数据分析知识图谱- part1
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析知识图谱- part1相关的知识,希望对你有一定的参考价值。
参考技术A 在日常分析中,常会遇到不知道选择什么分析方法的尴尬情况出现,尤其是在面对几种相似的方法,不知道它们之间有什么差别,一念之差就会选错方法。相信这样的小盲点,依然困扰着不少人。因此,SPSSAU整理了一份相似方法的对比目录,可以一目了然地比较出方法间的差异。由于方法较多,将分几部分整理出来。
频数分析 是用于分析定类数据的选择频数和百分比分布。
描述分析 用于描述定量数据的集中趋势、波动程度和分布形状。如要计算数据的平均值、中位数等,可使用描述分析。
分类汇总 用于交叉研究,展示两个或更多变量的交叉信息,可将不同组别下的数据进行汇总统计。
信度分析的方法主要有以下三种:Cronbach α信度系数法、折半信度法、重测信度法。
Cronbach α信度系数法 为最常使用的方法,即通过Cronbach α信度系数测量测验或量表的信度是否达标。
折半信度 是将所有量表题项分为两半,计算两部分各自的信度以及相关系数,进而估计整个量表的信度的测量方法。可在信度分析中选择使用折半系数或是Cronbach α系数。
重测信度 是指同一批样本,在不同时间点做了两次相同的问题,然后计算两次回答的相关系数,通过相关系数去研究信度水平。
效度有很多种,可分为四种类型:内容效度、结构效度、区分效度、聚合效度。具体区别如下表所示:
T检验 可分析X为定类数据,Y为定量数据之间的关系情况,针对T检验,X只能为2个类别。
当组别多于2组,且数据类型为X为定类数据,Y为定量数据,可使用 方差分析 。
如果要分析定类数据和定类数据之间的关系情况,可使用 交叉卡方分析
如果研究定类数据与定量数据关系情况,且数据不正态或者方差不齐时,可使用 非参数检验 。
相关分析 用于研究定量数据之间的关系情况,可以分析包括是否有关系,以及关系紧密程度等。分析时可以不区分XY,但分析数据均要为定量数据。
回归分析 通常指的是线性回归分析,一般可在相关分析后进行,用于研究影响关系情况,其中X通常为定量数据(也可以是定类数据,需要设置成哑变量),Y一定为定量数据。
回归分析通常分析Y只有一个,如果想研究多个自变量与多个因变量的影响关系情况,可选择 路径分析 。
相关分析用于研究X和Y的关系情况,X、Y都为定量数据。
(1)简单相关分析 是分析对两个变量之间的相关关系。
(2) 当两个变量都与第三个变量相关时,为了消除第三个变量的影响,值关注这两个变量之间的关系情况,此时可使用 偏相关分析 。
(3) 如果是研究两组变量之间的整体相关性,可用 典型相关分析 。
线性回归用于研究X对于Y的影响,前提是因变量Y为定量数据。
如果X很多时,可使用 逐步回归 自动找出有影响的X;
如果需要研究多个线性回归的层叠变化情况,此时可使用 分层回归 ;
如果数据中有异常值,可使用 Robust回归 进行研究。
Logistic回归用于研究 X对于Y的影响,因变量Y 一定 为定 类 数据。
如果Y有两个选项时,可使用 二元Logit回归。
如果Y的选项大于2个时,可使用 多分类Logit回归。
如果Y为定类数据,且选项有顺序大小之分时,可使用 有序Logit回归。
T检验用于分析定类数据与定量数据之间的关系情况,且X的组别只限于为两组。
如果是对比单个变量与某个数字的差异,可用 单样本T检验。
如果是对比两个变量之间(X定类,Y定量)的差异关系,可用 独立样本T检验。
如果两个变量是配对数据,比如对一个群体用同一个工具前后测量了两次,可用 配对T检验分析。
方差分析用于分析定类数据与定量数据之间的关系情况,可分析两组或两组以上的变量差异。
如果X为一个,则使用 单因素方差分析 ,即通用方法里的方差。
如果X的个数为2个,可使用 双因素方差分析 。
