Kafka needs no Keeper(关于KIP-500的讨论)
Posted huxi2b
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka needs no Keeper(关于KIP-500的讨论)相关的知识,希望对你有一定的参考价值。
写在前面的
最近看了Kafka Summit上的这个分享,觉得名字很霸气,标题直接沿用了。这个分享源于社区的KIP-500,大体的意思今后Apache Kafka不再需要ZooKeeper。整个分享大约40几分钟。完整看下来感觉干货很多,这里特意总结出来。如果你把这个分享看做是《三国志》的话,那么姑且就把我的这篇看做是裴松之注吧:)
客户端演进
首先,社区committer给出了Kafka Java客户端移除ZooKeeper依赖的演进过程。下面两张图总结了0.8.x版本和0.11.x版本(是否真的是从0.11版本开始的变化并不重要)及以后的功能变迁:在Kafka 0.8时代,Kafka有3个客户端,分别是Producer、Consumer和Admin Tool。其中Producer负责向Kafka写消息,Consumer负责从Kafka读消息,而Admin Tool执行各种运维任务,比如创建或删除主题等。其中Consumer的位移数据保存在ZooKeeper上,因此Consumer端的位移提交和位移获取操作都需要访问ZooKeeper。另外Admin Tool执行运维操作也要访问ZooKeeper,比如在对应的ZooKeeper znode上创建一个临时节点,然后由预定义的Watch触发相应的处理逻辑。
后面随着Kafka的演进,社区引入了__consumer_offsets位移主题,同时定义了OffsetFetch和OffsetCommit等新的RPC协议,这样Consumer的位移提交和位移获取操作全部转移到与位移主题进行交互,避免了对ZooKeeper的访问。同时社区引入了新的运维工具AdminClient以及相应的CreateTopics、DeleteTopics、AlterConfigs等RPC协议,替换了原先的Admin Tool,这样创建和删除主题这样的运维操作也完全移动Kafka这一端来做,就像下面右边这张图展示的:
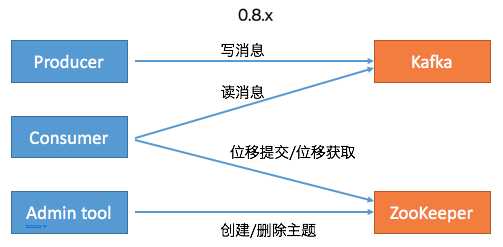
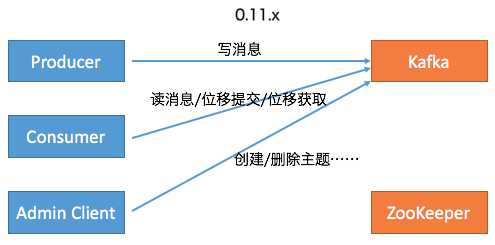
