哈夫曼
Posted cistineup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈夫曼相关的知识,希望对你有一定的参考价值。
学号 20182334 《数据结构与面向对象程序设计》哈弗曼实验
课程:《程序设计与数据结构》
班级: 1823
姓名: 姬旭
学号:20182334
实验教师:王志强
实验日期:2019年11月22日
必修/选修: 必修
1.实验内容
什么是哈夫曼树呢?
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
2. 实验过程及结果
例如:频率表 A:60, B:45, C:13 D:69 E:14 F:5 G:3
第一步:找出字符中最小的两个,小的在左边,大的在右边,组成二叉树。在频率表中删除此次找到的两个数,并加入此次最小两个数的频率和。
F和G最小,因此如图,从字符串频率计数中删除F与G,并返回G与F的和 8给频率表
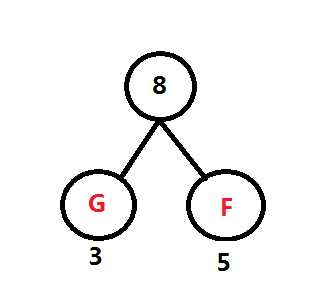
重复第一步:
频率表 A:60, B:45, C:13 D:69 E:14 FG:8
最小的是 FG:8与C:13,因此如图,并返回FGC的和:21给频率表。
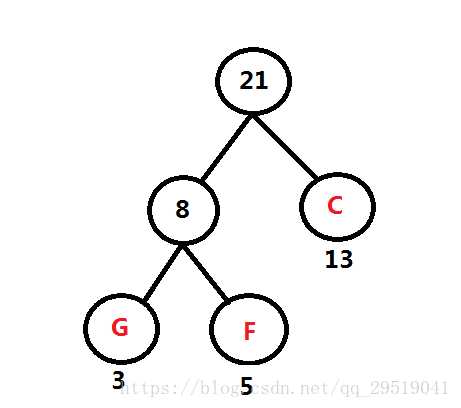
重复第一步:
频率表 A:60 B: 45 D: 69 E: 14 FGC: 21
如图
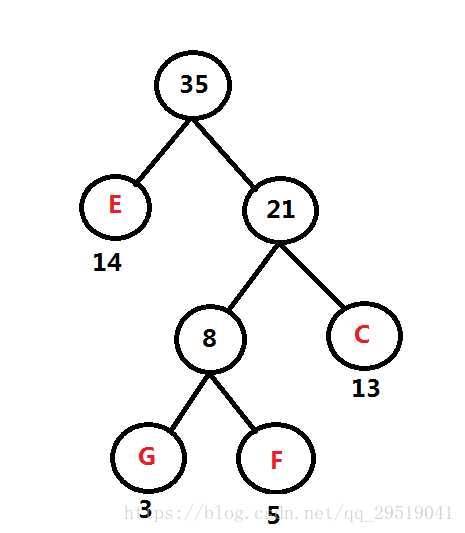
重复第一步
频率表 A:60 B: 45 D: 69 FGCE: 35
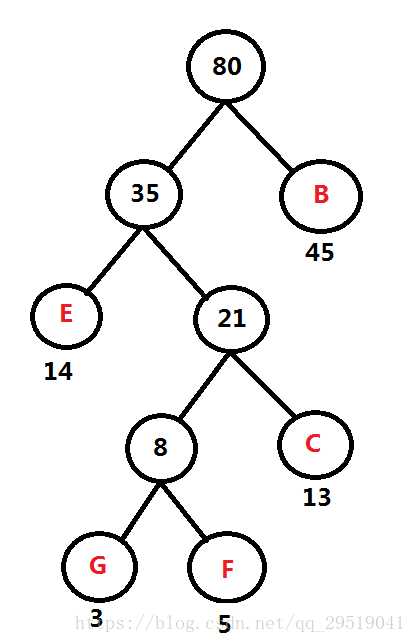
重复第一步
频率表 A:60 D: 69 FGCEB: 80
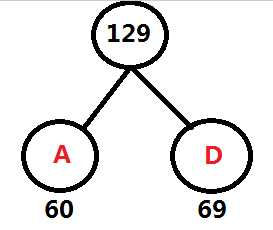
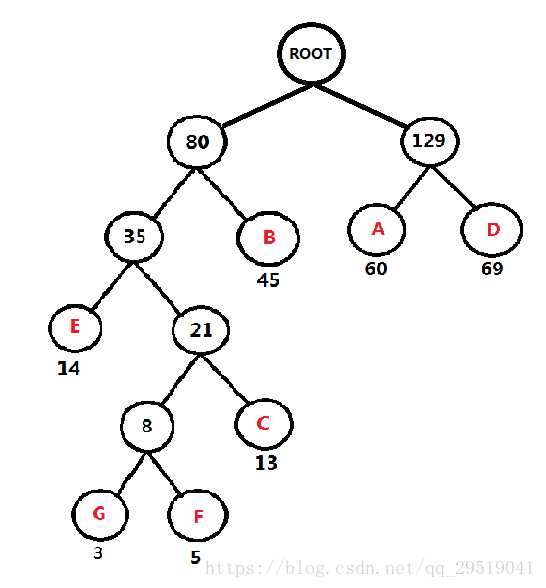
重复第一步
频率表 AD:129 FGCEB: 80
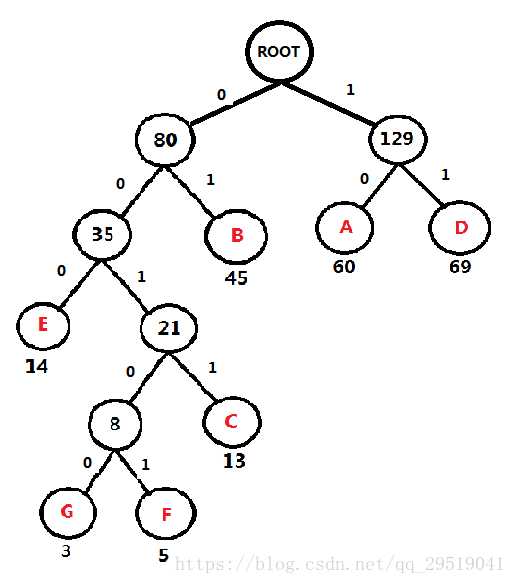
添加 0 和 1,规则左0 右1
频率表 A:60, B:45, C:13 D:69 E:14 F:5 G:3
每个 字符 的 二进制编码 为(从根节点 数到对应的叶子节点,路径上的值拼接起来就是叶子节点字母的应该的编码)
A:10
B:01
C:0011
D:11
E:000
F:00101
G:00100
来源于哈夫曼树原理,及构造方法
1.创建哈夫曼树:(函数参数为整型数组)
(1)引入哈夫曼树指针数组并申请空间,为每棵哈夫曼树复制,将其左右节点赋值为NULL。
(2)将(n-1)棵哈夫曼树合并:
a.引入两个整形变量始终代表最小和次小的下标
b.比较权值,使两个下标成为最小的两个权值的下标
c.合并一次,并将最小下标的哈夫曼树赋值为新的哈夫曼树,次小下表的哈夫曼树赋值为空。
2.输出哈夫曼树:根节点不为空,输出权重,若左右子树不为空,依次输出“(”, 左子树,“,”,右子树,“)”
3.递归进行哈夫曼编码:由于哈夫曼树的特点是所有的原始树都为叶子节点,故可以用这方法来进行编码。
4.哈夫曼解码:while(已解码长度<字符串长度){找到某一叶子节点并打印}
1、创造树:
public static HuffNode createTree(List<HuffNode> nodes) {