当X个数超过2个,可使用 多因素方差分析 。通常双因素方差分析与多因素方差分析多用于实验研究中。
事后检验 是基于方差分析基础上进行,如果X的组别超过两组,可用事后检验进一步分析两两组别之间的差异。
如果研究中有干扰因素(控制变量),可使用 协方差分析 。
多选题分析可分为四种类型包括:多选题、单选-多选、多选-单选、多选-多选。
“多选题分析” 是针对单个多选题的分析方法,可分析多选题各项的选择比例情况
“单选-多选” 是针对X为单选,Y为多选的情况使用的方法,可分析单选和多选题的关系。
“多选-单选” 是针对X为多选,Y为单选的情况使用的方法。
“多选-多选” 是针对X为多选,Y为多选的情况使用的方法。
聚类分析以多个研究标题作为基准,对样本对象进行分类。
如果是按样本聚类,则使用SPSSAU的进阶方法模块中的“聚类”功能,系统会自动识别出应该使用 K-means 聚类算法还是 K-prototype 聚类算法。
如果是按变量(标题)聚类,此时应该使用 分层聚类 ,并且结合聚类树状图进行综合判定分析。
权重研究是用于分析各因素或指标在综合体系中的重要程度,最终构建出权重体系。权重研究有多种方法包括:因子分析、熵值法、AHP层次分析法、TOPSIS、模糊综合评价、灰色关联等。
因子分析: 因子分析可将多个题项浓缩成几个概括性指标(因子),然后对新生成的各概括性指标计算权重。
熵值法: 熵值法是利用熵值携带的信息计算每个指标的权重,通常可配合因子分析或主成分分析得到一级权重,利用熵值法计算二级权重。
AHP层次分析法: AHP层次分析法是一种主观加客观赋值的计算权重的方法。先通过专家打分构造判断矩阵,然后量化计算每个指标的权重。
TOPSIS法: TOPSIS权重法是一种评价多个样本综合排名的方法,用于比较样本的排名。
模糊综合评价: 是通过各指标的评价和权重对评价对象得出一个综合性评价。
灰色关联: 灰色关联是一种评价多个指标综合排名的方法,用于判断指标排名。
非参数检验用于研究定类数据与定量数据之间的关系情况。如果数据不满足正态性或方差不齐,可用非参数检验。
单样本Wilcoxon检验 用于检验数据是否与某数字有明显的区别。
如果X的组别为两组,则使用 MannWhitney 统计量,如果组别超过两组,则应该使用 Kruskal-Wallis 统计量结果,SPSSAU可自动选择。
如果是配对数据,则使用 配对样本Wilcoxon检验
如果要研究多个关联样本的差异情况,可以用 多样本Friedman检验 。
如果是研究定类数据与定量(等级)数据之间的差异性,还可以使用 Ridit分析 。
判断数据分布是选择正确分析方法的重要前提。
正态性: 很多分析方法的使用前提都是要求数据服从正态性,比如线性回归分析、相关分析、方差分析等,可通过正态图、P-P/Q-Q图、正态性检验查看数据正态性。
随机性: 游程检验是一种非参数性统计假设的检验方法,可用于分析数据是否为随机。
方差齐性: 方差齐检验用于分析不同定类数据组别对定量数据时的波动情况是否一致,即方差齐性。方差齐是方差分析的前提,如果不满足则不能使用方差分析。
Poisson分布: 如果要判断数据是否满足Poisson分布,可通过Poisson检验判断或者通过特征进行判断是否基本符合Poisson分布(三个特征即:平稳性、独立性和普通性)
卡方拟合优度检验: 卡方拟合优度检验是一种非参数检验方法,其用于研究实际比例情况,是否与预期比例表现一致,但只针对于类别数据。
单样本T检验: 单样本T检验用于分析定量数据是否与某个数字有着显著的差异性。
当需要研究多个变量之间的关系情况时,通常可构建统计模型用于分析及预测。
如果研究一个X或多个X对Y的影响关系,其中Y为定量数据,可使用 线性回归分析 ,构建回归模型。
如果研究一个X或多个X对Y的影响关系,其中Y为定类数据,可使用 Logistic分析 ,构建Logistic回归模型。
