在SQL语句中用PARALLEL指定并行查询,应该怎么用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在SQL语句中用PARALLEL指定并行查询,应该怎么用相关的知识,希望对你有一定的参考价值。
并行查询在sql语句上不用设置。是通过系统参数,将并行设置打开的。
oracle 11g中,parallel_degree_prolicy控制的,默认是manual关闭
在未开启的状态下,也可以对执行表进行并行处理
1. alter table table_name parallel;
2.也可以sql中加hits 如 select /*+ PARALLEL(t1, <degree>)*/ * from t1
<degree>如果不输入,是使用默认的值 参考技术A 并行查询在sql语句上不用设置。
是通过系统参数,将并行设置打开的。
oracle 11g中,parallel_degree_prolicy控制的,默认是manual关闭
在未开启的状态下,也可以对执行表进行并行处理
1. alter table table_name parallel;
2.也可以sql中加hits 如 select /*+ PARALLEL(t1, <degree>)*/ * from t1
<degree>如果不输入,是使用默认的值
:Using Parallel Execution 读书笔记
本文为Oracle 19c VLDB and Partitioning Guide第8章Using Parallel Execution的读书笔记。
并行执行是通过使用多个进程将多个 CPU 和 I/O 资源应用于执行单个 SQL 语句的能力。
8.1 Parallel Execution Concepts
并行执行允许将多个 CPU 和 I/O 资源应用于单个 SQL 语句的执行。
并行执行通常用于决策支持系统 (DSS) 和数据仓库,可显着减少数据密集型操作的响应时间。 也可以在联机事务处理 (OLTP) 系统上实现并行执行,以进行批处理或模式维护操作,例如创建索引。
并行执行有时称为并行性(parallelism)。 并行性是一种分解任务的想法,这样,多个进程同时完成部分工作,而不是一个进程完成查询中的所有工作。 例如,当四个进程结合起来计算一年的总销售额时,每个进程处理一年中的一个季度,而不是一个进程自己处理所有四个季度。
并行执行改进了以下方面的处理:
- 需要大表扫描、连接或分区索引扫描的查询
- 创建大型索引
- 创建大表,包括物化视图
- 批量插入、更新、合并和删除
8.1.1 When to Implement Parallel Execution
并行执行用于通过利用硬件中的 CPU 和 I/O 能力来减少查询的执行时间。
在以下情况下,并行执行是比串行执行更好的选择:
- 该查询引用了一个大型数据集。
- 并发性低。
- 实际耗时很重要。
并行执行使许多进程协同工作以执行单个操作,例如 SQL 查询。 并行执行使具有以下所有特征的系统受益:
- 对称多处理器 (SMP)、集群或大规模并行系统
- 足够的 I/O 带宽
- 未充分利用或间歇性使用的 CPU(例如,CPU 使用率通常低于 30% 的系统)
- 足够的内存来支持额外的内存密集型进程,例如排序、散列和 I/O 缓冲区
如果您的系统缺少这些特征中的任何一个,则并行执行可能不会显著提高性能。 事实上,并行执行可能会降低过度使用的系统或具有小 I/O 带宽的系统的系统性能。
在 DSS 和数据仓库环境中可以观察到并行执行的好处。 OLTP 系统还可以在批处理和模式维护操作(例如创建索引)期间从并行执行中受益。 表征 OLTP 应用程序的普通简单 DML 或 SELECT 语句不会从并行执行中获得任何好处。
按照这里和Wiki的说法,SELECT是不属于DML,而属于DQL
8.1.2 When Not to Implement Parallel Execution
串行执行与并行执行的不同之处在于只有一个进程执行单个数据库操作,例如 SQL 查询。
在以下情况下,串行执行是比并行执行更好的选择:
- 该查询引用了一个小型数据集。
- 有高并发。
- 效率很重要。
并行执行通常不适用于:
- 典型查询或事务非常短(几秒钟或更短)的环境。
这包括大多数在线交易系统。并行执行在这些环境中没有用处,因为协调并行执行服务器会产生成本;对于短事务,这种协调的成本可能超过并行的好处。 - 大量使用 CPU、内存或 I/O 资源的环境。
并行执行旨在利用额外的可用硬件资源;如果没有此类资源可用,则并行执行不会产生任何好处,并且实际上可能会损害性能。
8.1.3 Fundamental Hardware Requirements
并行执行旨在有效地使用多个 CPU 和磁盘来快速回答查询。