至此, Kafka的3个客户端基本上都不需要和ZooKeeper交互了。应该说移除ZooKeeper的工作完成了大部分,但依然还有一部分工作要在ZooKeeper的帮助下完成,即Consumer的Rebalance操作。在0.8时代,Consumer Group的管理是交由ZooKeeper完成的,包括组成员的管理和订阅分区的分配。这个设计在新版Consumer中也得到了修正。全部的Group管理操作交由Kafka Broker端新引入的Coordinator组件来完成。要完成这些工作,Broker端新增了很多RPC协议,比如JoinGroup、SyncGroup、Heartbeat、LeaveGroup等。
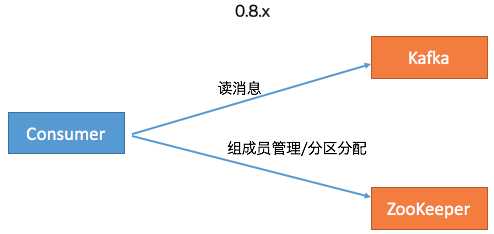
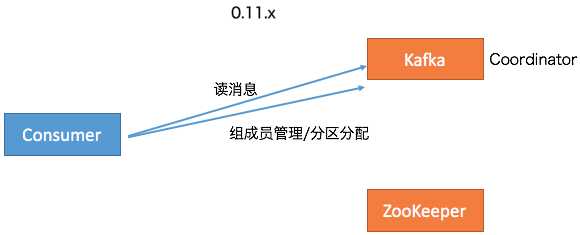
此时,Kafka的Java客户端除了AdminClient还有一点要依赖ZooKeeper之外,所有其他的组件全部摆脱了对ZooKeeper的依赖。
之后,社区引入了Kafka安全层,实现了对用户的认证和授权。这个额外的安全层也是不需要访问ZooKeeper的,因此之前依赖ZooKeeper的客户端是无法“享用”这个安全层。一旦启用,新版Clients都需要首先接入这一层并通过审核之后才能访问到Broker,如下图所示:
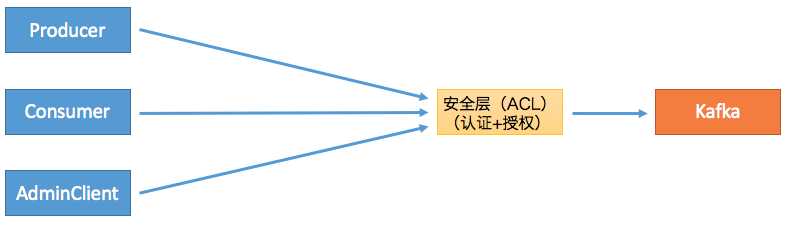
这么做的好处在于统一了Clients访问Broker的模式,即定义RPC协议,比如我们熟知的PRODUCE协议、FETCH协议、METADATA协议、CreateTopics协议等。如果后面需要实现更多的功能,社区只需要定义新的RPC协议即可。同时新引入的安全层负责对这套RPC协议进行安全校验,统一了访问模式。另外这些协议都是版本化的(versioned),因此能够独立地进行演进,同时也兼顾了兼容性方面的考量。
Broker间交互
说完了Clients端,我们说下Broker端的现状。目前,应该说Kafka Broker端对ZooKeeper是重度依赖的,主要表现在以下几个方面:
- Broker注册管理
- ACL安全层配置管理
- 动态参数管理
- 副本ISR管理
- Controller选举
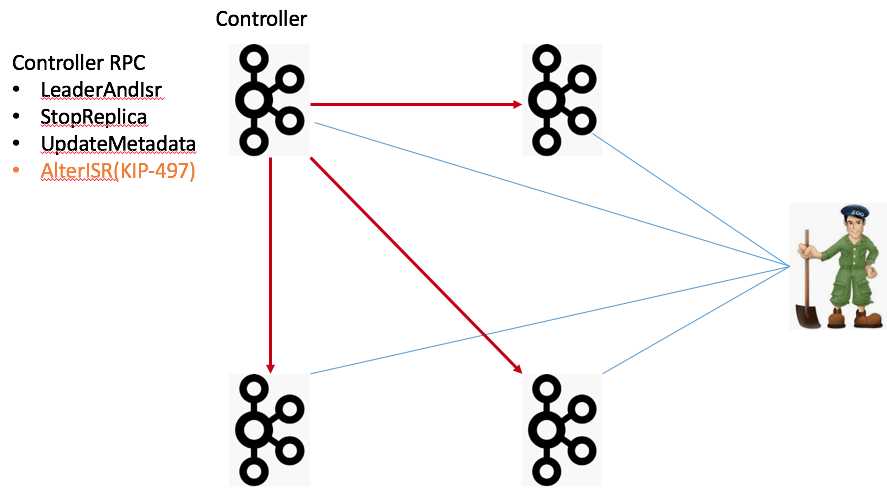
我们拿一张图来说明,图中有4个Broker节点和一个ZooKeeper,左上角的Broker充当Controller的角色。当前,所有的Broker启动后都必须维持与ZooKeeper的会话。Kafka依赖于这个会话实现Broker端的注册,而且Kafka集群中的所有配置信息、副本信息、主题信息也都保存在ZooKeeper上。最后Controller与集群中每个Broker都维持了一个TCP长连接用于向这些Broker发送RPC请求。当前的Controller RPC类型主要有3大类:
- LeaderAndIsr:主要用于向集群广播主题分区Leader和ISR的变更情况,比如对应的Broker应该是特定分区的Leader还是Follower