//先获取两个最小的结点,再存入新的节点。
while (nodes.size() > 1) {
//进行从大到小的排序
Collections.sort(nodes);
//获取
HuffNode left = nodes.get(nodes.size() - 1);
HuffNode right = nodes.get(nodes.size() - 2);
//求和
HuffNode parent = new HuffNode('无', left.getWeight() + right.getWeight());
//让新节点作为两个权值最小节点的父节点
parent.setLeft(left);
left.setCodenumber("0");
parent.setRight(right);
right.setCodenumber("1");
//删除
nodes.remove(left);
nodes.remove(right);
//重新写入
nodes.add(parent);
}
return nodes.get(0);
}2、找
public static List<HuffNode> breadthFirstTraversal(HuffNode root) {
List<HuffNode> list = new ArrayList<HuffNode>();
Queue<HuffNode> queue = new ArrayDeque<HuffNode>();
//将根元素加入“队列
if (root != null) {
queue.offer(root);
root.getLeft().setCodenumber(root.getCodenumber() + "0");
root.getRight().setCodenumber(root.getCodenumber() + "1");
}
while (!queue.isEmpty()) {
//将该队列的“队尾”元素加入到list中
list.add(queue.peek());
HuffNode node = queue.poll();
//如果左子节点不为null,将它加入到队列
if (node.getLeft() != null) {
queue.offer(node.getLeft());
node.getLeft().setCodenumber(node.getCodenumber() + "0");
}
//如果右子节点不为null,将它加入到队列
if (node.getRight() != null) {
queue.offer(node.getRight());
node.getRight().setCodenumber(node.getCodenumber() + "1");
}
}
return list;
}3、做测试
public class HuffmanTest {
public static void main(String[] args) throws IOException {
//把字符集从文件中读出来,并保存在一个数组characters里面
File file = new File("D:\\Huffman.txt");
if(!file.exists()){
file.createNewFile();
}