它本质上是非常 I/O 密集型的。为了实现最佳性能,硬件配置中的每个组件的大小必须保持相同的吞吐量水平:从计算节点中的 CPU 和主机总线适配器 (HBA),到交换机,再到 I/O 子系统,包括存储控制器和物理磁盘。如果系统是 Oracle Real Application Clusters (Oracle RAC) 系统,则还必须适当调整互连大小。最薄弱的环节将限制配置中操作的性能和可扩展性。
建议测量硬件配置在没有 Oracle 数据库的情况下可以实现的最大 I/O 性能。您可以将此测量用作未来系统性能评估的基准。请记住,并行执行不可能实现比底层硬件能够承受的更好的 I/O 吞吐量。 Oracle 数据库提供了一个名为 Orion 的免费校准工具,旨在通过模拟 Oracle I/O 工作负载来测量系统的 I/O 性能。并行执行通常执行大型随机 I/O。
8.1.4 How Parallel Execution Works
并行执行分解了一项任务,因此,不是一个进程完成查询中的所有工作,而是许多进程同时完成一部分工作。
8.1.4.1 Parallel Execution of SQL Statements
每条 SQL 语句在解析时都会经历一个优化和并行化过程。
如果确定该语句是并行执行的,那么执行计划中会出现以下步骤:
- 用户会话或影子进程扮演协调器的角色,通常称为查询协调器 (QC) 或并行执行 (PX) 协调器。 QC 是启动并行 SQL 语句的会话。
- PX 协调器获取必要数量的进程,称为并行执行 (PX) 服务器。 PX 服务器是代表发起会话并行执行工作的各个进程。
- SQL 语句作为一系列操作执行,例如全表扫描或 ORDER BY 子句。如果可能,每个操作都并行执行。
- 当 PX 服务器完成执行语句时,PX 协调器将执行任何无法并行执行的工作部分。例如,使用 SUM() 操作的并行查询需要添加由每个 PX 服务器计算的各个小计。
- 最后,PX 协调器将结果返回给用户。
8.1.4.2 Producer/Consumer Model
并行执行使用生产者/消费者模型。
并行执行计划作为一系列生产者/消费者操作来执行。 为后续操作生成数据的并行执行 (PX) 服务器称为生产者,需要其他操作输出的 PX 服务器称为消费者。 每个生产者或消费者并行操作由一组称为 PX 服务器集的 PX 服务器执行。 PX 服务器集中的 PX 服务器数量称为并行度 (DOP)。 PX 服务器集的基本工作单元称为数据流操作 (DFO)。
一个 PX 协调器可以有多个级别的生产者/消费者操作(多个 DFO),但一个 PX 协调器的 PX 服务器集的数量限制为两个。 因此,在某个时间点,一个 PX 协调器只能激活两个 PX 服务器集。 因此,DFO 中的操作和 DFO 之间的操作都存在并行性。 单个 DFO 的并行度称为操作内并行度,DFO 之间的并行度称为操作间并行度。 为了说明操作内和操作间的并行性,请考虑以下语句:
SELECT * FROM employees ORDER BY last_name;
执行计划实现了对雇员表的全面扫描。 此操作之后是根据 last_name 列的值对检索到的行进行排序。 假设 last_name 列没有被索引。 还假设查询的 DOP 设置为 4,这意味着四个并行执行服务器可以为任何给定操作处于活动状态。
图 8-1 说明了示例查询的并行执行。
图 8-1 操作间并行和动态分区
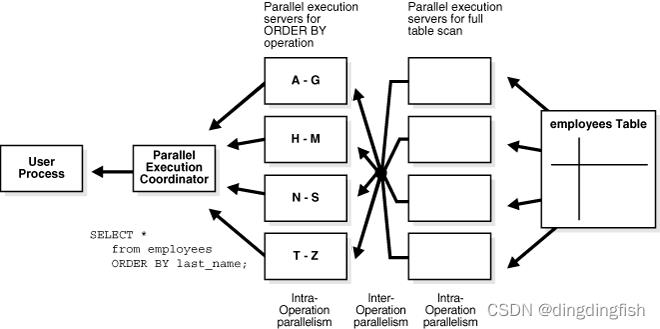
如图 8-1 所示,尽管 DOP 为 4,但实际上有 8 个 PX 服务器参与了查询。这是因为生产者和消费者操作员可以同时执行(互操作并行性)。
此外,扫描操作中涉及的所有 PX 服务器都将行发送到执行 SORT 操作的相应 PX 服务器。 如果 PX 服务器扫描的行包含 A 和 G 之间的 last_name 列的值,则该行将发送到第一个 ORDER BY 并行执行服务器。 当扫描操作完成后,排序进程可以将排序后的结果返回给查询协调器,查询协调器将完整的查询结果返回给用户。
8.1.4.3 Granules of Parallelism
并行性的基本工作单元是称为颗粒。
Oracle 数据库将并行执行的操作(例如表扫描或索引创建)划分为颗粒。 并行执行 (PX) 服务器一次执行一个颗粒的操作。 颗粒的数量及其大小与并行度 (DOP) 相关。 颗粒的数量也会影响工作在 PX 服务器之间的平衡程度。
8.1.4.3.1 Block Range Granules
块范围颗粒是大多数并行操作的基本单元,即使在分区表上也是如此。从 Oracle 数据库的角度来看,并行度与分区数无关。
