Spark入门02
Posted qidi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark入门02相关的知识,希望对你有一定的参考价值。
一,什么是RDD?
官方定义:RDD是弹性分布式数据集。
- 不可变的:类似于scala中的不可变集合,对集合进行转换操作的时候,产生新的集合RDD。
- 分区的:每个RDD集合有多个分区组成,分区就是很多部分。
- 并行操作:对RDD集合中的数据操作时,可以同时对所有的分区并行操作
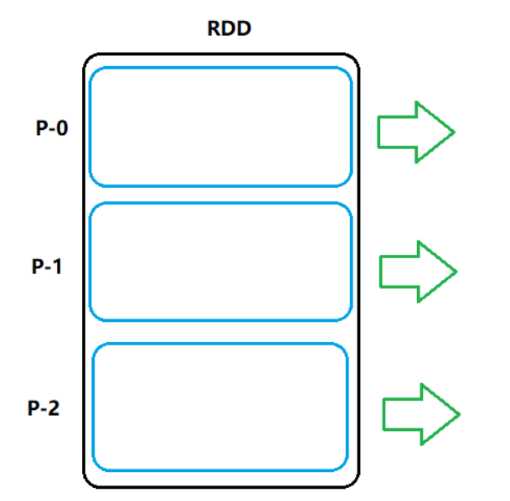
五个特点:
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
第一点:一个RDD由一些列分区Partition组成
protected def getPartitions: Array[Partition]
* - A function for computing each split
第二点:RDD中每个分区数据可以被处理分析(计算),对RDD进行计算相当于对RDD中每个split或者分区计算
def compute(split: Partition, context: TaskContext): Iterator[T]
* - A list of dependencies on other RDDs
第三点:每个RDD依赖一些列RDD,RDD具有依赖关系(容错机制)
protected def getDependencies: Seq[Dependency[_]] = deps
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
第四点:可选的特性,针对KeyValue类型RDD,可以设置分区器,将每个RDD中各个分区数据重新划分,类似MapReduce中分区器Partitioner。
@transient val partitioner: Option[Partitioner] = None
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
第五点:可选的特性,对RDD中每个分区数据处理时,得到最好路径,类似MapReduce中数据本地性
protected def getPreferredLocations(split: Partition): Seq[String] = Nil形象解释:它像我们学过的数据结构一样,树,链表,图等,实际上只是数据的组织形式,真实的分布在内存中的不同位置,只是通过各种index将其连接成易于索引查找的形式。(来源知乎用户队长,侵权删)