Reader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String temp = bufferedReader.readLine();
char characters[] = new char[temp.length()];
for (int i = 0; i < temp.length(); i++) {
characters[i] = temp.charAt(i);
}
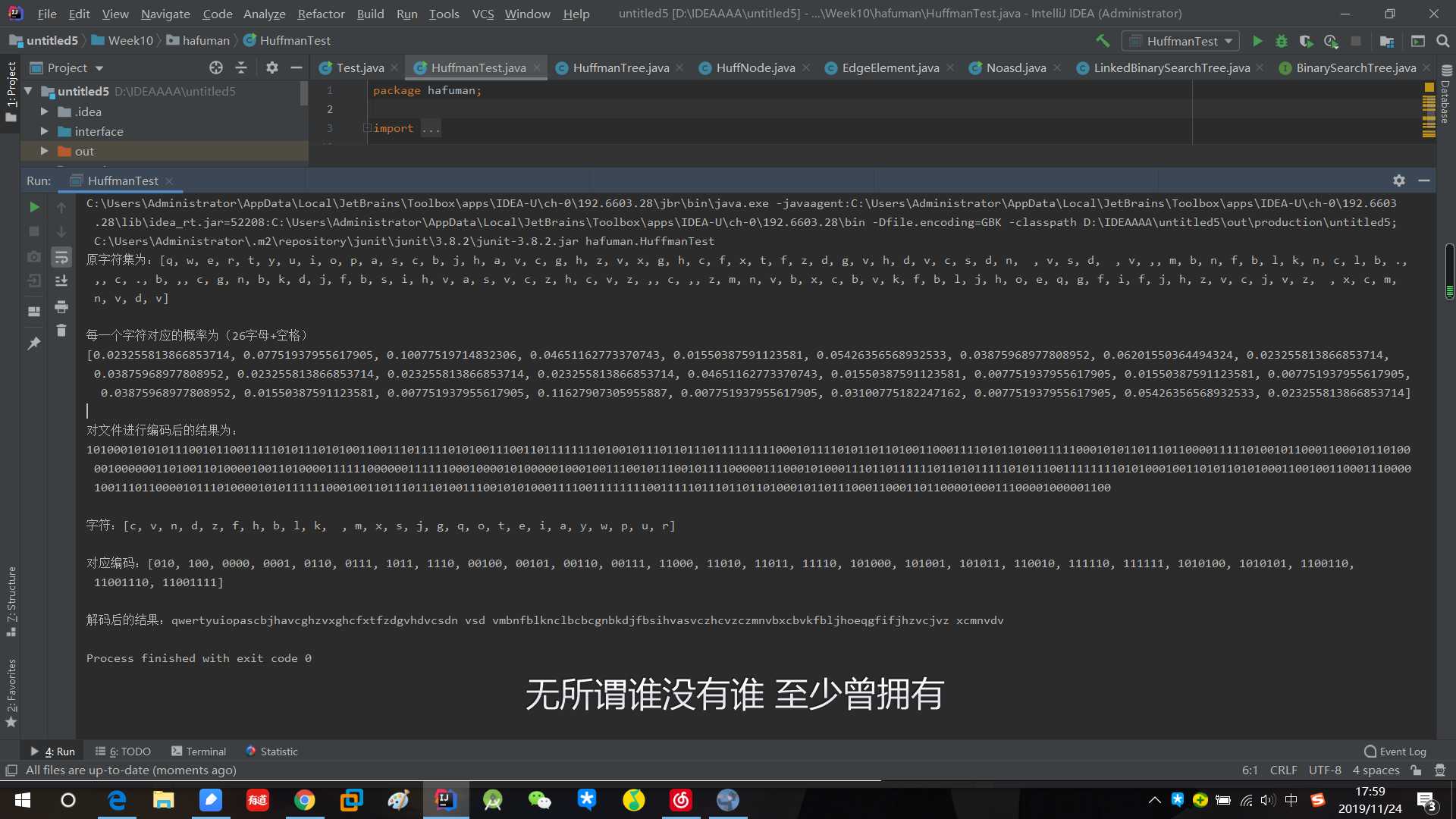
System.out.println("原字符集为:" + Arrays.toString(characters));
//计算每一个字符出现的频率。并把出现的概率存在另一个数组中
double frequency[] = new double[27];
int numbers = 0;
for (int i = 0; i < characters.length; i++) {
if (characters[i] == ' ') {
numbers++;
}
frequency[26] = (float) numbers / characters.length;
}
for (int j = 97; j <= 122; j++) {
int number = 0;//给字母计数
for (int m = 0; m < characters.length; m++) {
if (characters[m] == (char) j) {
number++;
}
frequency[j - 97] = (float) number / characters.length;
}
}
System.out.println("
每一个字符对应的概率为(26字母+空格)" + "
" + Arrays.toString(frequency));
List<HuffNode> nodes = new ArrayList<>();
for (int o = 97; o <= 122; o++) {
nodes.add(new HuffNode((char) o, frequency[o - 97]));
}
nodes.add(new HuffNode(' ', frequency[26]));
HuffNode root = HuffmanTree.createTree(nodes);
String result1 = "";
List<HuffNode> temp1 = breadthFirstTraversal(root);
for (int i = 0; i < characters.length; i++) {
for (int j = 0; j < temp1.size(); j++) {
if (characters[i] == temp1.get(j).getData()) {
result1 += temp1.get(j).getCodenumber();
}
}
}
System.out.println("
对文件进行编码后的结果为:");
System.out.println(result1);
File file2 = new File("D:\\enHuffman.txt");
Writer writer = new FileWriter(file2);
writer.write(result1);
writer.close();