块范围颗粒是表中物理块的范围。 Oracle 数据库在运行时计算颗粒的数量和大小,以优化和平衡所有受影响的并行执行 (PX) 服务器的工作分配。颗粒的数量和大小取决于对象的大小和 DOP。块范围颗粒不依赖于表或索引的静态预分配。在计算粒度期间,Oracle 数据库将 DOP 考虑在内,并尝试将来自不同数据文件的粒度分配给每个 PX 服务器,以尽可能避免争用。此外,Oracle 数据库考虑大规模并行处理 (MPP) 系统上的颗粒的磁盘亲和性,以利用 PX 服务器和磁盘之间的物理亲和性。
8.1.4.3.2 Partition Granules
当使用分区颗粒时,并行执行 (PX) 服务器在表或索引的整个分区或子分区上工作。
因为在创建表或索引时,分区颗粒是由表或索引的结构静态确定的,所以分区颗粒不能像块颗粒那样为您提供并行执行操作的灵活性。最大允许并行度 (DOP) 是分区数。这可能会限制系统的利用率和跨 PX 服务器的负载平衡。
当使用分区颗粒对表或索引进行并行访问时,您应该使用相对大量的分区,最好是 DOP 的 3 倍,以便 Oracle 数据库可以有效地平衡 PX 服务器之间的工作。
分区颗粒是并行索引范围扫描的基本单元,查询优化器选择使用分区连接的两个等分区表之间的连接,以及修改分区对象的多个分区的并行操作。这些操作包括并行创建分区索引和并行创建分区表。
您可以通过查看语句的执行计划来判断使用了哪些类型的颗粒。 表或索引访问上方的 PX BLOCK ITERATOR 行表示已使用块范围颗粒。 在下面的示例中,您可以在 SALES 表的 TABLE FULL ACCESS 上方的解释计划输出的第 7 行看到这一点。
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - filter("CUST_ID"<=22810 AND "CUST_ID">=22300)
使用分区颗粒时,您会在说明计划输出中看到表或索引访问上方的 PX PARTITION RANGE 行。 在下面示例的第 6 行,计划具有 PX PARTITION RANGE ALL,因为该语句访问表中的所有 16 个分区。 如果没有访问所有分区,它只会显示 PX PARTITION RANGE。
---------------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001 | 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000 | 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES | 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST| 26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - access("CUST_ID"<=22810 AND "CUST_ID">=22300)
8.1.4.4 Distribution Methods Between Producers and Consumers
分发方法是将数据从一个并行执行 (PX) 服务器集发送(或重新分发)到另一台服务器的方法。
以下是并行执行中最常用的分发方法。
-
哈希分布
哈希分发方法在行中的一个或多个列上使用散列函数,然后确定生产者应该将行发送到哪里的消费者。这种分发试图根据哈希值在消费者之间平均分配工作。 -
广播分发
在广播分发方法中,每个生产者将所有行发送给所有消费者。当join操作中左侧的结果集较小且广播所有行的成本不高时使用此方法。在这种情况下,连接右侧的结果集不需要分发;分配给连接操作的消费者 PX 服务器可以扫描右侧并执行连接。 -
范围分发
范围分发主要用于并行排序操作。在此方法中,每个生产者将具有一系列值的行发送给同一消费者。这就是图 8-1 中使用的方法。 -
混合哈希分发
混合哈希是一种用于连接操作的自适应分布方法。实际的分发方式由优化器在运行时根据连接左侧结果集的大小来决定。对从左侧返回的行数进行计数并根据阈值进行检查。当行数小于或等于阈值时,join的左侧使用广播分发,右侧不分发,因为分配给join操作的相同消费者PX服务器扫描右侧和执行连接。当从左侧返回的行数高于阈值时,连接的两边都使用哈希分发。
虽然很分区很类似,但这里说的是分发
为了确定分发方法,并行执行 (PX) 协调器检查 SQL 语句的执行计划中的每个操作,然后确定操作所操作的行必须在 PX 服务器之间重新分发的方式。 作为并行查询的示例,请考虑示例 8-1 中的查询。 图 8-2 说明了示例 8-1 中查询的数据流或查询计划,示例 8-2 显示了相同查询的解释计划输出。
查询计划显示 PX 协调器选择了一种自适应分布方法。 假设优化器在运行时选择散列分布,执行过程如下:为查询分配两组 PX 服务器,SS1 和 SS2,由于指定语句 DOP 的 PARALLEL 提示,每个服务器组有四个 PX 服务器 .