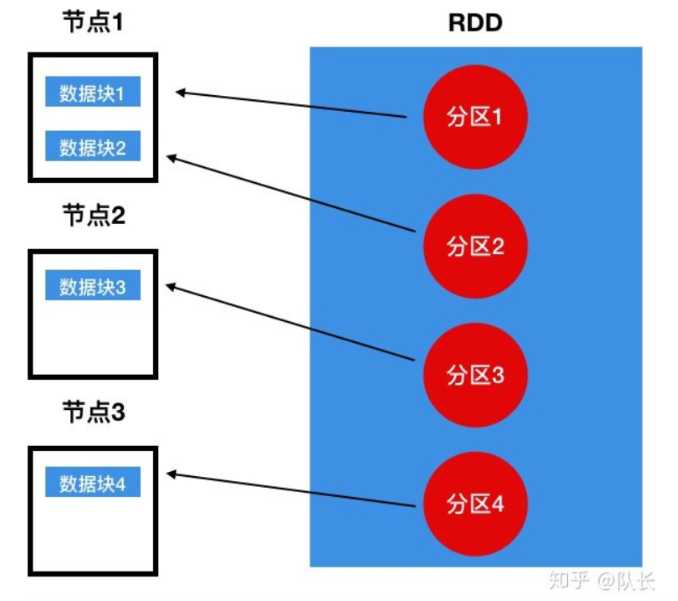
RDD也是如此,真实的数据还是存放在不同的节点中,只是通过某种方式组织起来,便于操作。从上图,RDD可以看成一个列表,列表中的每一个元素代表一个分区,每个分区中它在这个列表中的index,通过index可以确定它指向的数据块。然后我们发现每个分区是在不同的节点中,这保证了一个分区的数据可以在不同的节点中并行处理。
最佳位置示意图:
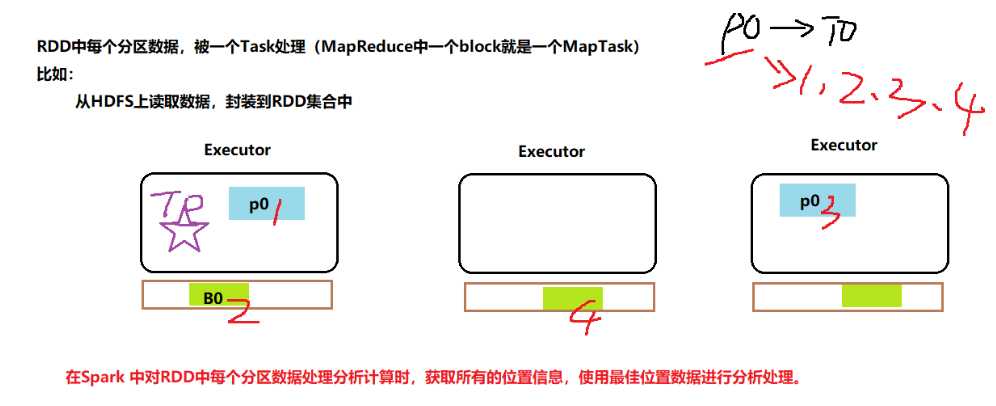
总结:不可变的,分区的,并行处理的弹性分布式。
特点:分区列表,计算函数,依赖关系,分区函数,最佳位置
二,创建RDD
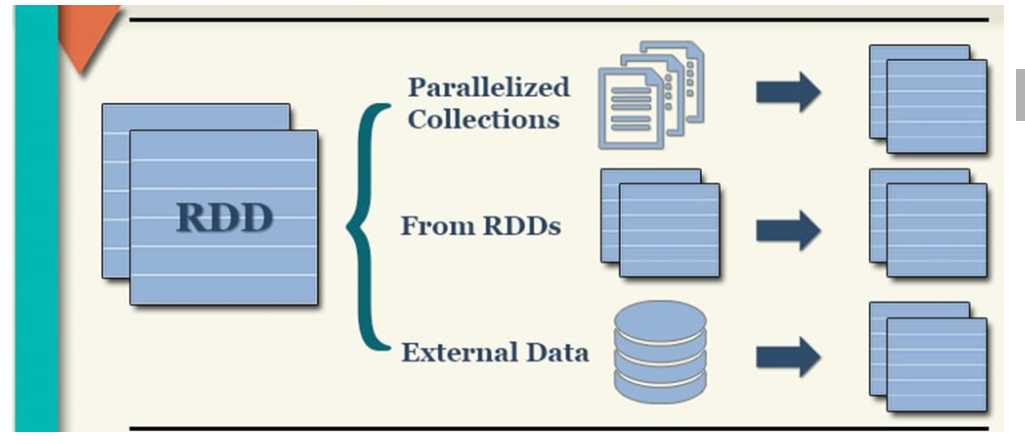
1,外部数据源的数据:
最常用函数就是SparkContext#textFile函数
def textFile(
path: String, // 第一个参数表示:数据路径,可以是LocalFS、也可以是HDFS
minPartitions: Int = defaultMinPartitions // 第二参数表示:RDD分区数目
): RDD[String] 2,并行化集合
将Scala或者Java或者Python中集合转换为RDD
def parallelize[T: ClassTag](
seq: Seq[T], // 集合,针对Scala语言来说,就是序列Seq
numSlices: Int = defaultParallelism // 表示RDD分区数目
): RDD[T]
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
/**
* 采用并行化集合的方式构建RDD,调用SparkContext中函数parallelize,范例如下所示
*/
object SparkParallelize {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkContext上下文实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 创建SparkContext, 有就获取,没有就创建,建议使用
val context = SparkContext.getOrCreate(sparkConf)
