数据库中的十种数据类型都是啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库中的十种数据类型都是啥相关的知识,希望对你有一定的参考价值。
Character 数据类型Character 数据类型用来存储字母数字型数据。当你在oracle 中定义一个character 数据时,通常需要制定字段的长度,它是该字段的最大长度。ORACLE提供以下几种character 数据类型:
CHAR() CHAR数据类型是一种有固定长度和最大长度的字符串。存储在数据类型为CHAR字段中的数据将以空格的形式补到最大长度。长度定义在1——2000字节之间。
当你创建一个CHAR型字段,数据库将保证在这个字段中的所有数据是定义长度,如果某个数据比定义长度短,那么将用空格在数据的右边补到定义长度。如果长度大于定义长度将会触发错误信息。
VARCHAR() varchar型数据是varchar2型数据的快照。
VARCHAR2() varchar2数据类型是一种可变长度的、有最大长度的字母数字型数据。Varchar2类型的字段长度可以达到4000字节,Varchar2类型的变量长度可以达到32676字节。
一个空的varchar2(2000)字段和一个空的varchar2(2)字段所占用的空间是一样的。
NCHAR() 和 NVARCHAR2() NCHAR() 和 NVARCHAR2()数据类型分别与CHAR() 和 VARCHAR2()类型是相同的,只不过它们用来存储NLS(National Language Support)数据。
LONG LONG 数据类型是一个遗留下来的而且在将来不会被支持的数据类型。它将被LOB(Large Object)数据类型所代替。
比较规则 Varchar2和char数据类型根据尾部的空格有不同的比较规则。对Char型数据,尾部的空格将被忽略掉,对于Varchar2型数据尾部带空格的数据排序比没有空格的要大些。比如:
Char 型数据: ‘YO’=‘YO ’
