25.Spark下载源码和安装和使用
Posted braveym
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了25.Spark下载源码和安装和使用相关的知识,希望对你有一定的参考价值。
安装scala
上传安装包

解压

配置scala相关的环境变量
export SCALA_HOME=/opt/modules/scala-2.11.4
export PATH=$PATH:$SCALA_HOME/bin
验证scala安装是否成功

把scala分发给node2 node3 node4
scp -r scala-2.11.4/ hadoop@node2:/opt/modules/ scp -r scala-2.11.4/ hadoop@node3:/opt/modules/ scp -r scala-2.11.4/ hadoop@node4:/opt/modules/
分别给node2 node3 node4配置scala的环境变量,并使其生效
#scala export SCALA_HOME=/opt/modules/scala-2.11.4 export PATH=$PATH:$SCALA_HOME/bin



spark安装包下载地址:https://archive.apache.org/dist/spark/spark-1.5.1/

上传安装包导集群

解压安装包

配置spark的环境变量

#spark export SPARK_HOME=/opt/modules/spark-1.5.1-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
使环境变量生效

修改spark配置文件

修改spark-env.sh文件
vim spark-env.sh文件
添加以下语句
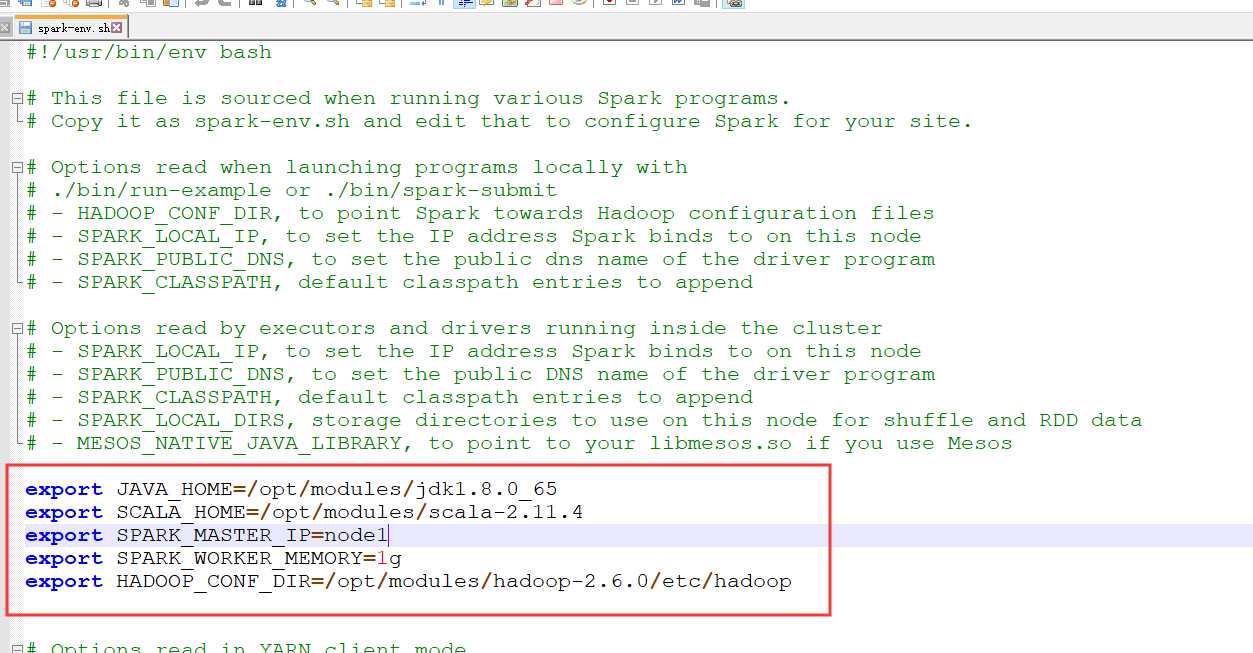
export JAVA_HOME=/opt/modules/jdk1.8.0_65 export SCALA_HOME=/opt/modules/scala-2.11.4 export SPARK_MASTER_IP=node1 export SPARK_WORKER_MEMORY=1g export HADOOP_CONF_DIR=/opt/modules/hadoop-2.6.0/etc/hadoop
修改slaves文件
vim slaves