PX 集SS1 首先扫描表customers 并将行发送到SS2,SS2 在这些行上构建一个哈希表。 换句话说,SS2 中的消费者和 SS1 中的生产者同时工作:一个并行扫描客户,另一个并行消费行并构建哈希表以启用哈希联接。 这是操作间并行性的一个示例。
SS1 中的 PX 服务器进程扫描客户表中的一行后,应该将其发送到 SS2 中的哪个 PX 服务器进程? 在这种情况下,从执行客户并行扫描的 SS1 向上流入执行并行哈希连接的 SS2 的行的重新分发是通过连接列上的哈希分配完成的。 也就是说,扫描客户的 PX 服务器进程会根据列customers.cust_id 的值计算哈希函数,以决定将其发送到 SS2 中的哪个 PX 服务器进程。 使用的重新分发方法明确显示在查询的 EXPLAIN PLAN 的 Distrib 列中。 在图 8-2 中,可以在 EXPLAIN PLAN 的第 5、9 和 14 行看到这一点。
SS1 扫描完整个customers 表后,并行扫描sales 表。 它将其行发送到 SS2 中的 PX 服务器,然后执行探测以并行完成哈希连接。 这些 PX 服务器还在JOIN后执行 GROUP BY 操作。 在 SS1 并行扫描了 sales 表并将行发送到 SS2 之后,它切换到并行执行最后的 group by 操作。 此时,SS2 中的 PX 服务器使用哈希分发将它们的行发送到 SS1 上的 PX 服务器,以进行分组操作。 这就是两个服务器集如何同时运行以实现查询树中各种运算符之间的操作间并行性。
图 8-2 连接表的数据流图

示例 8-1 为客户和销售查询运行解释计划
EXPLAIN PLAN FOR
SELECT /*+ PARALLEL(4) */ customers.cust_first_name, customers.cust_last_name,
MAX(QUANTITY_SOLD), AVG(QUANTITY_SOLD)
FROM sales, customers
WHERE sales.cust_id=customers.cust_id
GROUP BY customers.cust_first_name, customers.cust_last_name;
Explained.
示例 8-2 有关客户和销售的查询的解释计划输出
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3260900439
---------------------------------------------------------------------------------------------------------------------------------------
|Id |Operation |Name |Rows | Bytes |TempSpc|Cost (%CPU)| Time |Pstart|Pstop | TQ |IN-OUT|PQ Distrib |
---------------------------------------------------------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 960 | 26880 | | 6 (34)| 00:00:01 | | | | | |
| 1 | PX COORDINATOR | | | | | | | | | | | |
| 2 | PX SEND QC (RANDOM) |:TQ10003 | 960 | 26880 | | 6 (34)| 00:00:01 | | | Q1,03 | P->S |QC (RAND) |
| 3 | HASH GROUP BY | | 960 | 26880 | 50000 | 6 (34)| 00:00:01 | | | Q1,03 | PCWP | |
| 4 | PX RECEIVE | | 960 | 26880 | | 6 (34)| 00:00:01 | | | Q1,03 | PCWP | |
| 5 | PX SEND HASH |:TQ10002 | 960 | 26880 | | 6 (34)| 00:00:01 | | | Q1,02 | P->P |HASH |
| 6 | HASH GROUP BY | | 960 | 26880 | 50000 | 6 (34)| 00:00:01 | | | Q1,02 | PCWP | |
|* 7 | HASH JOIN | | 960 | 26880 | | 5 (20)| 00:00:01 | | | Q1,02 | PCWP | |
| 8 | PX RECEIVE | | 630 | 12600 | | 2 (0)| 00:00:01 | | | Q1,02 | PCWP | |