// c. 返回对象
context
}
sc.setLogLevel("WARN")
// TODO: 采用parallelize读取数据
// 1. 构建Scala中集合Seq对象
val datas: immutable.Seq[Int] = 1 to 10
// 2. 并行化操作
val datasRDD: RDD[Int] = sc.parallelize(datas, numSlices = 2)
datasRDD.foreach(println)
// 应用结束,关闭资源
sc.stop()
}
}三,RDD Operations
RDD的函数分为三种:
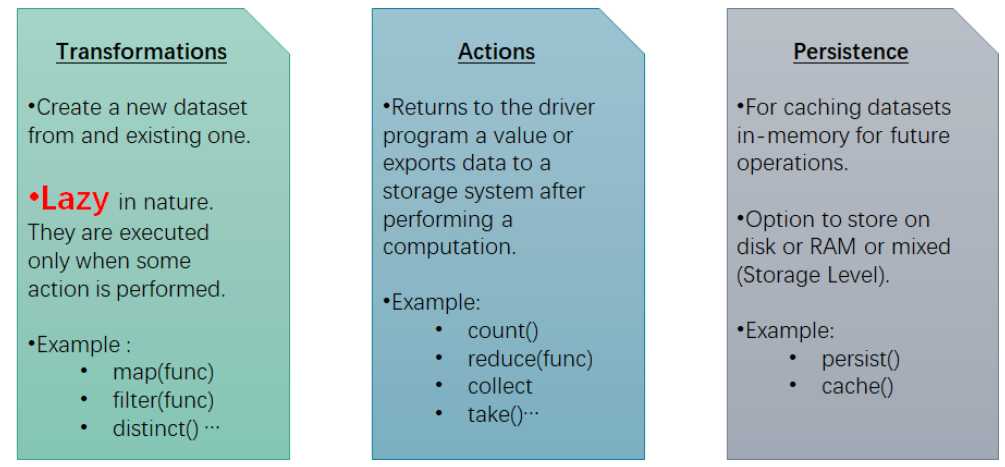
转换函数Tranformation
- RDD调用函数时,产生一个新的RDD
- 调用此类函数时不会立即执行,需要等待Action函数触发才会执行
- map、flatMap、reduceByKey
触发Action
- 当一个RDD调用此类函数,会触发一个job的执行,返回的不是RDD。
- 常见的函数有比如count、first、take、top、foreach等
- 立即执行Job,属于Eager操作
持久化函数:
- 将数据保存早内存或者磁盘中,方便下次快速读取
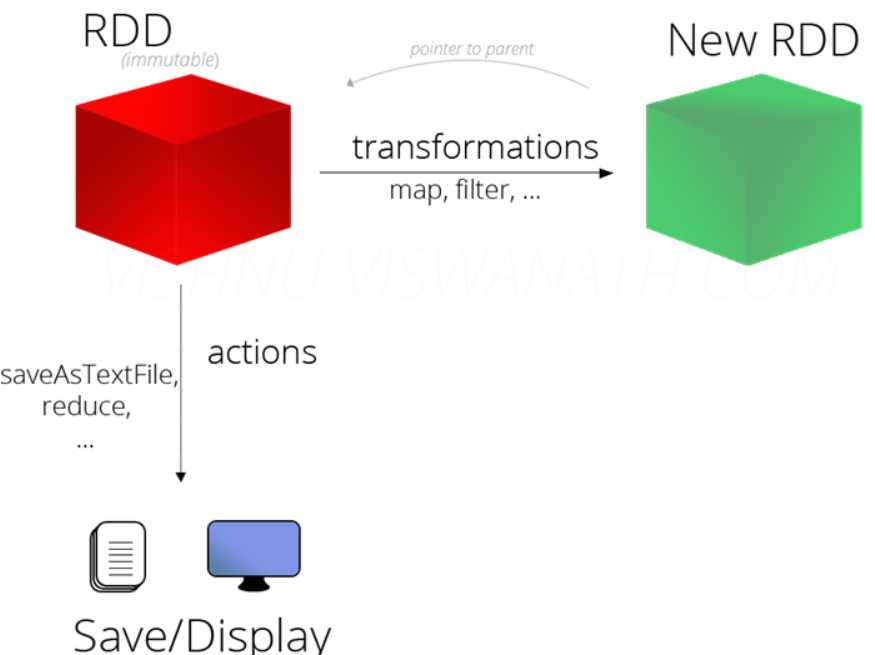
四,RDD重要函数
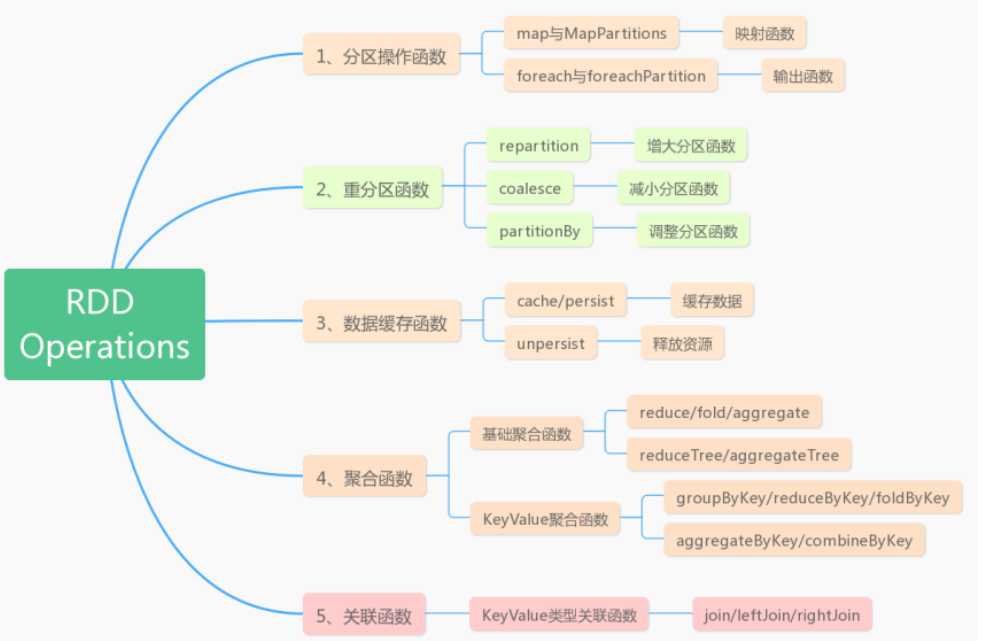
1,分区操作函数
RDD中映射函数map和foreach都是针对RDD分区中的每一个元素操作,不建议使用,在对RDD数据集进行操作时,建议使用分区函数。
// 1. 映射函数 map和mapPartitions
def map[U: ClassTag](f: T => U): RDD[U]
// 针对每个元素处理操作
def mapPartitions[U: ClassTag](
// 将每个分区数据封装到迭代器Iterator中
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false
): RDD[U]
// 2. 输出函数 foreach和foreachPartition
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit
/**
* Applies a function f to each partition of this RDD.