- StopReplica:向集群广播执行停止副本的命令
- UpdateMetadata:向集群广播执行变更元数据信息的命令
图中还新增了一个AlterISR RPC,这是KIP-497要实现的新RPC协议。现阶段Kafka各个主题的ISR信息全部保存在ZooKeeper中。如果后续要舍弃ZooKeeper,必须要将这些信息从ZooKeeper中移出来,放在了Controller一端来做。同时还要在程序层面支持对ISR的管理。因此社区计划在KIP-497上增加AlterISR协议。对了,还要提一句,当前Controller的选举也是依靠ZooKeeper完成的。
所以后面Broker端的演进可能和Clients端的路线差不多:首先是把Broker与ZooKeeper的交互全部干掉,只让Controller与ZooKeeper进行交互,而其他所有Broker都只与Controller交互,如下图所示:
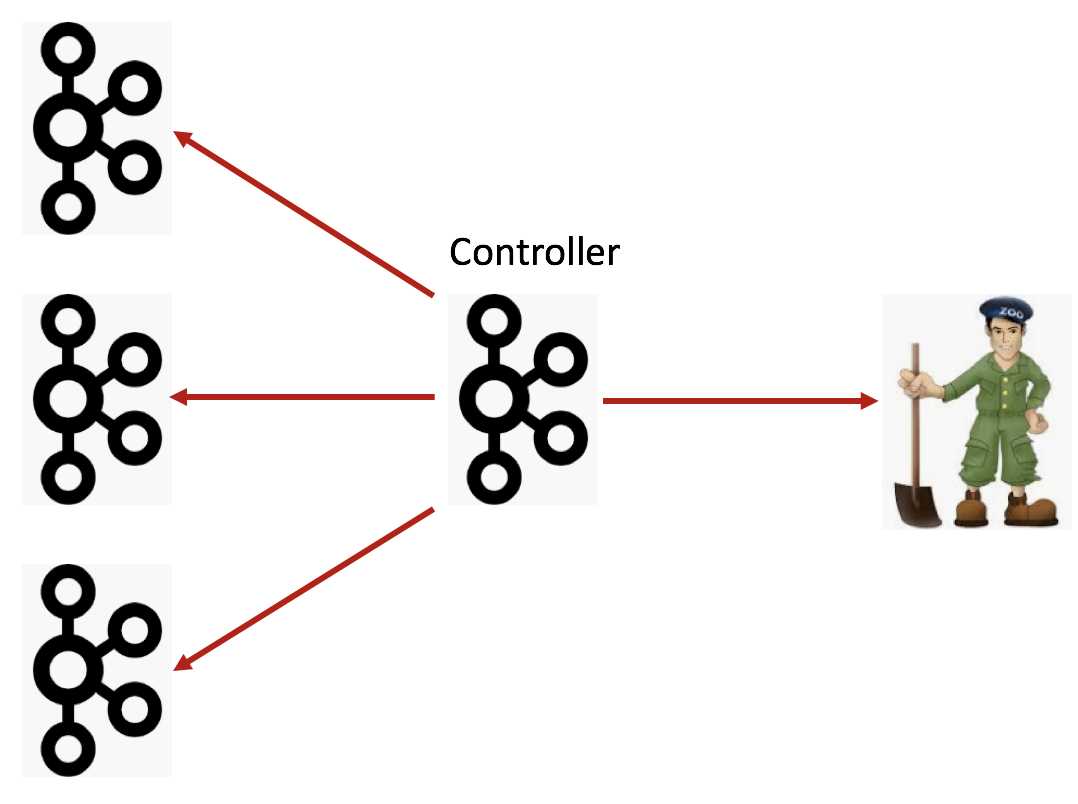
看上去这种演进路线社区已经走得轻车熟路了,但实际上还有遗留了一些问题需要解决。
Broker Liveness
首先就是Broker的liveness问题,即Kafka如何判断一个Broker到底是否存活?在目前的设计中,Broker的生存性监测完全依赖于与ZooKeeper之间的会话。一旦会话超时或断开Controller自动触发ZooKeeper端的Watch来移除该Broker,并对其上的分区做善后处理。如果移除了ZooKeeper,Kafka应该采用什么机制来判断Broker的生存性是一个问题。
Network Partition
如何防范网络分区也是一个需要讨论的话题。当前可能出现的Network Partition有4种:1、单个Broker完全与集群隔离;2、Broker间无法通讯;3、Broker与ZooKeeper无法通讯;4、Broker与Controller无法通讯。下面4张图分别展示了这4种情况:
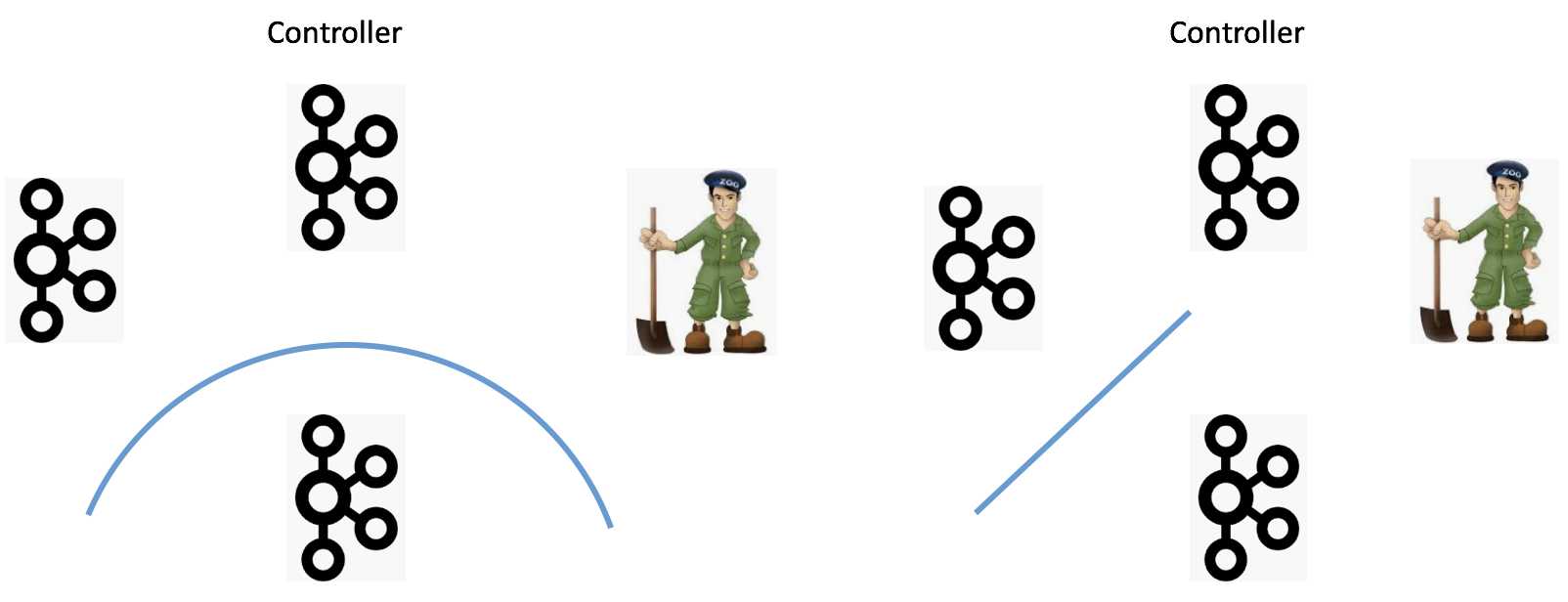
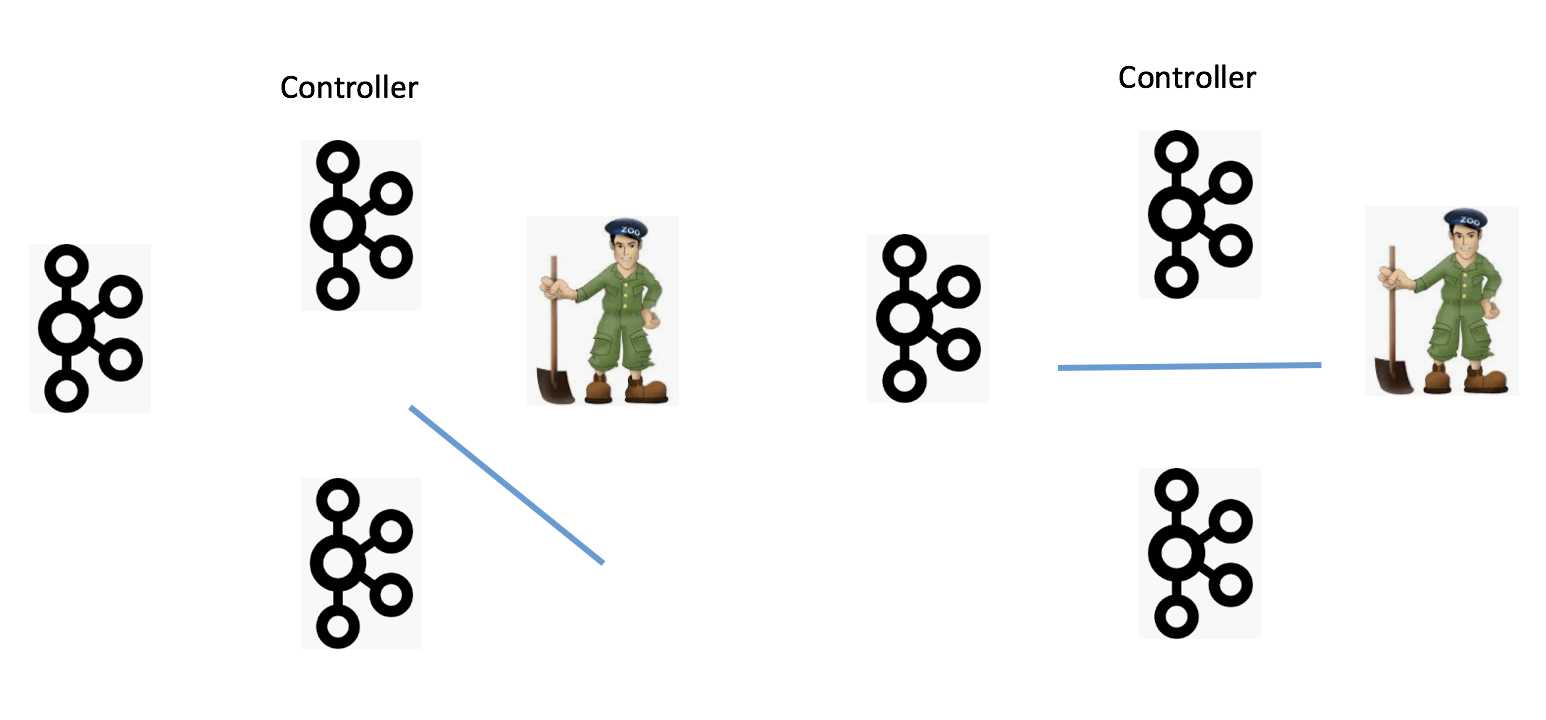
我们分别讨论下。首先是第一种情况,单Broker与集群其他Broker隔离,这其实并不算太严重的问题。当前的设计已然能够保证很好地应对此种情况。一旦Broker被隔离,Controller会将其从集群中摘除,虽然可用性降低了,但是整个集群的一致性依然能够得到保证。第二种情况是Broker间无法通讯,可能的后果是消息的备份机制无法执行,Kafka要收缩ISR,依然是可用性上的降低,但是一致性状态并没有被破坏。情况三是Broker无法与ZooKeeper通讯。Broker能正常运转,它只是无法与ZooKeeper进行通讯。