最小错误率贝叶斯分类器
Posted yuyaweibest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最小错误率贝叶斯分类器相关的知识,希望对你有一定的参考价值。
摘要:本次实验的主要内容是编程实现一个可以对两类模式样本进行分类的贝叶斯分类器,其中假设两个模式类的条件概率分布均为高斯分布。本次实验自定义一个函数self_mvnrnd(varargin) ,输入8个参数,其中,参数1,2,3,4分别为一类模式样本的均值矢量,协方差矩阵,样本数,先验概率,参数5,6,7,8分别为另一类模式样本的均值矢量,协方差矩阵,样本数,先验概率。最后,调用self_mvnrnd()函数可以用最小错误率贝叶斯分类器对其进行分类,统计正确分类的百分比,并在二维图上用不同的颜色画出正确分类和错分的样本。
一、 技术论述


二、 实验步骤及实验结果
1、基本实验
(1) 生成两类模式样本,模式类1的均值矢量为m1=(1,3)T,协方差矩阵为S1=(1.5,0;0,1),模式类2的均值矢量为m2=(3,1)T,协方差矩阵为S2=(1,0.5;0.5,2),先验概率P(w1)=P(w2)=0.5。在MATLAB中为两个模式类各生成100个随机样本点,并在一幅图中分别用蓝色和绿色画出这两类样本的二维散点图,其中红色的上三角形表示第一类错误分为第二类,红色的下三角形表示第二类错误分为第一类,实验结果如图1所示:
具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[3,1],[1,0.5;0.5,2],100,0.5)
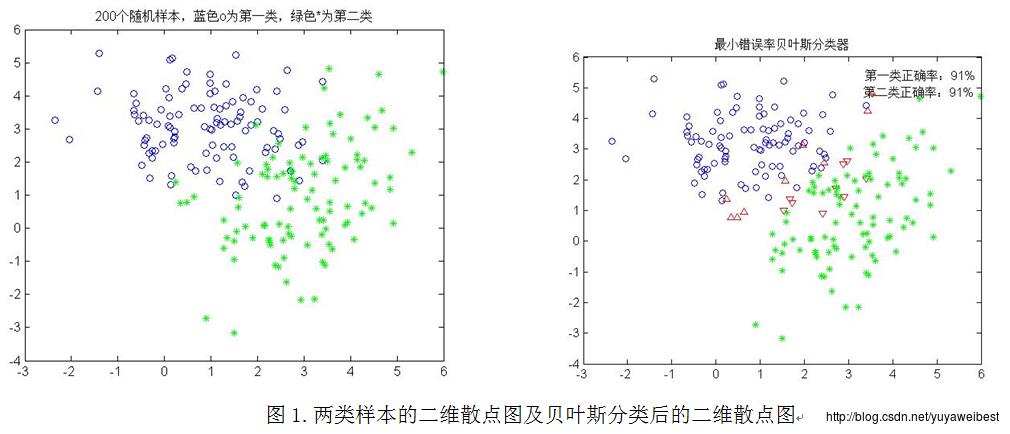
从图1分类后的二维散点图可知正确分类的百分比:第一类为91%,第二类为91%。
(2) 改变先验概率P(w1)=0.4,P(w2)=0.6,对上述200个样本重新进行分类,实验结果如下图2所示:
改变先验概率,具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[3,1],[1,0.5;0.5,2],100,0.6)
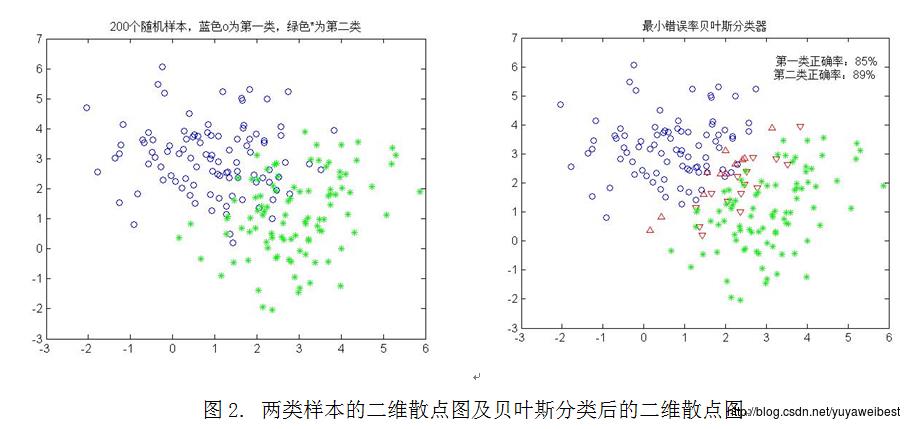
从图2可以看出,正确分类的百分比:第一类为85%,第二类为89%。
2、 扩展实验
(1) 在上述基本实验中,协方差矩阵不变,但类均值向量分别变为m1=(1,3)T,m2=(2,2)T,重新进行基本实验中(1)、(2)、(3)的实验,得到实验结果如下图3所示:
具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[2,2],[1,0.5;0.5,2],100,0.5)
