业务领域建模
Posted litosty
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业务领域建模相关的知识,希望对你有一定的参考价值。
领域建模
- Collect application domain information
- focus on the functional requirements – also consider other requirements and documents
- Brainstorming
- listing important application domain concepts – listing their properties/attributes – listing their relationships to each other
- Classifying the domain concepts into:
- classes – attributes / attribute values – relationships
- association, inheritance, aggregation
- Document result using UML class diagram
1 Collect application domain information
我的工程实践题目是《多人对话场景中音频分离》,题目要求的任务即说话人区分(Speaker Diarization)任务。说话人区分是声纹识别领域中的一个任务,具体是指根据说话者身份将输入的音频划分为同类片段的过程。说话人区分是说话人细分和说话人聚类的组合,第一个目标是找到音频中的说话人更改点, 第二个目标是根据说话者的特征将语音片段分组在一起。说话人区分常常作为语音识别功能的预处理,它将音频中说话人的身份信息提供给语音识别系统,从而改善语音识别的准确率。
语音是人和人之间进行交流的最自然、最方便、最有效的方式,也是人类获取信息的重要来源之一。随着计算机处理能力的不断增强以及音频处理技术的不断提升,研究如何从海量的数据,如电视新闻广播录音及会议录音中,获取感兴趣的声音,已成为很多大学和研究机构的一个热点。另一方面,如何对获取到的各类音频进行合理有效的文档管理,也是目前存在的一大挑战。然而,当前无论是从机器中或是从网络上采集到的原始录音数据仅仅是一种非结构化的二进制数据流,它们缺乏通用结构化的内容组织形式,这就使得单独的一项语音相关技术并不足以满足人们的需求。例如,对会议录音进行语音转写,只能得到连续的文字串,而不能获得会议过程中每个人说的具体内容及含义,因此需要多种语音技术相互结合,才能满足在会议场景下的需求,而说话人分离就是为了配合完成其它语音技术而衍生出来的一种技术。借助说话人分离人们可实现对音频数据流的一种结构化管理,进而为在更高语义层次上实现结构化音频内容提供基础,这样在会议场景下的多说话人音频文档整理时,便可以达到文档归类的目的。说话人分离技术具有很多实际应用价值。
一般而言,当前基于统计模式识别技术的语音处理技术大部分都是针对单人的,典型的如语音识别、说话人识别、关键词检索,都只能在一段只包含一个人的语音文件才能取得令人满意的结果;当语音中含有多个说话人时,这些算法的性能会急剧下降,无法满足实际应用的需求。说话人分割聚类技术作为一项重要的前端处理技术,它可以获得语音中说话人变动的信息,以及哪些语音段是由同一个人发出的,在完成这些处理后,可以更方便地实现后续的信息处理,如前述的语音识别以及进一步的撰写摘要、语法分析,机器翻译等。
2 Brainstorming
2.1 核心概念
音频
指人耳可以听到的声音频率在20HZ~20kHz之间的声波,称为音频。
音频文件格式
专指存放音频数据的文件的格式。存在多种不同的格式。
采样频率
即取样频率, 指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。
22050 的采样频率是常用的, 44100已是CD音质, 超过48000或96000的采样对人耳已经没有意义。这和电影的每秒 24 帧图片的道理差不多。
如果是双声道(stereo), 采样就是双份的, 文件也差不多要大一倍.
采样位数
即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。每个采样数据记录的是振幅, 采样精度取决于采样位数的大小。
通道数
即声音的通道的数目。常有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声可以使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果,当然还有更多的通道数。
帧
帧记录了一个声音单元,其长度为样本长度(采样位数)和通道数的乘积。
周期
音频设备一次处理所需要的帧数,对于音频设备的数据访问以及音频数据的存储,都是以此为单位。
交错模式
数字音频信号存储的方式,分为交错模式和非交错模式。交错模式是指数据以连续帧的方式存放,即首先记录帧1的左声道样本和右声道样本,再开始帧2的记录,非交错模式是指首先记录的是一个周期内所有帧的左声道样本,再记录所有右声道样本。
非交错模式
首先记录的是一个周期内所有帧的左声道样本,再记录所有右声道样本。
比特率
每秒的传输速率(位速, 也叫比特率)。如705.6kbps 或 705600bps, 其中的 b 是 bit, ps 是每秒的意思,表示每秒705600bit的容量。
短时加窗处理:
音频信号是动态变化的,为了能传统的方法对音频信号进行分析,假设音频信号在几十毫秒的短时间内是平稳的。为了得到短时的音频信号,要对音频信号进行加窗操作。窗函数平滑的在音频信号上滑动,将音频信号分成帧。分帧可以连续,也可以采用交叠分段的方法,交叠部分称为帧移,一般为窗长的一半。窗函数可以采用汉明窗、汉宁窗等。在时域上处理时,分帧之后处理手段的名称一般都在处理手段前加“短时”修饰。
降噪:
降低音频信号的信噪比。
说话人标签
指当前标记的说话人身份
3 Classifying the domain concepts
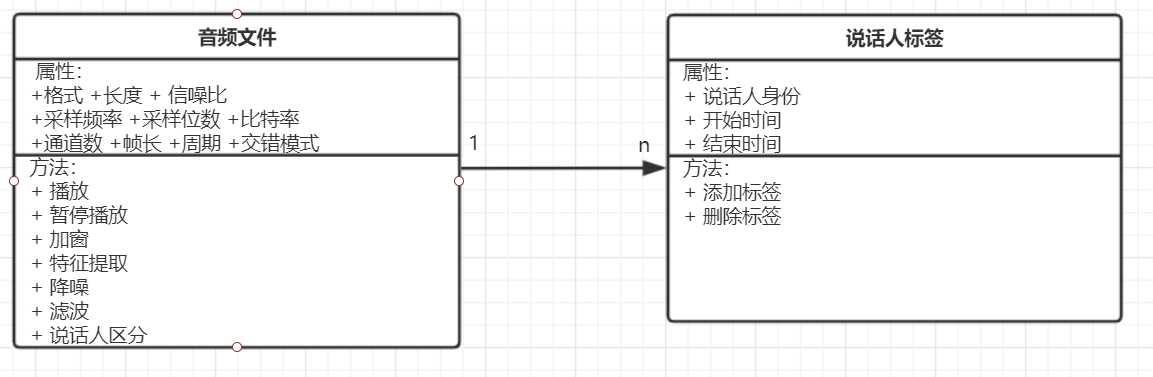
| 类名 | 属性 | 方法 |
|---|---|---|
| 音频文件 | 格式 长度 信噪比 采样频率 采样位数 比特率 通道数 帧长 周期 交错模式 | 播放 暂停播放 加窗 特征提取 降噪 滤波 说话人区分 |
| 说话人标签 | 说话人身份 开始时间 结束时间 | 添加标签 删除标签 |
4 Document result using UML class diagram
以上是关于业务领域建模的主要内容,如果未能解决你的问题,请参考以下文章