此时我们说该Broker处于僵尸状态,即所谓的Zoobie状态。因Zoobie状态引入的一致性bug社区jira中一直没有断过,社区这几年也一直在修正这方面的问题,主要对抗的机制就是fencing。比如leader epoch等。最后一类情况是Broker无法与Controller通讯,那么所有的元数据更新通道被堵死,即使这个Broker依然是healthy的,但是它保存的元数据信息可能是非常过期的。这样连接该Broker的客户端可能会看到各种非常古怪的问题。之前在知乎上回答过类似的问题:https://www.zhihu.com/question/313683699/answer/609887054。目前,社区对这种情况并没有太好的解决办法,主要的原因是Broker的liveness完全交由ZooKeeper来做的。一旦Broker与ZooKeeper之间的交互没有问题,其他原因导致的liveness问题就无法彻底规避。
第四类Network Partition引入了一个经典的场景:元数据不一致。目前每个Broker都缓存了一份集群的元数据信息,这份数据是异步更新的。当第四类Partition发生时,Broker端缓存的元数据信息必然与Controller的不同步,从而造成各种各样的问题。
下面简要介绍一下元数据更新的过程。主要的流程就是Controller启动时会同步地从ZooKeeper上拉取集群全量的元数据信息,之后再以异步的方式同步给其他Broker。其他Broker与Controller之间的同步往往有一个时间差,也就是说可能Clients访问的元数据并不是最新的。我个人认为现在社区很多flaky test failure都是因为这个原因导致的。 事实上,实际使用过程中有很多场景是Broker端的元数据与Controller端永远不同步。通常情况下如果我们不重启Broker的话,那么这个Broker上的元数据将永远“错误”下去。好在社区还给出了一个最后的“大招”: 登录到ZooKeeper SHELL,手动执行rmr /controller,强迫Controller重选举,然后重新加载元数据,并给所有Broker重刷一份。不过在实际生产环境,我怀疑是否有人真的要这么干,毕竟代价不小,而且最关键的是这么做依然可能存在两个问题:1. 我们如何确保Controller和Broker的数据是一致的?2. 加载元数据的过程通常很慢。
这里详细说说第二点,即加载元数据的性能问题。总体来说,加载元数据是一个O(N)时间复杂度的过程,这里的N就是你集群中总的分区数。考虑到Controller从ZooKeeper加载之后还要推给其他的Broker,那么做这件事的总的时间复杂度就是O(N * M),其中M是集群中Broker的数量。可以想见,当M和N都很大时,在集群中广播元数据不是一个很快的过程。