如果要分析1组X与一组Y之间的关系情况,可使用 典型相关分析 。
如果要分析多个X与多个Y之间的影响关系情况,且样本量较小(通常小于200),可使用 PLS回归分析 。
如需分析多个X对多个Y的影响关系,以及具体哪些X对哪些Y有影响如何影响,可使用 路径分析 。
还有一种方法称为结构方程模型,包含测量模型和结构模型。如果需要测量模型和结构模型,可使用 结构方程模型 。
当研究中包括有很多题目或很多变量时,可通过信息浓缩的方法,把数据浓缩成一个或多个变量,以便用于后续的分析。
主成分分析和因子分析 都是信息浓缩的方法,即将多个分析项信息浓缩成几个概括性指标。如果希望进行将指标命名,SPSSAU建议使用因子分析。原因在于因子分析在主成分基础上,多出一项旋转功能,该旋转目的即在于命名。
平均值和求和 也是信息浓缩的常用方法,比如要将多个题项合并成一个变量,可通过求平均值概括成一个题项。当数据不满足正态,存在极端值时,可用 中位数 代替平均值。
一致性检验的目的在于比较不同方法得到的结果是否具有一致性。检验一致性的方法有很多比如:Kappa检验、ICC组内相关系数、Kendall W协调系数等。
Kappa系数检验 ,适用于两次数据(方法)之间比较一致性,比如两位医生的诊断是否一致,两位裁判的评分标准是否一致等。
ICC组内相关系数检验 ,用于分析多次数据的一致性情况,功能上与Kappa系数基本一致。ICC分析定量或定类数据均可;但是Kappa一致性系数通常要求数据是定类数据。
Kendall W协调系数 ,是分析多个数据之间关联性的方法,适用于定量数据,尤其是定序等级数据。
配对研究是一种医学上常见的研究设计,常见于单组样本前后对比研究,或者将样本分为实验组和对比组两组,针对干预措施进行研究。
如果配对样本数据为定量数据时,可使用 配对样本T检验 。
如果配对样本数据为定量数据,但配对样本的差值不符合正态分布,则考虑使用 配对Wilcoxon检验
如果数据为定类数据,则使用 配对卡方检验 。
判别分析: 用于在分类确定前提下,根据数据的特征来判断新的未知属于哪个类别。
对应分析: 用于分析定类数据的分类情况,并结合图形展示。
曲线分析: 如果想要研究X对Y的影响关系,且X和Y不满足线性关系(可通过散点图观察),而呈现出曲线关系,建议根据曲线拟合图结果,选择拟合程度较好的曲线进行曲线回归分析。
更多干货内容可登录 SPSSAU官网 查看
知识图谱基础知识之三——知识图谱的构建过程
前两次介绍了知识图谱的基本概念和知识图谱的构建方式,这次介绍一下知识图谱系统的构建过程。
1 知识图谱的总体构建思路
如图所示,从原始的数据到形成知识图谱,经历了知识抽取、知识融合(实体对齐)、数据模型构建、质量评估等步骤。
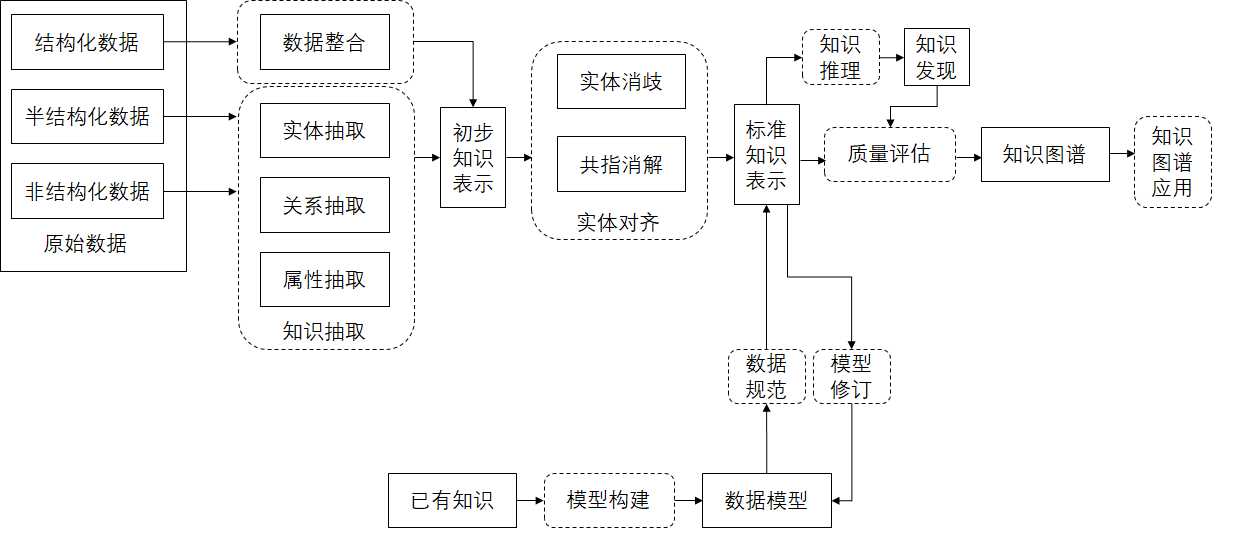
原始的数据,按照数据的结构化程度来分,可以分为结构化数据、半结构化数据和非结构化数据,根据数据的不同的结构化形式,采用不同的方法,将数据转换为三元组的形式,然后对三元组的数据进行知识融合,主要是实体对齐,以及和数据模型进行结合,经过融合之后,会形成标准的数据表示,为了发现新知识,可以依据一定的推理规则,产生隐含的知识,所有形成的知识经过一定的质量评估,最终进入知识图谱,依据知识图谱这个数据平台,可以实现语义搜索,智能问答,推荐系统等一些应用。
以下对知识图谱构建中的步骤进行详细的介绍。
2 知识抽取
我们将原始数据分为结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。
2.1 结构化数据处理
针对结构化数据,通常是关系型数据库的数据,数据结构清晰,把关系型数据库中的数据转换为RDF数据(linked data),普遍采用的技术是D2R技术。D2R主要包括D2R Server,D2RQ Engine和D2RRQ Mapping语言。
