网络协议-P2P协议
Posted mingjie-c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络协议-P2P协议相关的知识,希望对你有一定的参考价值。
网络协议-P2P协议
HTTP协议下电影为啥会很慢?
FTP文件传输协议
采用两个TCP 连接来传输一个文件。
-
控制连接:服务器端被动连接,端口是21,由客户端发起。命令从客户端传给服务器,服务器传回的应答。
常见命令:list 获取目录、reter 取文件、store 存文件。
-
数据连接:当每一个文件在客户端与服务器之间传输时,就创建一个数据连接。
FTP 的两种工作模式
-
主动模式:主动是相对于服务端来说的。
-
客户端要先建立控制连接,它随机打开一个大于1024的端口N,与服务器的21端口连接,并告诉服务端,数据连接的端口是N+1。
-
服务端主动将自己的数据端口20,与客户端的N+1端口连接,构成数据连接。
-
-
被动模式:被动也是相对于服务端来说的。
-
客户端打开两个大于1024的端口,N和 N+1。客户端的N端口与服务端的21连接,发一个PASV 命令,服务端接到命令后打开一个大于1024的端口P,返回“227 entering passive mode”消息,这个消息里有服务端的数据连接端口。
-
客户端N端口接到服务端的消息后,将N+1端口连接服务器的端口P,构建数据连接。
-
FTP有个缺点就是单一服务器的带宽有限。因为它使用传统的客户端、服务器的方式。服务器集群的方式本质是一样的。也不是最好的解决办法。
P2P 是什么
P2P 就是 peer-to-peer,资源不是集中存在一个设备上的,是分散在多个设备上。这些设备我们称为peer。
要下载一个文件时,是与这些peer文件的设备连接,下载完后你也是众多peer中的一个。这样做的好处是不需要到某个固定服务器上去下载,在离你最近的那个有peer文件的设备上下载。
当你使用P2P软件时,例如BitTorrent,往往能够看到既有下载流量,也有上传流量。这种方式,参与的人越多,下载速度越快。
种子(.torrent)文件
我们经常提到的种子是啥呢?
这个种子,.torrent 文件是由两部分组成,分别是:announce(tracker URL)和文件信息。
文件信息里面有这些内容:
-
info区:这里指定的是该种子有几个文件、文件有多长、目录结构、以及目录和文件的名字。
-
name 字段:指定顶层目录名字。
-
每个段的大小:BitTorrent(简称BT)协议把一个文件分成很多小段,然后分段下载。
-
段哈希值:将整个种子中,每个段的SHA-1 哈希值拼在一起。
当你要下载电影时,你需要把.torrent 文件解析一下,取出tracker地址,然后连接tracker服务器。
从tracker服务器那获取其他下载者和上传者的地址。然后你的设备就可以和其他有peer文件块的设备连接了。
.torrent文件中除了tracker服务器地址还有设备本地已经有的peer块,这样就能交换对方没有的数据。
此时数据的传输是设备和设备之间的数据通信,不需要服务器参与。
这个过程特别依赖tracker服务器,tracker服务器要是挂了那众多的BT客户端就下载不了资源了。
去中心化网络(DHT)
DHT 是Distributed Hash Table 的缩写,译为中文的意思是去中心化网络。每个加入DHT网络的人,必须要存储网络上所有成员的联系信息,和网络资源信息。每个人都是一个中心,不管访问谁都能获取网络上所有的信息。
Kademlia 协议,是DHT 协议的一种。概念和区块链一样。
每个BitTorrent 有两个角色,一个是peer,tcp通信,用来上传和下载文件。一个是DHT node端口,udp通信,这个节点加入一个DHT的网络。
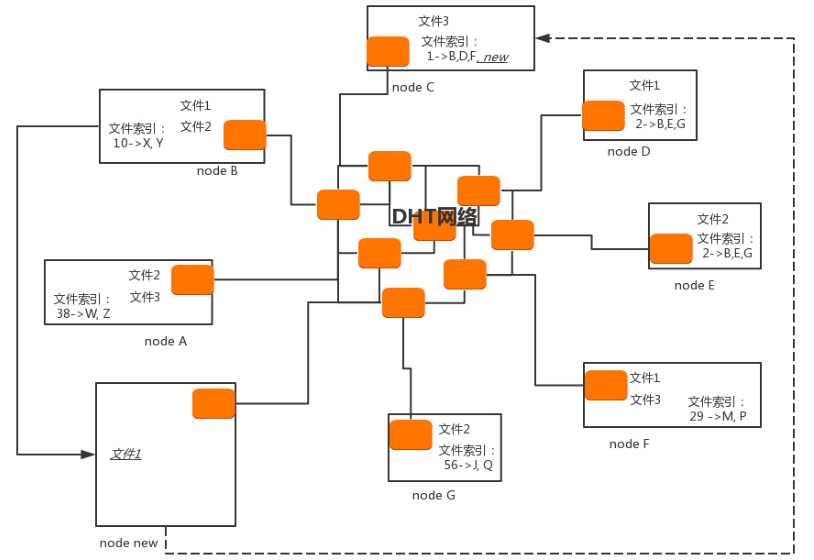
在DHT 网络里,每一个DHT node 都有一个ID。每个DHT node都有责任掌握一些知识,也就是文件索引。DHT node会记录哪些文件保存在哪些节点上。
哈希值
哈希值就是Node ID 和 文件之间关系的纽带。每个文件可以计算出一个 Hash 值,这个 Hash 值等于某个 Node ID。和这个文件的 Hash值相同的Node ID 有责任知道这个文件在哪,并且和它的 ID值近似的 Node也要知道这个文件在哪。
这样每个Node 不必知道整个DHT 网络中所有文件的各自位置,只要知道和它自己ID相同的hash 值文件,以及和它ID近似的hash 值文件就可以了。
接下来想一想一个新节点上线后的过程。
一个新节点node new上线了,如果想下载文件1,它首先要加入DHT 网络。这时就需要.torrent文件了,文件里面保存的就不再是.torrent 服务器的地址了,它保存的是文件1 相关的 node 地址列表。这些node 有的可能还在线上,有的可能已经下线了。只要有一个还在线上你就能和它连接,连上了就加入了DHT 网络。
node new 会计算文件1 的哈希值,并根据这个哈希值找到对应的Node ID,或者和这个Node ID近似的node。假如node new 计算出了哈希值,并通过这个hash 值找到了node A,那node new 是如何与 node A 连接的呢?