Metadata as an Event Log
Okay,鉴于以上所提到的所有问题,当Kafka抛弃了ZooKeeper之后,社区应该如何解决它们呢?总体的思路就是Metadata as an Event Log + Controller quorum。我们先说metadata as an event log。如果你读过Jay Kreps的《I ??Logs》,你应该有感触,整个Kafka的架构其实都是构建在Log上的。每个topic的分区本质上就是一个Commit Log,但元数据信息的保存却不是Log形式。在现有的架构设计中你基本上可以认为元数据的数据结构是KV形式的。这一次,社区采用了与消息相同的数据保存方式,即将元数据作为Log的方式保存起来,如下表所示:
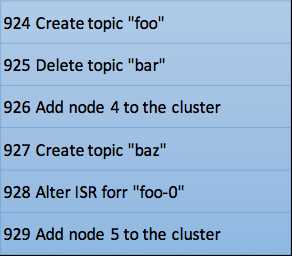
这样做的好处在于每次元数据的变更都被当做是一条消息保存在Log中,而这个Log可以被视作是一个普通的Kafka主题被备份到多台Broker上。Log的一个好处在于它有清晰的前后顺序关系,即每个事件发生的时间是可以排序的,配合以恰当的处理逻辑,我们就能保证对元数据变更的处理是按照变更发生时间顺序处理,不出现乱序的情形。另外Log机制还有一个好处是,在Broker间同步元数据时,我们可以选择同步增量数据(delta),而非全量状态。现在Kafka Broker间同步元数据都是全量状态同步的。前面说过了,当集群分区数很大时,这个开销是很可观的。如果我们能够只同步增量状态,势必能极大地降低同步成本。最后一个好处是,我们可以很容易地量化元数据同步的进度,因为对Log的消费有位移数据,因此通过监控Log Lag就能算出当前同步的进度或是落后的进度。
采用Log机制后,其他Broker像是一个普通的Consumer,从Controller拉取元数据变更消息或事件。由于每个Broker都是一个Consumer,所以它们会维护自己的消费位移,就像下面这张图一样:
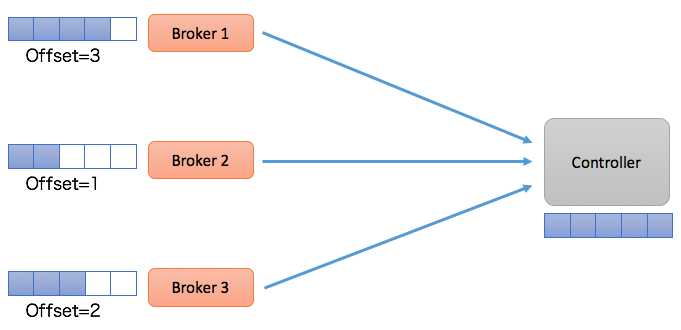
这种设计下,Controller所在的Broker必须要承担起所有元数据topic的管理工作,包括创建topic、管理topic分区的leader以及为每个元数据变更创建相应的事件等。既然社区选择和__consumer_offsets类似的处理方式,一个很自然的问题在于这个元数据topic的管理是否能够复用Kafka现有的副本机制?答案是:不可行。理由是现有的副本机制依赖于Controller,因此Kafka没法依靠现有的副本机制来实现Controller——按照我们的俗语来说,这有点鸡生蛋、蛋生鸡的问题,属于典型的循环依赖。为了实现这个,Kafka需要一套leader选举协议,而这套协议或算法是不依赖于Controller的,即它是一个自管理的集群quorum(抱歉,在分布式领域内,特别是分布式共识算法领域中,针对quorum的恰当翻译我目前还未找到,因此直接使用quorum原词了)。最终社区决定采用Raft来实现这组quorum。这就是上面我们提到的第二个解决思路:Controller quorum。
