MyBatis总结
Posted otonashi129
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyBatis总结相关的知识,希望对你有一定的参考价值。
MyBatis
支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手工设置参数以及抽取结果集。MyBatis 使用简单的 XML 或注解来配置和映射基本体,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
MyBatis对应关系
一对一 任意一方的类中加入另一个类作为其属性,mapper.xml文件中使用resultMap,对象成员使用
一对多 在一的一方加入多的一方,mapper.xml文件中使用resultMap,对象成员使用
多对多 分别加入对方的类对象作为属性,通过建立中间表连接sql语句
MyBatis与Hibernate区别
Hibernate是面向对象开发,不能开发比较复杂的业务。适合需求变化较少的项目,比如ERP,CRM等等,由于使用hql,要先把hql转化成sql再进行执行,执行效率变低。生成的sql语句格式不容易维护,自动生成sql语句,我们无法控制该语句,我们就无法去写特定的高效率sql,完全是由Hibernate来管理数据表的关系。MyBatis的sql都是写在xml里,因此优化sql比hibernate方便很多,可以自由书写SQL、支持动态SQL、处理列表、动态生成表名,支持存储过程。这样就可以灵活地定义查询语句,满足各类需求和性能优化的需要,这些在互联网系统中是十分重要的。Hibernate虽有hql,但功能还是不及sql强大,遇到复杂需求时,hql也有局限;hibernate虽然也支持原生sql,但开发模式上却与orm不同,因此使用上不是非常方便。总之写sql的灵活度上Hibernate不及mybatis。
Hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而MyBatis则除了基本记录功能外,功能薄弱很多。
Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存。而MyBatis在使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(Oracle、mysql等)的耦合性,而MyBatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
MyBatis工作原理:
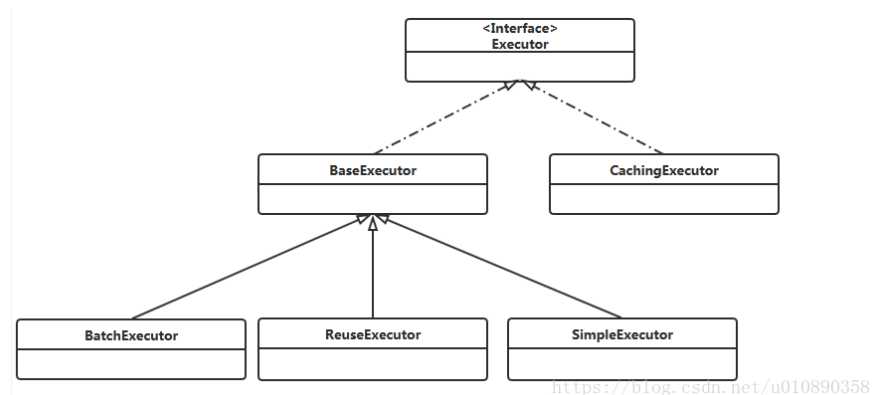
读取配置文件,创建InputStream流对象;
解析InputStream流对象获得Configuration对象,然后用其创建SqlSessionFactory对象;
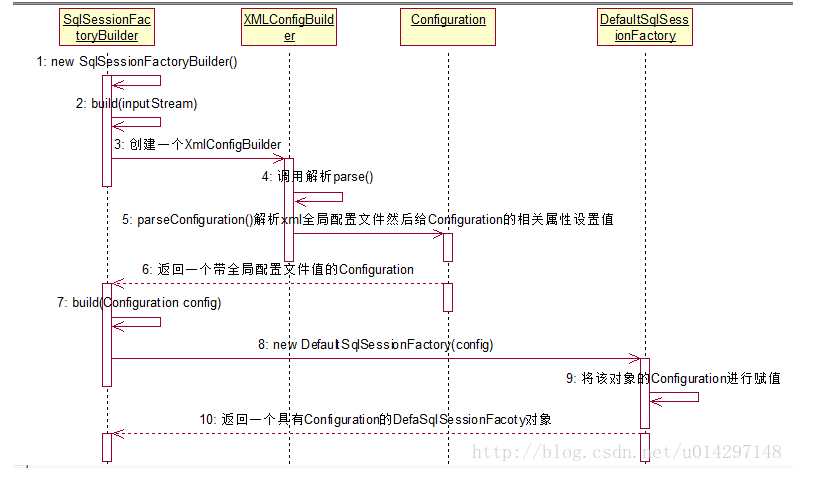
调用SqlSessionFactory的openSession方法,先创建事务工厂TransactionFactory,再从事务工厂中创建事务和执行器Executor;
根据执行器创建并返回SqlSession对象;
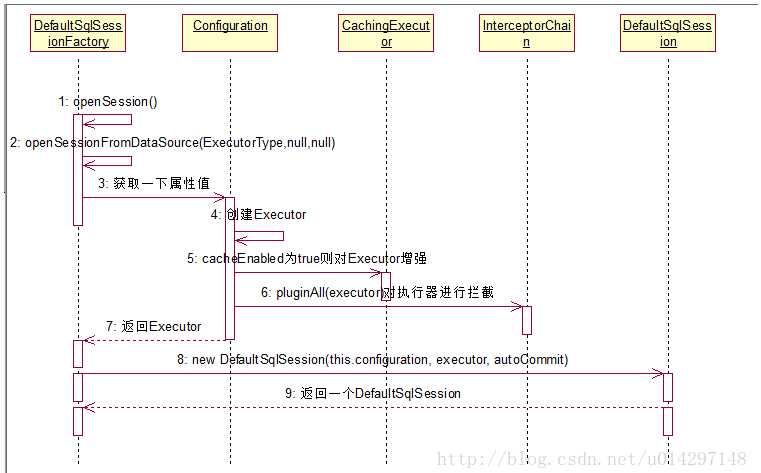
