python批量读取txt某列,并复制对应txt文件名?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python批量读取txt某列,并复制对应txt文件名?相关的知识,希望对你有一定的参考价值。
求大神,现在有这样的一个需求。某个文件夹每天定时会自动生成带省份_时间文件。我这边想要通过python批量读txt某列,并且把该txt文件名和这个列,保存到新的txt文本中。

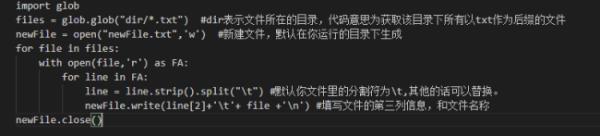
import glob
files = glob.glob("dir/*.txt") #dir表示文件所在的目录,代码意思为获取该目录下所有以txt作为后缀的文件
newFile = open("newFile.txt",'w') #新建文件,默认在你运行的目录下生成
for file in files:
with open(file,'r') as FA:
for line in FA:
line = line.strip().split("\\t") #默认你文件里的分割符为\\t,其他的话可以替换。
newFile.write(line[2]+'\\t'+ file +'\\n') #填写文件的第三列信息,和文件名称
newFile.close()
有问题可以联系我。
参考技术B 这只是业务逻辑,最好按逻辑写一下代码,遇到问题给你说怎么解决Python 3 无法读取我的 .txt 文件。我该如何解决? [复制]
【中文标题】Python 3 无法读取我的 .txt 文件。我该如何解决? [复制]【英文标题】:Python 3 cannot read my .txt file. How do I solve it? [duplicate] 【发布时间】:2020-04-17 21:10:19 【问题描述】:python 3 无法读取我的文件。该文件是一个孟加拉语单词数据库。我写了以下代码:
x = open('c:\\BengaliWordList_112.txt').read()
代码显示以下错误:
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-12-0b3d4d6e7768> in <module>
----> 1 x = open('c:\\BengaliWordList_112.txt').read()
~\Anaconda3\lib\encodings\cp1252.py in decode(self, input, final)
21 class IncrementalDecoder(codecs.IncrementalDecoder):
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
25 class StreamWriter(Codec,codecs.StreamWriter):
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 28: character maps to <undefined>
【问题讨论】:
是的,它有帮助。谢谢! 【参考方案1】:试试这个:
x = open('c:\\BengaliWordList_112.txt', encoding='utf-8').read()
【讨论】:
这行得通。谢谢。以上是关于python批量读取txt某列,并复制对应txt文件名?的主要内容,如果未能解决你的问题,请参考以下文章