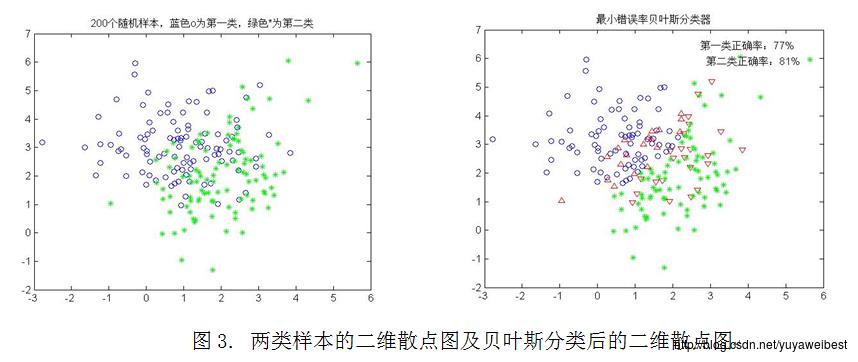
从图3可以看出正确分类的百分比:第一类为77%,第二类为81%。
改变先验概率,具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[2,2],[1,0.5;0.5,2],100,0.6)
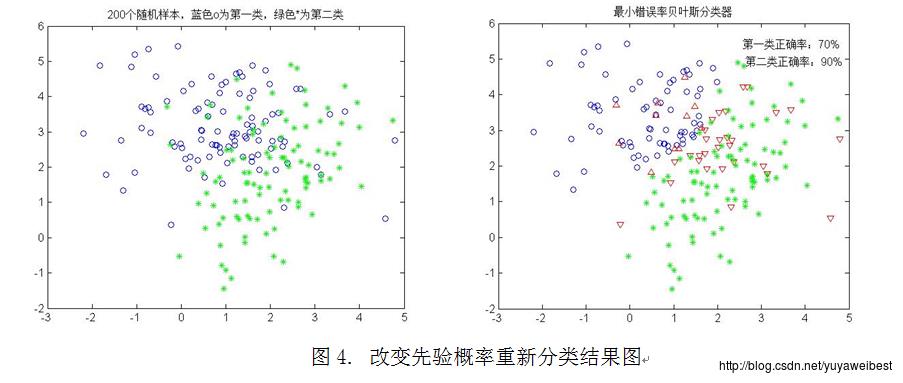
从图4可以看出正确分类的百分比:第一类为70%,第二类为90%。
(2) 在1实验中,协方差矩阵不变,但类均值向量分别变为m1=(1,3)T,m2=(4,0)T,重新进行基本实验中(1)、(2)、(3)的实验,得到实验结果如下图5所示:
具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[4,0],[1,0.5;0.5,2],100,0.5)
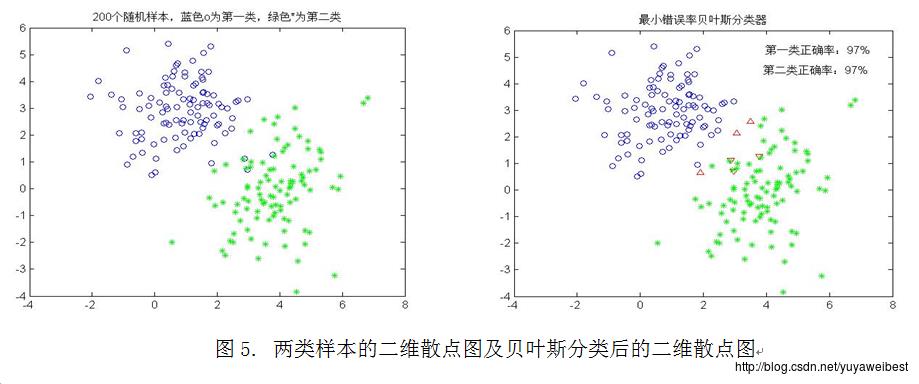
从图5可以看出正确分类的百分比:第一类为97%,第二类为97%。
改变先验概率,具体调用函数:self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[4,0],[1,0.5;0.5,2],100,0.6)
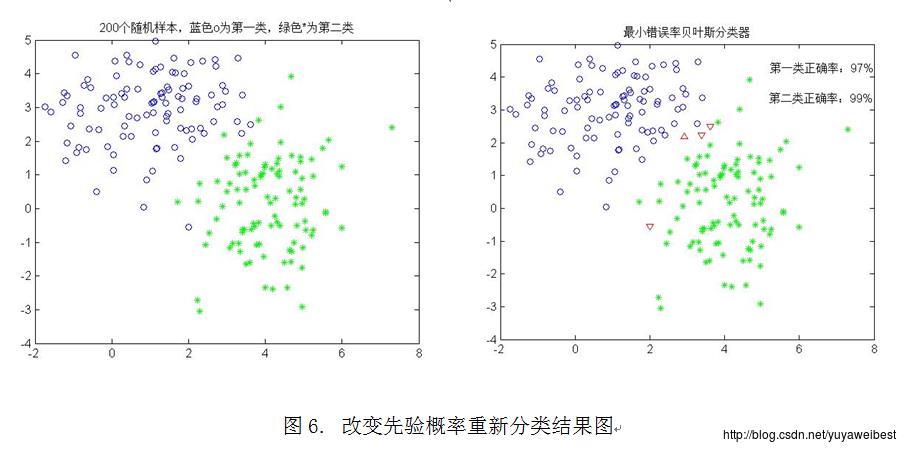
从图6可以看出正确分类的百分比:第一类为97%,第二类为99%。
(3)在1实验中,两个类均值向量不变,但协方差矩阵分别变为S1=(1.5,1;1,1),S2=(1,0.5;0.5,2)重新进行基本实验中(1)、(2)、(3)的实验,实验结果如下图7所示:
具体调用函数:self_mvnrnd([1 3],[1.5,1;1,1],100,0.5,[3,1],[1,0.5;0.5,2],100,0.5)
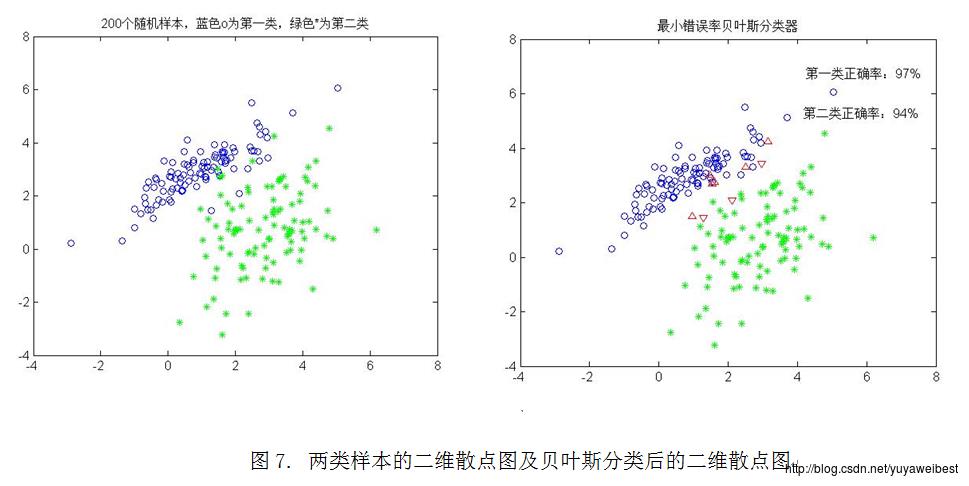
从图7可以看出正确分类的百分比:第一类为97%,第二类为94%。
改变先验概率,具体调用函数:self_mvnrnd([1 3],[1.5,1;1,1],100,0.4,[3,1],[1,0.5;0.5,2],100,0.6)
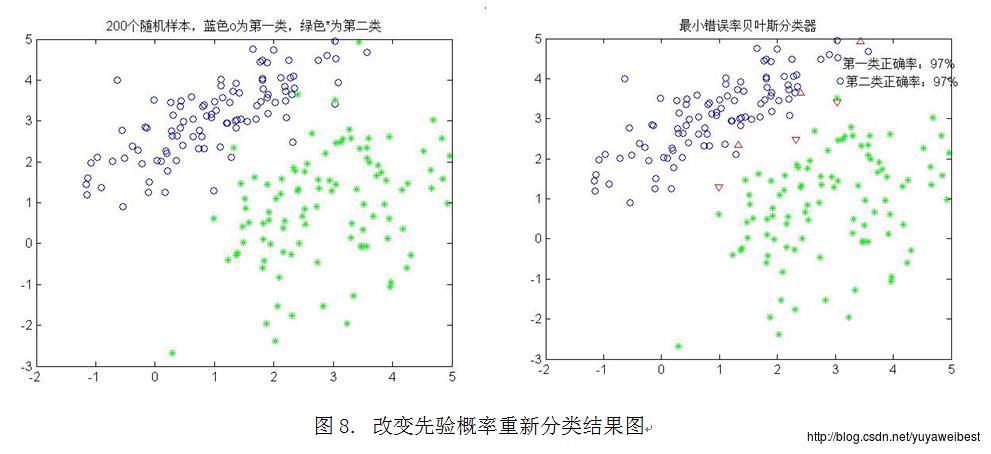
从图8可以看出正确分类的百分比:第一类为97%,第二类为97%。
三、 实验结果讨论
1.先验概率问题:由公式(1-2)与公式(1-3)可知,改变了先验概率P(w)使得判决函数gj(x)发生变化,分类的正确率也相应的发生了变化。对比图1与图2,图3与图4,图5与图6,图7与图8,可以发现,P(w1)由原来的0.5减小到0.4,第一类样本的分类正确率也减小了;P(w2)由原来的0.5增大到0.6,第二类样本的分类正确率也增大了,即最优判决偏向于先验概率较大的类别。