Controller Quorum
与借助Controller帮忙选择Leader不同,Raft是让自己的节点自行选择Leader并最终令所有节点达成共识——对选择Controller而言,这是一个很好的特性。其实Kafka现有的备份机制与Raft已经很接近了,下表罗列了一下它们的异同:
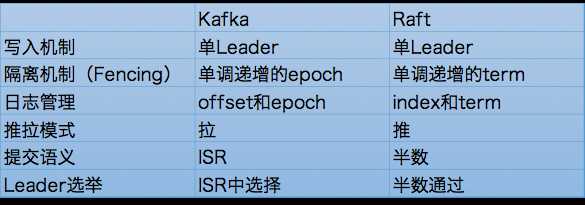
一眼扫过去,其实Kafka的备份机制和Raft很类似,比如Kafka中的offset其实就是Raft中的index,epoch对应于term。当然Raft中采用的半数机制来确保消息被提交以及Leader选举,而Kafka设计了ISR机制来实现这两点。总体来说,社区认为只需要对备份机制做一些小改动就应该可以很容易地切换到Raft-based算法。
下面这张图展示Controller quorum可能更加直观:
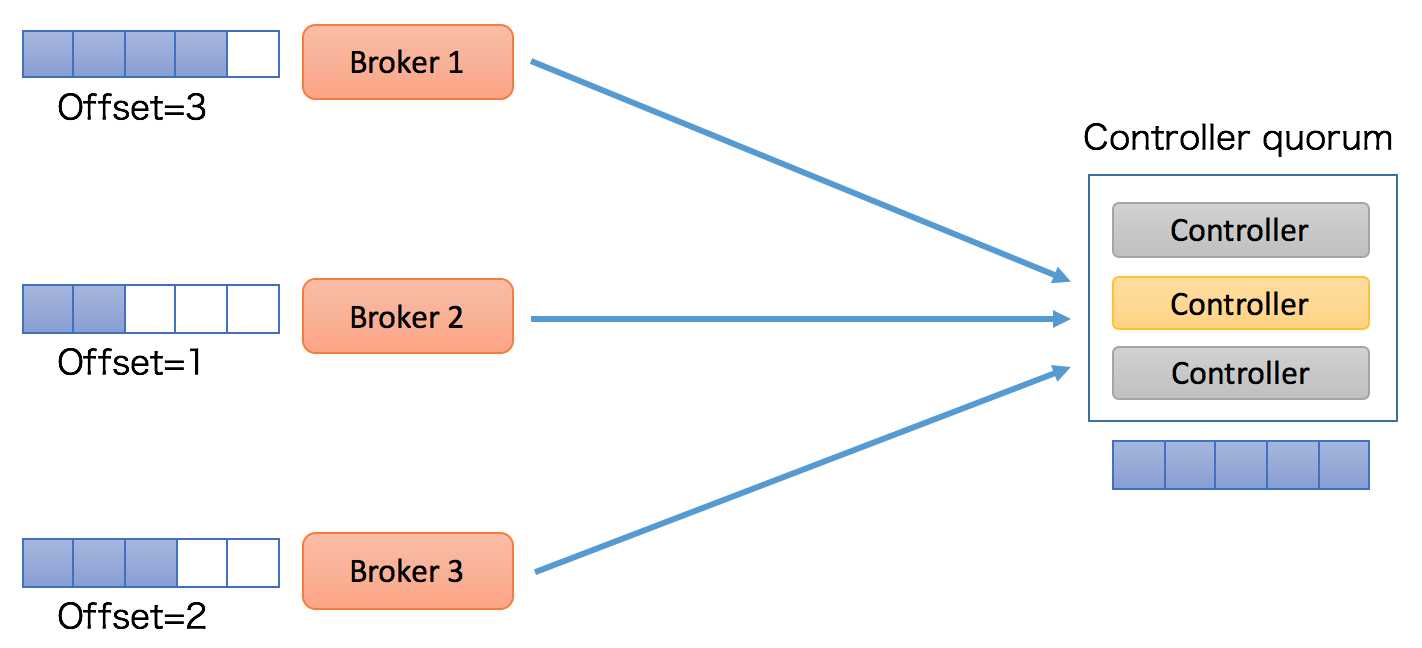
整个controller quorum类似于一个小的集群。和ZooKeeper类似,这个quorum通常是3台或5台机器,不需要让Kafka中的每个Broker都自动称为这个quorum中的一个节点。该quorum里面有一个Leader负责处理客户端发来的读写请求,这个Leader就是Kafka中的active controller。根据ZooKeeper的Zab协议,leader处理所有的写请求,而follower是可以处理读请求的。当写请求发送给follower后,follower会将该请求转发给leader处理。不过我猜Kafka应该不会这样实现,它应该只会让leader(即active controller)处理所有的读写请求,而客户端(也就是其他Broker)压根就不会发送读写请求给follower。在这一点上,这种设计和现有的Kafka请求处理机制是一致的。
现在还需要解决一个问题,即Leader是怎么被选出来的?既然是Raft-based,那么采用的也是Raft算法中的Leader选举策略。让Raft选出的Leader称为active controller。网上有很多关于Raft选主的文章,这里就不在赘述了,有兴趣的可以读一读Raft的论文:《In Search of an Understandable Consensus Algorithm(Extended Version)》。