//将所有具有字符的叶子节点重新保存在一个newlist里面
List<String> newlist = new ArrayList<>();
for(int m=0;m < temp1.size();m++)
{
if(temp1.get(m).getData()!='无')
newlist.add(String.valueOf(temp1.get(m).getData()));
}
System.out.println("
字符:"+newlist);
List<String> newlist1 = new ArrayList<>();
for(int m=0;m < temp1.size();m++)
{
if(temp1.get(m).getData()!='无')
newlist1.add(String.valueOf(temp1.get(m).getCodenumber()));
}
System.out.println("
对应编码:"+newlist1);
FileReader fileReader = new FileReader("D:\\enHuffman.txt");
BufferedReader bufferedReader1 = new BufferedReader(fileReader);
String secretline = bufferedReader1.readLine();
List<String> secretText = new ArrayList<String>();
for (int i = 0; i < secretline.length(); i++) {
secretText.add(secretline.charAt(i) + "");
}
//解密
String result2 = "";
String current="";// linshizhi
while(secretText.size()>0) {
current = current + "" + secretText.get(0);
secretText.remove(0);
for (int p = 0; p < newlist1.size(); p++) {
if (current.equals(newlist1.get(p))) {
result2 = result2 + "" + newlist.get(p);
current="";
}
}
}
//最后输出
System.out.println("
解码后的结果:"+result2);
File file3 = new File("D:\\deHuffman.txt");
Writer writer1 = new FileWriter(file3);
writer1.write(result2);
writer.close();
}
}
其他(感悟、思考等)
随着期末的到来,各科学习任务都加剧了起来,所有科目都在复习,但是java依然占据很多时间,大作业布置下来,大家都想把它做好,所以有时候里面会产生很多误会,这就很不应该了,但细想也不能避免,毕竟大家的好胜心还是很强的,都在用自己的方式让自己的APP变得更完美,成为最出色的那一个,我们也不例外,所以对于这个实践上的心就比较少,所以做出来的结果也比较一般。
参考资料
-? 《Java程序设计与数据结构教程(第二版)》学习指导
-? ...
以上是关于哈夫曼的主要内容,如果未能解决你的问题,请参考以下文章