从SqlSession调用Exccutor执行数据库操作,过程中会把Statement转为ParameterStatement;
对查询结果二次封装;
提交事务,先调用对象本身的commit(),然后调用CachingExecutor的Commit,再调用BaseExecutor的commit,最后调用JDBCTransaction的commit方法。
MyBatis防注入:
#{}是预编译处理,({}是字符串替换。 Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值; Mybatis在处理){}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
模糊查询防注入:select * from table where columnName like concat(‘%‘, #{columnName}, ‘%‘);
MyBatis批量插入:
首先,创建一个简单的insert语句:
insert into names (name) values (#{value})
然后在java代码中像下面这样执行批处理插入:
list
names.add(“fred”);
names.add(“barney”);
names.add(“betty”);
names.add(“wilma”);
//executortype.batch执行器批量更新,且必要地区别开其中的select 语句,确保动作易于理解。
sqlsession sqlsession = sqlsessionfactory.opensession(executortype.batch);
try {
namemapper mapper = sqlsession.getmapper(namemapper.class);
for (string name : names) {
mapper.insertname(name);
}
sqlsession.commit();
} finally {
sqlsession.close();
}
MyBatis缓存:
一级缓存默认开启,在SqlSession层面缓存,由Executor维护,在同一个会话里面,多次执行相同的SQL语句,会直接从内存取到缓存的结果,不会再发送SQL到数据库。但是不同的会话里面,即使执行的SQL一模一样(通过一个Mapper的同一个方法的相同参数调用),也不能使用到一级缓存。
MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
一级缓存的生命周期有多长:
如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
如果SqlSession调用了clearCache()或执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
SqlSession一级缓存的工作流程:
对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果?
判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;?
如果命中,则直接将缓存结果返回;?