*/
def foreachPartition(f: Iterator[T] => Unit): Unit 为什么对分区进行操作呢?
应用场景:
处理网站日志数据,数据量为10GB,统计各个省份PV和UV。
假设10GB日志数据,从HDFS上读取的,此时RDD的分区数目:80 分区
但是分析PV和UV有多少条数据:34,存储在80个分区中,实际中降低分区数目,比如设置为2个分区
resultRDD:
p0: 24 条数据
p1: 10 条数据
现在需要将结果RDD保存到mysql数据库表中。
1、使用foreach函数
34条数据,就需要创建34 数据库连接
2、使用foreachPartition函数
针对每个分区数据操作,只需要创建2个数据库连接2,重分区函数
1,增加分区数目
//repartition函数既能增加分区又能减少分区数量,但是会产生shuffle。
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]为什么要增加分区呢?
应用场景:
实际项目很多时候业务数据存储到HBase表中,数据对应到各个Region中,此时要分析的就需要从HBase中读取数据,假设HBase中表的Region数目为30个,那么SparkCore读取数据以后,封装的RDD的分区数目就是30个。
默认:rdd-partitions = table-regions
但是每个Region中的数据量大概时5GB数据,对于读取到RDD的每个分区中来说,数据量也是5GB,当一个Task处理一个分区的数据,显得很大,此时需要增加RDD的分区数目。
val etlRDD = hbaseRDD.repartition(40 * 30)
etlRDD-partitions = 12002,减少分区
coalesce函数用于降低RDD分区数目,不会产生shuffle。
def coalesce(
numPartitions: Int,
shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty
)
(implicit ord: Ordering[T] = null): RDD[T]为什么要减低分区呢?
1、当对RDD数据使用filter函数过滤以后,需要考虑是否降低分区数目
比如从ES中获取数据封装到RDD中, 分区数目为50个分区,数据量为20GB
val etlRDD = esRDD.filter(.......)