这个过程很像人肉搜索,node new 通过已经连接的 node 向其他node 转发这个消息,“我要找node A“。这个消息通过一传十十传百,最终找到了 node A。但是node A回给的消息是 - ”这个文件不在我这,它在node B 、C、D、E上,这有它们的地址,你去找它们任何一个下载吧“。于是node new 用这个地址联系到node c,恰巧node c 还在线上,所以node new 和node C 建立了连接,下载文件1 开始了。
但是下载到99%,node C 它下线了,数据来源没有了,node new只好去找node B、D、E,恰巧它们也下线了,那下载文件1就只能停在99%不动了。当然发生这种情况还是挺少见的。
当node new 下载好文件1 后,它也是拥有文件1 成员的一份子了,它要把自己的地址告诉 node A,成为文件1 下载源中的一份子。
回过头来看一下几个名词
node ID 是一个 随机选择的 160bits (20字节)空间,文件的哈希也使用这样的 160bits 空间。
ID 相似 是通过异或(XOR)计算的。在Kademlia 网络中,位置近不算近,ID近才算近。
举个例子:01010 与 01000 的距离,就是两个ID之间的异或值,为00010,就是2。01010 与 00010 的距离为 01000,就是8。2 和 8表示距离的远近。
领英中,它的用户ID如果是5位,第一位表示第一份工作在哪,第二位表示第二份工作在哪,工作排完之后才是,研究生学历,然后是本科学历。猎头在找人时也是按照这个顺序找的,学历在工作经历越长的应聘者哪里越不重要。
DHT 网络中朋友圈
一个node 它在DHT 网络中也像人在社会关系网中一样,和其他node 的远近也是分层的。和自己最亲密的可能就那么几个,再扩一点没那么亲密但是还联系的就更多一点,还有更多的只有联系方式却不联系的。DHT 网络中的node 是按与自己node ID 相近程度来区分和自己关系远近的。
例如一个node 的ID 是01101,和它最近的就是 01100。异或值为00001,也就是距离为1,这一层叫 ”k-bucket 1"。接下来就是 0111X,这样的节点有两个,亦或值为00010,距离为2,这一层叫“k-bucket 2”。
如果一个node 的ID,前面所有位数相同,从倒数第1 位开始不同,这样的节点只有 2^(i-1)个,这一层叫“k-bucket i”。
DHT 网络是如何找朋友的?
这个找朋友的过程就是二分法查找,我们举个例子就明白了。
假设node A 的ID 是00110, 它想找 node F,F 的ID 是10000,异或值是 10110,距离范围是[2^4 , 2^5),这个目标是在 “k-bucket 5”中,这就说明F 的ID 与A 的 ID 从第5位开始不同。
A 首先会看自己的 “k-bucket 5” 中有没有F,如果有那就找到了,如果没有就得问 “k-bucket 5” 中的一个node ,假设是node C。node C 在找F 时范围就缩小了,因为C 的第五位和 F 的一致。C 与F 的距离会小于 2^4。相比于A 和F之间的距离缩短了 一半。
C 会计算它与 F 的异或值,在自己的 “k-bucket i”中找F,如果也没有就找第i层的 E。E 的距离会比C 到F 的距离小一半。对于总的节点数目为N的网络,最多只需要查询log2(N)次,就能找到。
如果这个N 是一亿数量级的化,二分法查找最多也只要32 次就能找到。
小结
下载文件可以用HTTP 和 FTP,它们是集中下载的方式,而P2P则换了一种思路,采用非中心化下载。
P2P 分为两种,一个是依赖于 tracker 的,元数据集中,但是文件数据分散;另一种是基于分布式的哈希算法,元数据和文件数据都分散。
以上是关于网络协议-P2P协议的主要内容,如果未能解决你的问题,请参考以下文章