D2R Server 是一个 HTTP Server,它的主要功能提供对RDF数据的查询访问接口,以供上层的RDF浏览器、SPARQL查询客户端以及传统的 HTML 浏览器调用。 D2RQ Engine的主要功能是使用一个可定制的 D2RQ Mapping 文件将关系型数据库中的数据换成 RDF 格式。D2RQ engine 并没有将关系型数据库发布成真实的 RDF 数据,而是使用 D2RQ Mapping 文件将其映射成虚拟的 RDF 格式。该文件的作用是在访问关系型数据时将 RDF 数据的查询语言 SPARQL 转换为 RDB 数据的查询语言 SQL,并将 SQL 查询结果转换为 RDF 三元组或者 SPARQL 查询结果。D2RQ Engine 是建立在 Jena(Jena 是一个创建 Semantic Web 应用的 Java 平台,它提供了基于 RDF,SPARQL 等的编程环境)的接口之上。 D2RQ Mapping 语言的主要功能是定义将关系型数据转换成 RDF 格式的 Mapping 规则。
2.2 半结构化数据处理
半结构化数据,主要是指那些具有一定的数据结构,但需要进一步提取整理的数据。比如百科的数据,网页中的数据等。对于这类数据,主要采用包装器的方式进行处理。
包装器是一个能够将数据从HTML网页中抽取出来,并且将它们还原为结构化的数据的软件程序。网页数据输入到包装器中,通过包装器的处理,输出为我们需要的信息。
对于一般的有规律的页面,我们可以使用正则表达式的方式写出XPath和CSS选择器表达式来提取网页中的元素。但这样的通用性很差,因此也可以通过包装器归纳这种基于有监督学习的方法,自动的从标注好的训练样例集合中学习数据抽取规则,用于从其他相同标记或相同网页模板抽取目标数据。
2.3 非结构化数据处理
对于非结构化的文本数据,我们抽取的知识包括实体、关系、属性。对应的研究问题就有三个,一是实体抽取,也称为命名实体识别,此处的实体包括概念,人物,组织,地名,时间等等。二是关系抽取,也就是实体和实体之间的关系,也是文本中的重要知识,需要采用一定的技术手段将关系信息提取出来。三是属性抽取,也就是实体的属性信息,和关系比较类似,关系反映实体的外部联系,属性体现实体的内部特征。
非结构化数据的抽取问题,研究的人比较多,对于具体的语料环境,采取的技术也不尽相同。举个例子,比如关系抽取,有的人采用深度学习的方法,将两个实体,他们的关系,以及出处的句子作为训练数据,训练出一个模型,然后对于测试数据进行关系抽取,测试数据需要提供两个实体和出处的句子,模型在训练得到的已知关系中查找,得出测试数据中两个实体之间的关系。这是一种关系抽取的方法。还有人用句法依存特征,来获取关系,这种方法认为,实体和实体之间的关系可以组成主谓宾结构,在一个句子中,找出主谓关系和动宾关系,其中的谓词和动词如果是一个词,那么这个词就是一个关系。比如说“小明吃了一个苹果”,主谓关系是“小明吃”,动宾关系是“吃苹果”,那么就认为“吃”是一个关系。
当然,还有其它很多方法,可以在一定程度上实现实体抽取,关系抽取和属性抽取,效果可能会有差异,这需要在实践中测试和完善。
3 知识融合
知识融合,简单理解,就是将多个知识库中的知识进行整合,形成一个知识库的过程,在这个过程中,主要需要解决的问题就是实体对齐。不同的知识库,收集知识的侧重点不同,对于同一个实体,有知识库的可能侧重于其本身某个方面的描述,有的知识库可能侧重于描述实体与其它实体的关系,知识融合的目的就是将不同知识库对实体的描述进行整合,从而获得实体的完整描述。
比如,对于历史人物曹操的描述,在百度百科、互动百科、维基百科等不同的知识库中,描述有一些差别,曹操所属时代,百度百科为东汉,互动百科为东汉末年,维基百科为东汉末期;曹操的主要成就,百度百科为“实行屯田制,安抚流民消灭群雄,统一北方,奠定曹魏政权的基础,开创建安文学,提倡薄葬”,互动百科为“统一北方”,维基百科为“统一了东汉帝国核心地区”。