过滤以后数据量为12GB,此时考虑降低分区数目
etlRDD.coalesce(35)
2、当将分析结果RDD(resultRDD)保存到外部存储系统时,需要考虑降低分区数目
resultRDD.coalesce(1).foreachPartition()3,数据缓存函数
可以将RDD数据缓存到内存中,如果内存不足的话,可以缓存到磁盘中,适当的数据缓存可以提升性能。
缓存函数
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()默认情况下缓存到Executor的内存中,RDD数据量大的时候会造成OOM内存溢出。我们需要使用如下函数设置缓存级别:
def persist(newLevel: StorageLevel): this.type缓存级别:
// 不缓存
val NONE = new StorageLevel(false, false, false, false)
// 缓存数据到磁盘
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) // 副本数
//缓存数据到内存(Executor中内存)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
// 是否将数据序列化以后存储内存中
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
// 缓存数据到内存和磁盘,当内存不足就缓存到磁盘,使用最多
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
// 缓存数据到系统内存中
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)具体设置如下:
datasRDD.persist(StorageLevel.MEMORY_AND_DISK_2)为什么要缓存数据?
RDD需要多次使用,RDD来之不易的时候。
释放函数:
def unpersist(blocking: Boolean = true): this.type4,聚合函数
列表中的聚合函数:
def reduce[A1 >: A](op: (A1, A1) => A1): A1
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1
z: 表示聚合中间临时变量的初始值,fold聚合函数比reduce聚合函数:可以设置聚合中间变量初始值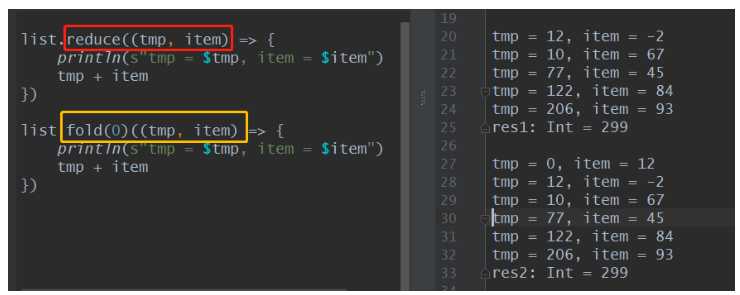
RDD中的聚合函数:
def reduce(f: (T, T) => T): T
// 可以初始化聚合中间临时变量的值
def fold(zeroValue: T)(op: (T, T) => T): T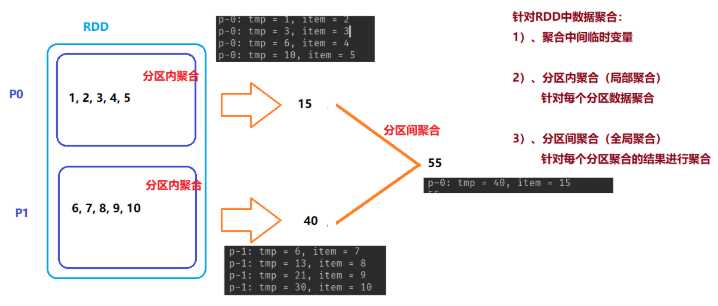
5,关联函数
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark中RDD的关联操作
*/
object SparkJoinFunc {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkContext上下文实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 创建SparkContext, 有就获取,没有就创建,建议使用
val context = SparkContext.getOrCreate(sparkConf)
// c. 返回对象
context
}
sc.setLogLevel("WARN")
// 模拟数据集
val empRDD: RDD[(Int, String)] = sc.parallelize(
Seq((1001, "zhangsan"), (1001, "lisi"), (1002, "wangwu"), (1002, "zhangliu"))
)
val deptRDD: RDD[(Int, String)] = sc.parallelize(
Seq((1001, "sales"), (1002, "tech"))
)
val joinRDD: RDD[(Int, (String, String))] = empRDD.join(deptRDD)
joinRDD.foreach{case (deptno, (ename, dname)) =>
println(s"deptno = $deptno, ename = $ename, dname = $dname")
}
// 应用结束,关闭资源
sc.stop()
}
}五,数据源
1,Mysql数据库交互
保存数据到Mysql:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 将词频统计结果保存到MySQL表中
*/
object SparkWriteMySQL {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkContext上下文实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 创建SparkContext, 有就获取,没有就创建,建议使用
val context = SparkContext.getOrCreate(sparkConf)
// c. 返回对象
context
}
sc.setLogLevel("WARN")
// TODO: 读取本地文件系统文本文件数据
val datasRDD: RDD[String] = sc.textFile("datas/wordcount/input/wordcount.data", minPartitions = 2)
// 词频统计
val resultRDD: RDD[(String, Int)] = datasRDD
// 数据分析,考虑过滤脏数据
.filter(line => null != line && line.trim.length > 0)
// TODO: 分割单词,注意去除左右空格
.flatMap(line => line.trim.split("\\s+"))
// 转换为二元组,表示单词出现一次
.mapPartitions{iter =>
iter.map(word => (word, 1))
}
// 分组聚合,按照Key单词
.reduceByKey((tmp, item) => tmp + item)
