂了。
# coding : utf-8
from lxml import etree
xml = '''
<book>
<name>野花</name>
<nick>臭豆腐</nick>
<div>
<nick>哈哈哈</nick>
<nick>ads</nick>
<div>
<nick href="dapao">哈哈哈hhh</nick>
<nick href="feijia">哈哈哈dahhh</nick>
</div>
</div>
</book>
'''
tree = etree.XML(xml)
# tree = etree.HTML() # 解析html时就换个名字即可,这里是xml的例子
text = tree.xpath("/book/name/text()")
print(text)
text1 = tree.xpath("/book/nick/text()")
print(text1)
text1 = tree.xpath("/book//nick/text()") # 从book的后代中寻找所有nick标签
print(text1)
text1 = tree.xpath("/book/*/nick/text()") # *为通配符,代表一层
print(text1)
text1 = tree.xpath("/book/div/nick[1]/text()") # 索引
print(text1)
text1 = tree.xpath("/book/div/div/nick[@href='dapao']/text()") # 属性选取
print(text1)
text1 = tree.xpath("/book/div/div/nick/@href") # 属性值获取
print(text1)
nick_list = tree.xpath("/book/div/div")
for nick in nick_list:
print(nick.xpath("./nick/text()"))
这应该是我以前b站上看的,讲的蛮好的。
以上是关于谷歌浏览器直接提取的xpath,在python中为啥无法提取相应内容的主要内容,如果未能解决你的问题,请参考以下文章