Varchar2型数据: ‘YO’<’YO ’
Numberic 数据类型
Numberic 数据类型用来存储负的和正的整数、分数和浮点型数据,范围在-1*10-103 和9.999…99*10125之间,有38位的精确度。标识一个数据超出这个范围时就会出错。
Number(
,) Number数据类型存储一个有p位精确度的s位等级的数据。
DATE 数据类型
DATE 数据类型用来存储日期和时间格式的数据。这种格式可以转换为其他格式的数据去浏览,而且它有专门的函数和属性用来控制和计算。以下的几种信息都包含在DATE数据类型中:
Century
Year
Month
Day
Hour
Minute
Second
LOB 数据类型
LOB(Large Object) 数据类型存储非结构化数据,比如二进制文件,图形文件,或其他外部文件。LOB 可以存储到4G字节大小。数据可以存储到数据库中也可以存储到外部数据文件中。LOB数据的控制通过DBMS_LOB 包实现。BLOB, NCLOB, 和CLOB 数据可以存储到不同的表空间中,BFILE存储在服务器上的外部文件中。LOB数据类型有以下几种:
BLOB: 二进制数据
CLOB: 字符型数据
BFILE: 二进制文件
其他数据类型
ROWID ROWID 数据类型是ORACLE数据表中的一个伪列,它是数据表中每行数据内在的唯一的标识。 参考技术A 字符串
sring
数字可以是string
也可以是int
看你怎么用了
加双引号就是字符串
数据结构——常见的十种排序算法
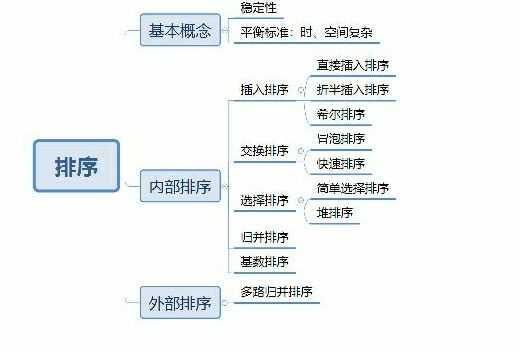
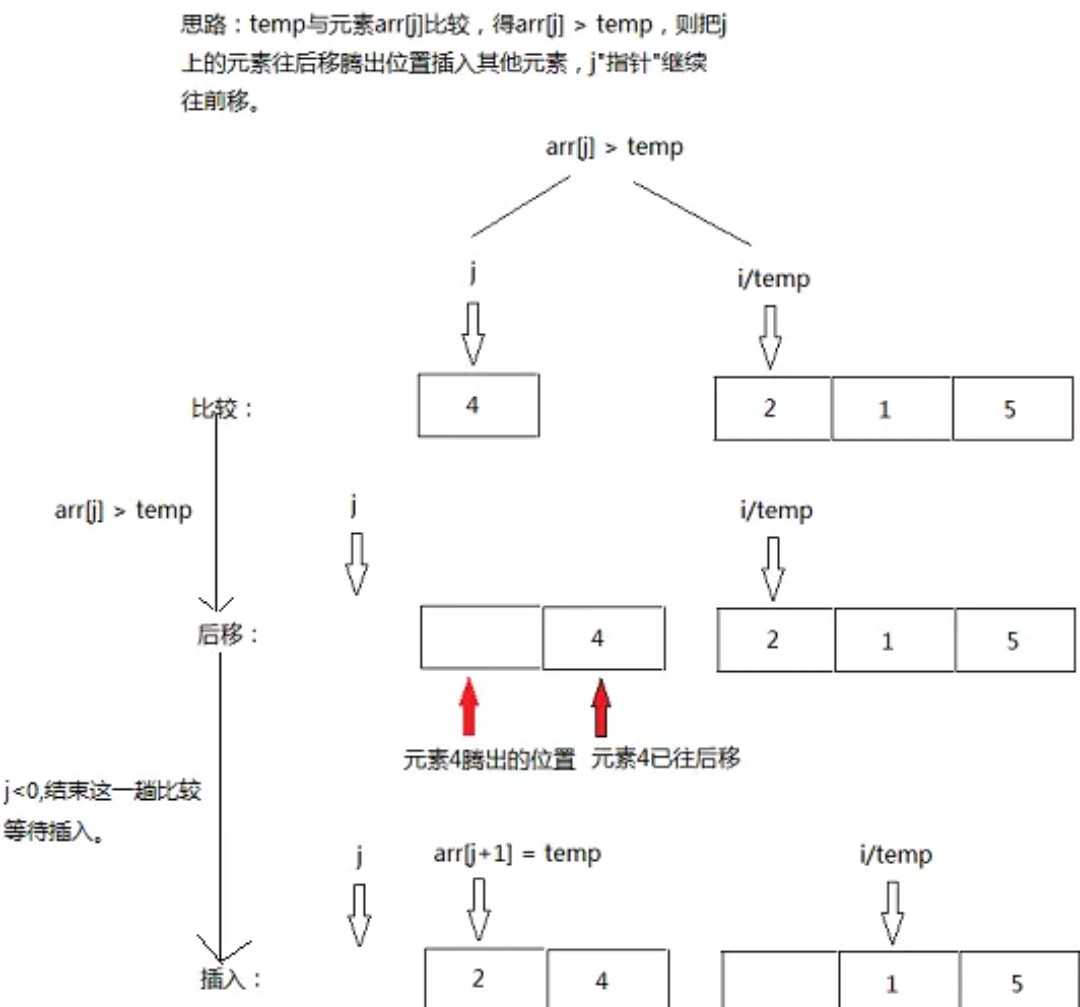
3.插入排序伪代码
1 void InsertSort (ElemType A[], int n) 2 { 3 int i,j; 4 for(i=2;i<=n;i++) 5 if(A[i].key<A[i-1].key) 6 { 7 A[0]=A[i]; 8 for(j=i-1;A[0].key<A[j].key;--j) 9 A[j+i]=A[j]; 10 A[j+i]=A[0]; 11 } 12 }
