爬取中国大学排行榜
Posted wt714
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取中国大学排行榜相关的知识,希望对你有一定的参考价值。
功能实现
1.输入:大学排名url链接
2.输出:大学排行信息
所用到的库:BeaitifulSoup,requests
程序结构设计
步骤一:利用requests获取网页内容
步骤二:利用bs4提取网页内容信息到合适的数据结构
步骤三:在屏幕上打印出来
建立三个函数,将其分为三个模块。这样能够使代码更加清晰易读,维护方便。
函数一:gethtmlText()- 获取网页内容
函数二:fillUnivList()-获取网页大学信息到合适的数据结构
函数三:printUnivList()-利用数据结构打印到屏幕上
下面是模板:
import requests from bs4 import BeautifulSoup def getHTMLText(url): #获取网页内容 return"" def fillUnivList(ulist,html): #提取信息,ulist列表用于储存学校信息,html为getHTMLText返回值 pass def printUnivList(ulist,num): #打印,num为要打印多少学校 print() def main(): url="http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html" html=getHTMLText(url) ulist=[] fillUnivList(ulist,html) printUnivList(ulist,30) # 打印30所学校排名 main()
接下里就可以按照模板写入相应的代码
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): #获取网页内容 try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "获取内容失败。" def fillUnivList(ulist,html): #提取信息,ulist列表用于储存学校信息,html为getHTMLText返回值 soup=BeautifulSoup(html,"html.parser") #将getHTMLText获取的内容放到一锅汤里 for tr in soup.find(‘tbody‘).children: if isinstance(tr,bs4.element.Tag): tds=tr(‘td‘) ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num): #打印,num为要打印多少学校 print("{:^10} {:^6} {:^10}".format("排名","学校名称","总分")) for i in range(num): u=ulist[i] print("{:^10} {:^6} {:^10}".format(u[0],u[1],u[2])) def main(): url="http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html" html=getHTMLText(url) ulist=[] fillUnivList(ulist,html) printUnivList(ulist,30) # 打印30所学校排名 main()
运行截图
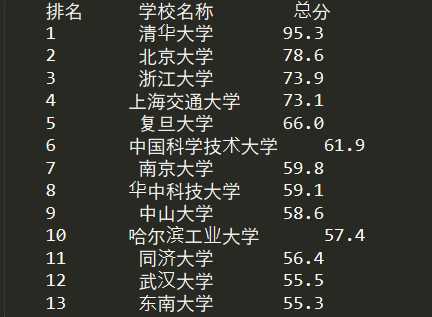
代码缺陷
得到的结果排版不工整,于是修改函数printUnivList(ulist,num),代码如下
def printUnivList(ulist, num): tplt = "{0:^10} {1:{3}^10} {2:^10}" print(tplt.format("排名","学校名称","总分",chr(12288))) for i in range(num): u=ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288)))
运行截图
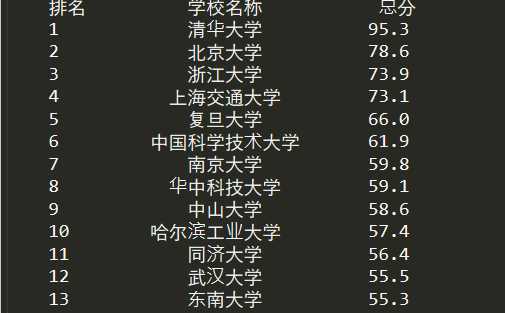
这样就好看很多啦
以上是关于爬取中国大学排行榜的主要内容,如果未能解决你的问题,请参考以下文章