这套Raft quorum的一个好处在于它天然提供了低延时的failover,因此leader的切换会非常的迅速和及时,因为理论上不再有元数据加载的过程了,所有的元数据现在都同步保存follower节点的内存中,它已经有其他Broker需要拉取的所有元数据信息了!更酷的是,它避免了现在机制中一旦Controller切换要全量拉取元数据的低效行为,Broker无需重新拉取之前已经“消费”的元数据变更消息,它只需要从新Leader继续“消费”即可。
另一个好处在于:采用了这套机制后,Kafka可以做元数据的缓存了(metadata caching):即Broker能够把元数据保存在磁盘上,同时就像刚才说的,Broker只需读取它关心的那部分数据即可。还有,和现在snapshot机制类似,如果一个Broker保存的元数据落后Controller太多或者是一个全新的Broker,Kafka甚至可以像Raft那样直接发送一个snapshot文件,快速令其追上进度。当然大多数情况下,Broker只需要拉取delta增量数据即可。
Post KIP-500 Broker注册
当前Broker启动之后会向ZooKeeper注册自己的信息,比如自己的主机名、端口、监听协议等数据。移除ZooKeeper之后,Broker的注册机制也要发生变化:Broker需要向active controller发送心跳来进行注册。Controller收集心跳中包含的Broker数据构建整个Kafka集群信息,如下图所示:
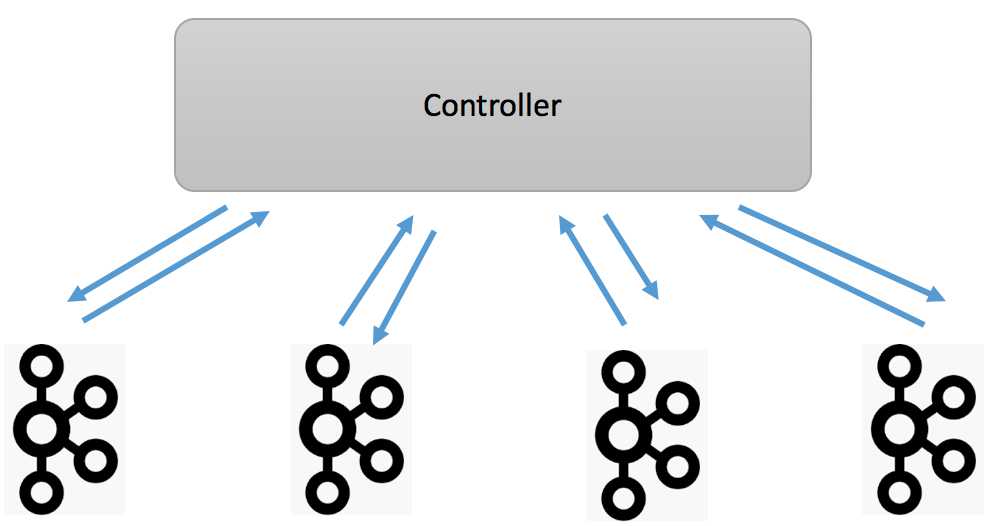
同时Controller也会对心跳进行响应,显式地告知Broker它们是否被允许加入集群——如果不允许,则可能需要被隔离(fenced)。当然controller自己也可以对自己进行隔离。我们针对前面提到的隔离场景讨论下KIP-500是怎么应对的。
Fencing
首先是普通Broker与集群完全隔离的场景,比如该Broker无法与controller和其他Broker进行通信,但它依然可以和客户端程序交互。此时,fencing机制就很简单了,直接让controller令其下线即可。这和现在依靠ZooKeeper会话机制维持Broker判活的机制是一模一样的,没有太大改进。
第二种情况是Broker间的通讯中断。此时消息无法在leader、follower间进行备份。但是对于元数据而言,我们不会看到数据不一致的情形,因为Broker依然可以和controller通讯,因此也不会有什么问题。
第三种情况是Broker与Controller的隔离。现有机制下这是个问题,但KIP-500之后,Controller仅仅将该Broker“踢出场”即可,不会造成元数据的不一致。
最后一种情况是Broker与ZooKeeper的隔离, 既然ZooKeeper要被移除了,自然这也不是问题了。