4.稳定性
由于每次插入元素时总是从后往前先比较在移动,所以不会出现相同元素相对位置,发生变化的情况即直接插入排序是一个稳定的排序方法
5.时间复杂度:O(n2)
?希尔排序(缩小增量排序)
1.算法提出:
2.算法思想:
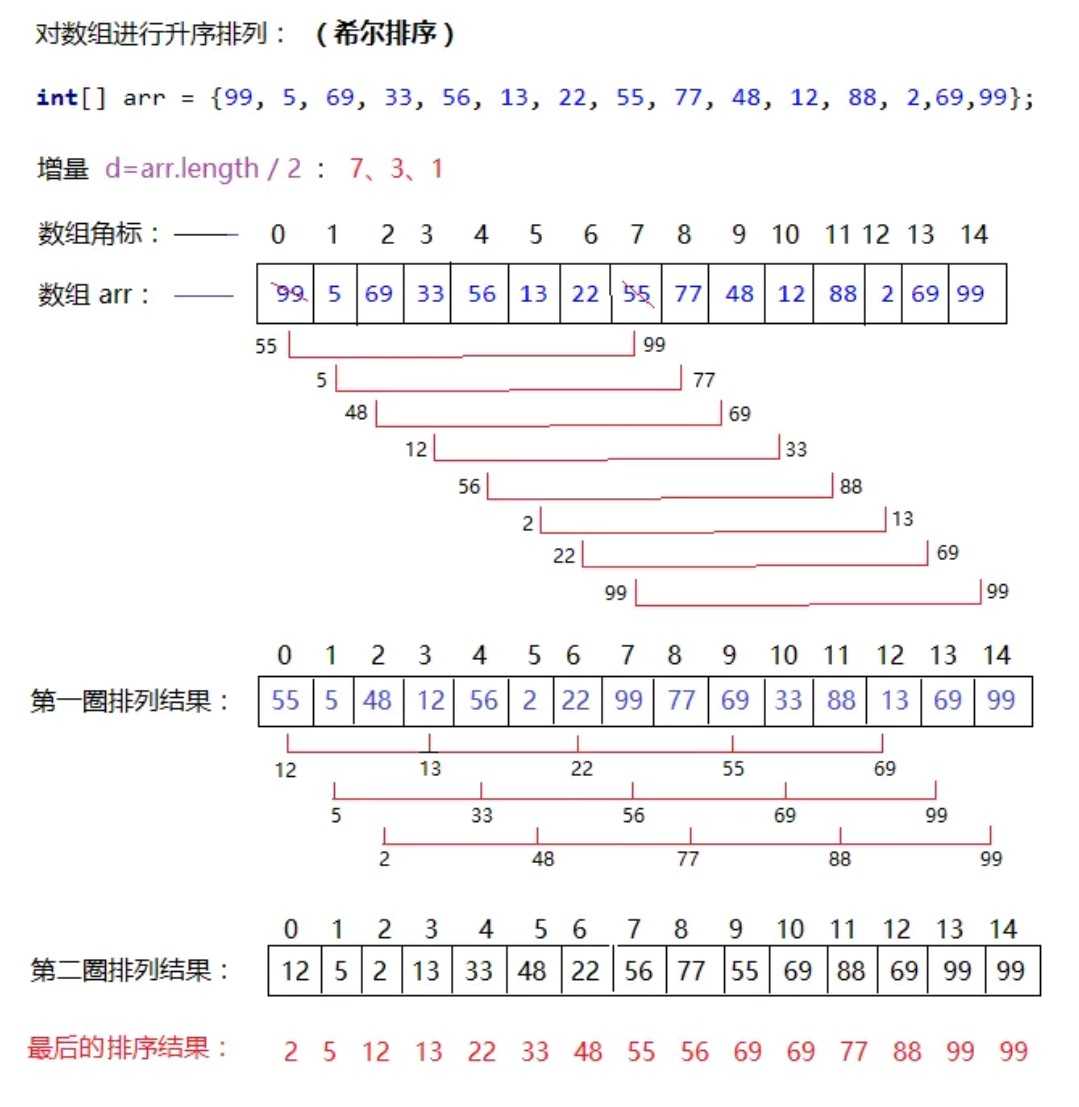
补充:操作原理时间复杂度与选取的增量序列有关且所取增量序列的函数介于O(N*logN)和O(n2)之间增量序列有很多种取法,但是使增量序列中的值没有除1之外的公因子,并且增量序列中最后一个值必须为1。
4.插入排序伪代码
1 void ShellSort (ElemType A[],int n){ 2 //对顺序表作希尔插入排序,基本算法和直接插入排序相比,做了以下修改: 3 //1.前后记录位置的增量是dk,不是1 4 //2.r[0]只是暂时存储单元,不是哨兵,当j<=0时,插入位置已到 5 for(dk=n/2;dk>=1,dk=dk/2) //步长变化 6 for(i=dk+1;i<=n;++i) 7 if(A[i].key<A[i-dk].key){ //需将A[i]插入有序增量子表 8 A[0]=A[i]; 9 for(j=i-dk;j>0&&A[0].key<A[j].key;j-=dk) 10 A[j+dk]=A[j]; //记录后移,查找插入位置 11 A[j+dk]=A[0]; //插入 12 }//if 13 }
5.稳定性
当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序,因此,希尔排序是一种不稳定的排序方法。例如,表L=[3,2,2].经过一趟排序后,
L=[2,2,3],最终排序序列也是L=[2,2,3],显然2与2的相对次序已经发生了变化。
6.时间复杂度:O(N*logN)
?选择排序
1.算法思想