| 9 | PX SEND HYBRID HASH |:TQ10000 | 630 | 12600 | | 2 (0)| 00:00:01 | | | Q1,00 | P->P |HYBRID HASH|
| 10 | STATISTICS COLLECTOR | | | | | | | | | Q1,00 | PCWC | |
| 11 | PX BLOCK ITERATOR | | 630 | 12600 | | 2 (0)| 00:00:01 | | | Q1,00 | PCWC | |
| 12 | TABLE ACCESS FULL |CUSTOMERS| 630 | 12600 | | 2 (0)| 00:00:01 | | | Q1,00 | PCWP | |
| 13 | PX RECEIVE | | 960 | 7680 | | 2 (0)| 00:00:01 | | | Q1,02 | PCWP | |
| 14 | PX SEND HYBRID HASH |:TQ10001 | 960 | 7680 | | 2 (0)| 00:00:01 | | | Q1,01 | P->P |HYBRID HASH|
| 15 | PX BLOCK ITERATOR | | 960 | 7680 | | 2 (0)| 00:00:01 | 1 | 16 | Q1,01 | PCWC | |
| 16 | TABLE ACCESS FULL |SALES | 960 | 7680 | | 2 (0)| 00:00:01 | 1 | 16 | Q1,01 | PCWP | |
---------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("SALES"."CUST_ID"="CUSTOMERS"."CUST_ID")
Note
-----
- Degree of Parallelism is 4 because of hint
8.1.4.5 How Parallel Execution Servers Communicate
为了并行执行查询,Oracle 数据库通常会创建一组生产者并行执行服务器和一组消费者并行执行服务器。
生产者服务器从表中检索行,消费者服务器对这些行执行连接、排序、DML 和 DDL 等操作。 生产者集中的每个服务器都与消费者集中的每个服务器都有连接。 并行执行服务器之间的虚拟连接数随着并行度的平方而增加。
每个通信通道至少有一个,有时最多四个内存缓冲区,它们是从共享池中分配的。 多个内存缓冲区有助于并行执行服务器之间的异步通信。
单实例环境对每个通信通道最多使用三个缓冲区。 Oracle Real Application Clusters 环境对每个通道最多使用四个缓冲区。 图 8-3 说明了消息缓冲区以及生产者并行执行服务器如何连接到消费者并行执行服务器。
图 8-3 并行执行服务器连接和缓冲区

当连接在同一实例上的两个进程之间时,服务器通过在内存中(在共享池中)来回传递缓冲区进行通信。 当连接在不同实例中的进程之间时,使用外部高速网络协议通过互连发送消息。 在图 8-3 中,DOP 等于并行执行服务器的数量,在本例中为 n。 图 8-3 没有显示并行执行协调器。 每个并行执行服务器实际上都有一个到并行执行协调器的附加连接。 使用并行执行时,充分调整共享池的大小很重要。 如果共享池中没有足够的可用空间来为并行服务器分配必要的内存缓冲区,它将无法启动。
8.1.5 Parallel Execution Server Pool
当一个实例启动时,Oracle 数据库创建一个并行执行服务器池,可用于任何并行操作。
初始化参数 PARALLEL_MIN_SERVERS 指定 Oracle 数据库在实例启动时创建的并行执行服务器的数量。
在执行并行操作时,并行执行协调器从池中获取并行执行服务器并将它们分配给该操作。如有必要,Oracle 数据库可以为操作创建额外的并行执行服务器。这些并行执行服务器在整个执行过程中与操作保持一致。处理完语句后,并行执行服务器返回到池中。
如果并行操作的数量增加,Oracle 数据库会创建额外的并行执行服务器来处理传入请求。但是,Oracle 数据库为实例创建的并行执行服务器永远不会超过初始化参数 PARALLEL_MAX_SERVERS 指定的值。
如果并行操作的数量减少,Oracle 数据库将终止任何已空闲达阈值时间间隔的并行执行服务器。无论并行执行服务器空闲多长时间,Oracle 数据库都不会将池的大小减小到小于 PARALLEL_MIN_SERVERS 的
以上是关于在SQL语句中用PARALLEL指定并行查询,应该怎么用的主要内容,如果未能解决你的问题,请参考以下文章