// 输出结果RDD
resultRDD
// 对结果RDD保存到外部存储系统时,考虑降低RDD分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>
// val xx: Iterator[(String, Int)] = iter
saveToMySQL(iter)
}
// 应用结束,关闭资源
sc.stop()
}
/**
* 将每个分区中的数据保存到MySQL表中
*
* @param datas 迭代器,封装RDD中每个分区的数据
*/
def saveToMySQL(datas: Iterator[(String, Int)]): Unit = {
// a. 加载驱动类
Class.forName("com.mysql.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// b. 获取连接
conn = DriverManager.getConnection(
"jdbc:mysql://bigdata-cdh01.itcast.cn:3306/", "root", "123456"
)
// c. 获取PreparedStatement对象
val insertSql = "INSERT INTO test.tb_wordcount (word, count) VALUES(?, ?)"
pstmt = conn.prepareStatement(insertSql)
// d. 将分区中数据插入到表中,批量插入
datas.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setLong(2, count.toLong)
// 加入批次
pstmt.addBatch()
}
// TODO: 批量插入
pstmt.executeBatch()
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
从Mysql读取数据:
JdbcEDD:
class JdbcRDD[T: ClassTag](
// 表示SparkContext实例对象
sc: SparkContext,
// 连接数据库Connection
getConnection: () => Connection,
// 查询SQL语句
sql: String,
// 下限
lowerBound: Long,
// 上限
upperBound: Long,
// 封装数据RDD的分区数目
numPartitions: Int,
// 表示读取出MySQL数据库表中每条数据如何处理,数据封装在ResultSet
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _
) extends RDD[T](sc, Nil)具体 代码如下:
import java.sql.{DriverManager, ResultSet}
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从MySQL数据库表中读取数据
*/
object SparkReadMySQL {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkContext上下文实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 创建SparkContext, 有就获取,没有就创建,建议使用
val context = SparkContext.getOrCreate(sparkConf)
// c. 返回对象
context
}
sc.setLogLevel("WARN")
// TODO: 读取MySQL数据库中db_orders.so表的数据
/*
class JdbcRDD[T: ClassTag](
// 表示SparkContext实例对象
sc: SparkContext,
// 连接数据库Connection
getConnection: () => Connection,
// 查询SQL语句
sql: String,
// 下限
lowerBound: Long,
// 上限
upperBound: Long,
// 封装数据RDD的分区数目
numPartitions: Int,
// 表示读取出MySQL数据库表中每条数据如何处理,数据封装在ResultSet
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _
)
*/
val sosRDD: JdbcRDD[(Long, Double)] = new JdbcRDD[(Long, Double)](
sc, //
() => {
// a. 加载驱动类
Class.forName("com.mysql.jdbc.Driver")
// b. 获取连接
val conn = DriverManager.getConnection(
"jdbc:mysql://bigdata-cdh01.itcast.cn:3306/", "root", "123456"
)
// c. 返回连接
conn
}, //
"select user_id, order_amt from db_orders.so where ? <= order_id and order_id <= ?", //
314296308301917L, //
314296313681142L, //
2, //
(rs: ResultSet) => {
// 获取user_id
val userId = rs.getLong("user_id")
// 获取order_amt
val orderAmt = rs.getDouble("order_amt")
// 返回二元组
(userId, orderAmt)
}
)
println(s"count = ${sosRDD.count()}")
sosRDD.foreach(println)
// 应用结束,关闭资源
sc.stop()
}
}
六,RDDCheckPoint
RDD将数据存在磁盘或者内存中进行持久化,但都存在不可靠性,数据都会丢失。
1,内存:数据存在Executor所在的内存中
2,磁盘:默认情况下,磁盘是Executor所在机器的磁盘。
CheckPoint的产生就是为了更加可靠的数据持久化,在CheckPoint的时候数据一般放在hdfs上,这天然的借助了hdfs的容错性,最大程度上的实现了数据的安全。
如何对RDD数据进行CheckPoint呢?