由此可以看出,不同的知识库对于同一个实体的描述,还是有一些差异,所属时代的描述差别在于年代的具体程度,主要成就的差别在于成就的范围不同,等等,通过知识融合,可以将不同知识库中的知识进行互补融合,形成全面、准确、完整的实体描述。 知识融合过程中,主要涉及到的工作就是实体对齐,也包括关系对齐,属性对齐,可以通过相似度计算,聚合,聚类等技术来实现。
4 数据模型构建
上一篇文章,我们阐述过知识图谱的构建方法,提到知识图谱的数据整体上可以分为数据模型和具体数据,数据模型就是知识图谱的数据组织框架,不同的知识图谱,会采用不同的数据模型。对于行业知识图谱来说,行业术语、行业数据都相对比较清晰,可以采用自顶向下的方式来建设知识图谱,也就是先确定知识图谱的数据模型,然后,根据数据模型约定的框架,再补充数据,完成知识图谱的建设。 数据模型的构建,一般都会找一个基础的参考模型,这个参考模型,可以参照行业的相关数据标准,整合标准中对数据的要求,慢慢形成一个基础的数据模型,再根据实际收集的数据情况,来完善数据模型。也可以从公共知识图谱数据模型中抽取,将与行业有关的数据模型从公共知识图谱数据模型中提取出来,然后结合行业知识进行完善。
5 知识推理
知识推理,就是根据已有的数据模型和数据,依据推理规则,获取新的知识或者结论,新的知识或结论应该是满足语义的。知识推理,依据描述逻辑系统实现。描述逻辑(Description Logic)是基于对象的知识表示的形式化,也叫概念表示语言或术语逻辑,是一阶谓词逻辑的一个可判定子集。
一个描述逻辑系统由四个基本部分组成: 最基本的元素:概念、关系、个体;TBox术语集:概念术语的公理集合; Abox断言集:个体的断言集合;TBox 和 ABox上的推理机制。
描述逻辑涉及到的内容也比较多,此处举几个例子,比如实体的分类包含关系,一个电脑椅是椅子,椅子是家具,可以说,一个电脑椅是家具。常识规则的推理,一个男人的孩子是A,一个女人的孩子是A,可以知道,这个男人和女人是配偶。
通过推理发现新的知识,应用比较多,说明知识图谱的时候也经常不自觉的会应用推理,比如前两年比较受人关注的王宝强离婚案,为什么会聘用张起淮做律师,通过知识图谱可以很清楚知道,王宝强和冯小刚关系比较密切,冯小刚聘用张起淮作为律师顾问,所以王宝强很容易和张起淮建立关系,这也可以看作是知识推理的范畴。当然,更确切地说,应该是规则的范畴。推理更强调的是固有的逻辑,规则一般是和业务相关的自定义逻辑,但推理和规则都是通过逻辑准则,获取新的知识或发现,在这里先不做区分。
6 质量评估
质量评估,就是对最后的结果数据进行评估,将合格的数据放入知识图谱中。质量评估的方法,根据所构建的知识图谱的不同,对数据要求的差异而有所差别。总的目的是要获得合乎要求的知识图谱数据,要求的标准根据具体情况确定。 比如对于公共领域的知识图谱,知识的获取采用了众包的方法,对于同一个知识点,可能会有很多人来完成,如果这个知识点只有一个答案,可以采用的一种策略是,将多人的标注结果进行比较,取投票多的结果作为最终的结果。当然,这是不严谨的,因为真理往往掌握在少数人的手里,特别是针对一些行业的知识图谱,表现尤为突出。行业内的一条知识,可能只有行业专家能够给出权威正确的答案,如果让大众投票来决定,可能会得到一条错误的知识。所以,针对行业知识图谱,可能会采用不同于公共知识图谱的策略,来进行知识的质量评估。
以上零零散散的将知识图谱的构建过程,大体做了一个描述,知识图谱的构建是一个复杂的系统工程,涉及到的知识和技术都很多,肯定会有很多知识或技术没有说到,或者是描述的比较浅显,没有把握住一些构建方法的本质,希望大家补充,我会在后面做项目的过程中,不断细化构建过程,将构建中碰到的具体问题,再进行详细的描述说明。
以上是关于数据分析知识图谱- part1的主要内容,如果未能解决你的问题,请参考以下文章