部署
终于聊到KIP-500之后的Kafka运维了。下表总结了KIP-500前后的部署情况对比:

很简单,现在任何时候部署和运维Kafka都要考虑对ZooKeeper的运维管理。在KIP-500之后我们只需要关心Kafka即可。
Controller quorum共享模式
如前所述,controller改成Raft quorum机制后,可能使用3或5台机器构成一个小的quorum。那么一个很自然的问题是,这些Broker机器还能否用作他用,是唯一用作controller quorum还是和其他Broker一样正常处理。社区对此也做了解释:两种都支持!
如果你的Kafka集群资源很紧张,你可以使用共享controller模式(Shared Controller Mode),即充当controller quorum的Broker机器也能处理普通的客户端请求;相反地,如果你的Kafka资源很充足,专属controller模式(Separate Controller Mode)可能是更适合的,即在controller quorum中的Broker机器排它地用作Controller的选举之用,不再对客户端提供读写服务。这样可以实现更好的资源隔离,适用于大集群。
Roadmap
最后说一下KIP-500的计划。社区计划分三步走:

第一步是移除客户端对ZooKeeper的依赖——这一步基本上已经完成了,除了目前AdminClient还有少量的API依赖ZooKeeper之外,其他客户端应该说都不需要访问ZooKeeper了;第二步是移除Broker端的ZooKeeper依赖:这主要包括移除Broker端需要访问ZooKeeper的代码,以及增加新的Broker端API,如前面所说的AlterISR等,最后是将对ZooKeeper的访问全部集中在controller端;最后一步就是实现controller quorum,实现Raft-based的quorum负责controller的选举。
至于Kafka升级,如果从现有的Kafka直接升级到KIP-500之后的Kafka会比较困难,因此社区打算引入一个名为Bridge Release的中间过渡版本,如下图所示:

这个Bridge版本的特点在于所有对ZooKeeper的访问都集中到了controller端,Broker访问ZooKeeper的其他代码都被移除了。
总结
KIP-500应该说是最近几年社区提出的最重磅的KIP改进了。它几乎是颠覆了Kafka已有的使用模式,摒弃了之前重度依赖的Apache ZooKeeper。就我个人而言,我是很期待这个KIP,后续有最新消息我也会在一并同步出来。让我们静观其变吧~~~
以上是关于Kafka needs no Keeper(关于KIP-500的讨论)的主要内容,如果未能解决你的问题,请参考以下文章