2.类均值向量问题:已知均值表示许多样本的代数平均值,服从多元正态分布的数据样本趋向于聚集在均值向量的周围。在图1、图3及图5中第一类样本的均值向量均为m1=(1,3)T,而第二类样本的均值向量分别为m2=(3,1)T、(2,2)T、(4,0)T。m1与m2的平方距离 分别为8、2、18,因此生成的两类样本之间密集程度不同。从图1与图3的对比中可以发现,越密集分类的正确率越低;从图3与图8的对比中可以发现,两类样本分得越开,分类的正确率越高。
3.协方差矩阵问题:图1与图7中两个类样本均值向量不变,但协方差矩阵由S1=(1.5,0;0,1)变为S1=(1.5,1;1,1),S2不变,S1由对角矩阵变成非对角矩阵。可以看到第一类样本的分布形状发生了变化而第二类样本的分布形状未变,可知样本的分布形状决定于其协方差矩阵。
附录:
%基础实验
self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[3,1],[1,0.5;0.5,2],100,0.5)
self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[3,1],[1,0.5;0.5,2],100,0.6)
%拓展实验(e)
self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[2,2],[1,0.5;0.5,2],100,0.5)
self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[2,2],[1,0.5;0.5,2],100,0.6)
%拓展实验(f)
self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[4,0],[1,0.5;0.5,2],100,0.5)
self_mvnrnd([1 3],[1.5,0;0,1],100,0.4,[4,0],[1,0.5;0.5,2],100,0.6)
%拓展实验(g)
self_mvnrnd([1 3],[1.5,1;1,1],100,0.5,[3,1],[1,0.5;0.5,2],100,0.5)
self_mvnrnd([1 3],[1.5,1;1,1],100,0.4,[3,1],[1,0.5;0.5,2],100,0.6)
%功能:函数输入参数为8,画出二类样本的二维散点图和贝叶斯分类后的二维散点图
%参数1,2,3,4分别为一类模式样本的均值矢量,协方差矩阵,样本数,先验概率;