1,设置存储目录
sc.setCheckpointDir("/spark/ckpt")2,手动调用函数,将RDD进行CheckPoint
rdd.checkPoint()3,需要RDD的Action函数触发
代码演示
scala> sc.setCheckpointDir("/spark/ckpt")
scala> val datasRDD = sc.textFile("/datas/wordcount.input")
datasRDD: org.apache.spark.rdd.RDD[String] = /datas/wordcount.input MapPartitionsRDD[3] at textFile at <console>:24
scala> datasRDD.checkpoint()
scala> datasRDD.count()
res10: Long = 4
scala> datasRDD.count()
res11: Long = 4持久化和CheckPoint的区别?
位置:
Persist和Cache保存在本地的磁盘和内存中。
CheckPoint可以保存在Hdfs上面,程序结束也不会清除。
生命周期:
Persist和Catch的RDD会在程序结束或者手动调用unpersist方法清除
CheckPoint的RDD程序结束后仍然存在,不会被删除。
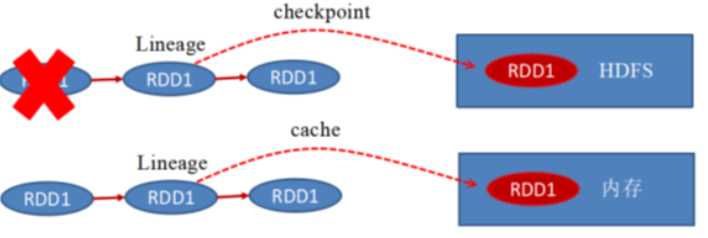
Lineage:
Persist和Cache,不会丢掉RDD间的依赖链也就是依赖关系,因为这种缓存是不可靠的,如果发现了错误,需要通过回溯法重新计算出来。
CheckPoint会斩断依赖链,因为lineage过长成本会高,因为CheckPoint会把结果保存在Hdfs上面,有很高的的容错性,如果检查点之后出现错误,直接在检查点开始计算就可以,可以减少很大的开销。
七,Spark名词解释
一个Spark Application运行在集群有两部部分组成:Driver Program和Executor
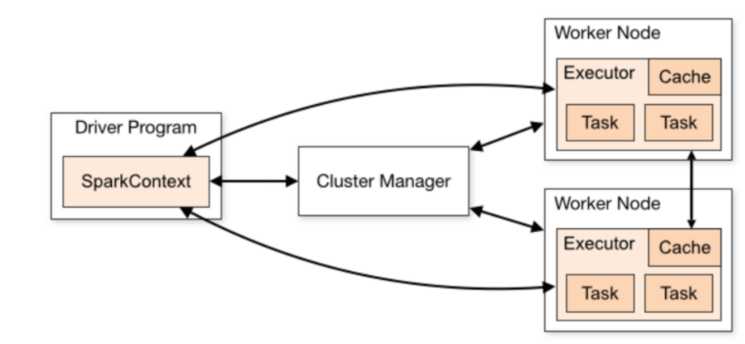
1,Application
指的是用户编写的Spark应用程序,包含了Driver的功能代码和分布在集群中多个节点的Executor代码。
2,Driver
Spark中Driver即运行在Application的Main函数并且创建SparkContext,Spark负责与Cluster Manager通信,进行资源的申请,任务的分配和监控等。
3,Cluster Manager
指的是集群上获取资源的外部服务,Standalone是Master,Yarn模式下ResourceManager。
4,Executor
运行在节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执行分区计算的任务的进程。
5,DAG
有向无环图,反应RDD之间的依赖关系和执行流程。
6,Job
作业,按照DAG执行就是一个作业DAG==Job
7,Stage
阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet。
8,Task
运行在Executor上的工作单元,一个Task计算一个分区。
以上是关于Spark入门02的主要内容,如果未能解决你的问题,请参考以下文章