如果没命中:
去数据库中查询数据,得到查询结果;
将key和查询到的结果分别作为key,value对存储到Cache中;
将查询结果返回;
一级缓存的不足:
使用一级缓存的时候,因为缓存不能跨会话共享,不同的会话之间对于相同的数据可能有不一样的缓存。在有多个会话或者分布式环境下,会存在脏数据的问题。如果要解决这个问题,就要用到二级缓存。MyBatis 一级缓存(MyBaits 称其为 Local Cache)无法关闭,但是有两种级别可选:
session 级别的缓存,在同一个sqlSession 内,对同样的查询将不再查询数据库,直接从缓存中。
statement 级别的缓存,避坑:为了避免这个问题,可以将一级缓存的级别设为 statement 级别的,这样每次查询结束都会清掉一级缓存。
二级缓存
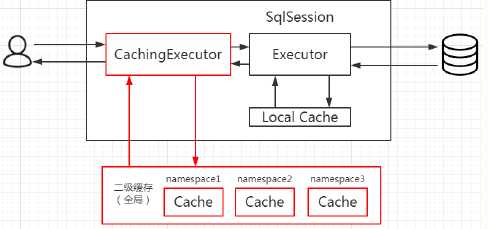
二级缓存是用来解决一级缓存不能跨会话共享的问题的,范围是namespace级别的,可以被多个SqlSession 共享(只要是同一个接口里面的相同方法,都可以共享),生命周期和应用同步。如果MyBatis使用了二级缓存,并且Mapper和select语句也配置使用了二级缓存,那么在执行select查询的时候,MyBatis会先从二级缓存中取输入,其次才是一级缓存,即MyBatis查询数据的顺序是:二级缓存 —> 一级缓存 —> 数据库。
MyBatis用了一个装饰器的类来维护,就是CachingExecutor。如果启用了二级缓存,MyBatis 在创建Executor 对象的时候会对Executor 进行装饰。CachingExecutor 对于查询请求,会判断二级缓存是否有缓存结果,如果有就直接返回,如果没有委派交给真正的查询器Executor 实现类,比如SimpleExecutor 来执行查询,再走到一级缓存的流程。最后会把结果缓存起来,并且返回给用户。
开启二级缓存的方法
第一步:配置 mybatis.configuration.cache-enabled=true,只要没有显式地设置cacheEnabled=false,都会用CachingExecutor 装饰基本的执行器。
第二步:在Mapper.xml 中配置
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
第三步,使用二级缓存对应属性类实现Serializable序列化接口
二级缓存是事务性的。这意味着,当SqlSession完成并提交时,或是完成并回滚,但没有执行flushCache=true的insert/delete/update语句时,缓存会获得更新。
Mapper.xml 配置了
事务不提交,二级缓存不存在.二级缓存使用TransactionalCacheManager(TCM)来管理,最后又调用了TransactionalCache 的getObject()、putObject 和commit()方法,TransactionalCache里面又持有了真正的Cache 对象,比如是经过层层装饰的PerpetualCache。在putObject 的时候,只是添加到了entriesToAddOnCommit 里面,只有它的commit()方法被调用的时候才会调用flushPendingEntries()真正写入缓存。它就是在DefaultSqlSession 调用commit()的时候被调用的。
在其他的session中执行增删改操作,验证缓存会被刷新
增删改操作会清空缓存,在CachingExecutor 的update()方法里面会调用flushCacheIfRequired(ms),isFlushCacheRequired就是从标签里面取到的flushCache的值。而增删改操作的flushCache属性默认为true。
支持自定义缓存。
参考地址:Mybatis工作流程及其原理与解析 https://blog.csdn.net/u010890358/article/details/80665753
Mybatis之工作原理 https://blog.csdn.net/u014297148/article/details/78696096
mybatis缓存机制 https://www.cnblogs.com/wuzhenzhao/p/11103043.html
Mybatis常见面试题总结 https://blog.csdn.net/a745233700/article/details/80977133
【持久化框架】Mybatis与Hibernate的详细对比 https://www.cnblogs.com/williamjie/p/9198987.html
mybatis和hibernate的区别 https://www.php.cn/java-article-421812.html
以上是关于MyBatis总结的主要内容,如果未能解决你的问题,请参考以下文章