%参数5,6,7,8分别为另一类模式样本的均值矢量,协方差矩阵,样本数,先验概率;
%例子:self_mvnrnd([1 3],[1.5,0;0,1],100,0.5,[3,1],[1,0.5;0.5,2],100,0.5)
function self_mvnrnd(varargin)%可自定义参数的函数
if(nargin==8)%判定输入参数是否为8
w1=mvnrnd(varargin1,varargin2,varargin3);%第一类
w2=mvnrnd(varargin5,varargin6,varargin7);%第二类
figure(1);
plot(w1(:,1),w1(:,2),'bo');%蓝色o为第一类
hold on
plot(w2(:,1),w2(:,2),'g*');%绿色*为第二类
title('200个随机样本,蓝色o为第一类,绿色*为第二类');
w=[w1;w2];
n1=0;%第一类正确个数
n2=0;%第二类正确个数
figure(2);
%贝叶斯分类器
for i=1:(varargin3+varargin7)
x=w(i,1);
y=w(i,2);
g1=mvnpdf([x,y],varargin1,varargin2)*varargin4;
g2=mvnpdf([x,y],varargin5,varargin6)*varargin8;
if g1>g2
if 1<=i&&i<=varargin3
n1=n1+1;%第一类正确个数
plot(x,y,'bo');%蓝色o表示正确分为第一类的样本
hold on;
else
plot(x,y,'r^');%红色的上三角形表示第一类错误分为第二类
hold on;
end
else
if varargin3<=i&&i<=(varargin3+varargin7)
n2=n2+1;%第二类正确个数
plot(x,y,'g*');%绿色*表示正确分为第二类的样本
hold on;
else
plot(x,y,'rv');%红色的下三角形表示第二类错误分为第一类
hold on;
end
end
end
r1_rate=n1/varargin3;%第一类正确率
r2_rate=n2/varargin7;%第二类正确率
gtext(['第一类正确率:',num2str(r1_rate*100),'%']);
gtext(['第二类正确率:',num2str(r2_rate*100),'%']);
title('最小错误率贝叶斯分类器');
else disp('只能输入参数个数为8');
end
以上是关于最小错误率贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章