Step1:将待排序数组分为有序和无序两组(初始情况下有序组为空)
Step2:从左向右扫描无序组,找出最小的元素,将其放置在无序组的第一个位置。至此有序组++,无序组--;
Step3:重复Step2,直至无序组只剩下一个元素。
2.算法实现
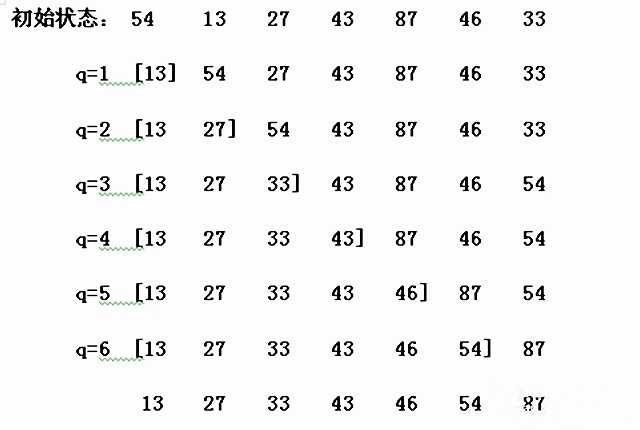
3.插入排序伪代码
1 void ShellSort (ElemType A[],int n){ 2 //对表A作简单的选择排序,A[]从0开始放元素 3 for(i=0;i<=n-1;i++){ //一共进行n-1趟 4 min=i; //记录最小元素位置 5 for(j=i+1;j<n;j++) //在A[i...n-1]中选择最小的元素 6 if(A[j]<A[min]) 7 min=j; //更新最小元素位置 8 if(min!=i) swap(A[i],A[min]); //在第n个元素交换 9 10 } 11 }
4.时间复杂度: O(n2)
5.稳定性:
选择排序的时间复杂度为O(n2),由于每次选择仅考虑某一位置上的数据情况,可能会破坏之前数据的相对位置,因此它是一种不稳定的排序方法。 例如:序列[9,9,1]第一次就将第一个[9]与[1]交换,导致第一个9挪动到第二个9后面。
补充:简单选择排序的比较次数与序列的初始排序无关。假设待排序的序列有 n个元素,选择排序的赋值操作介于0和3(n - 1) 次之间; 则比较次数 永远都是n (n- 1) / 2; 而移动次数(即:交换操作)与序列的初始排序有关,介于 0 和 (n - 1) 次之间。当序列正序时,移动次数最少,为 0。当序列反序时,移动次数最多,为n - 1 次;逆序交换n/2次。选择排序的移动次数比冒泡排序少多了,由于交换所需CPU时间比 比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
后续未完...
以上是关于数据库中的十种数据类型都是啥的主要内容,如果未能解决你的问题,请参考以下文章