将spark安装包分发给node2 node3 node4
scp -r spark-1.5.1-bin-hadoop2.6/ hadoop@node2:/opt/modules/ scp -r spark-1.5.1-bin-hadoop2.6/ hadoop@node3:/opt/modules/ scp -r spark-1.5.1-bin-hadoop2.6/ hadoop@node4:/opt/modules/
再给node2 node3 node4配置spark的环境变量
#spark export SPARK_HOME=/opt/modules/spark-1.5.1-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
在spark目录下的sbin目录执行./start-all.sh
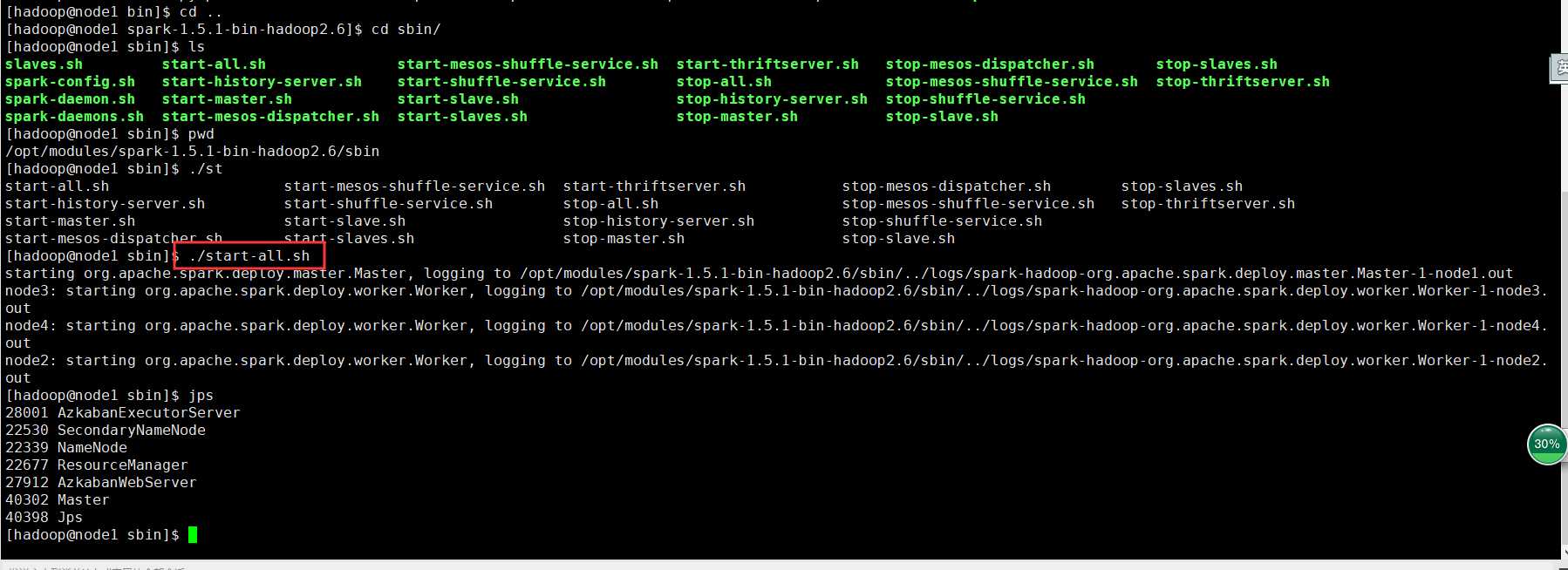
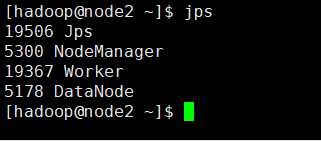
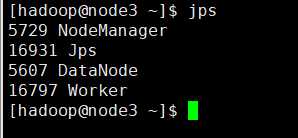
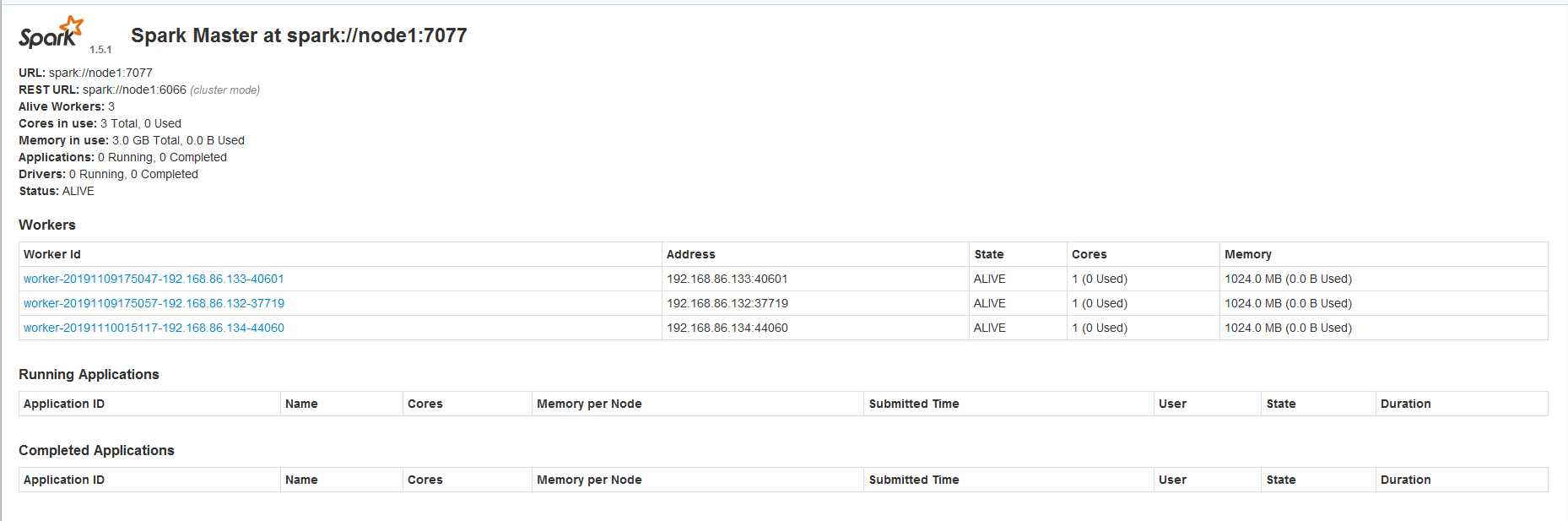
在浏览器打开地址http://node1:8080/
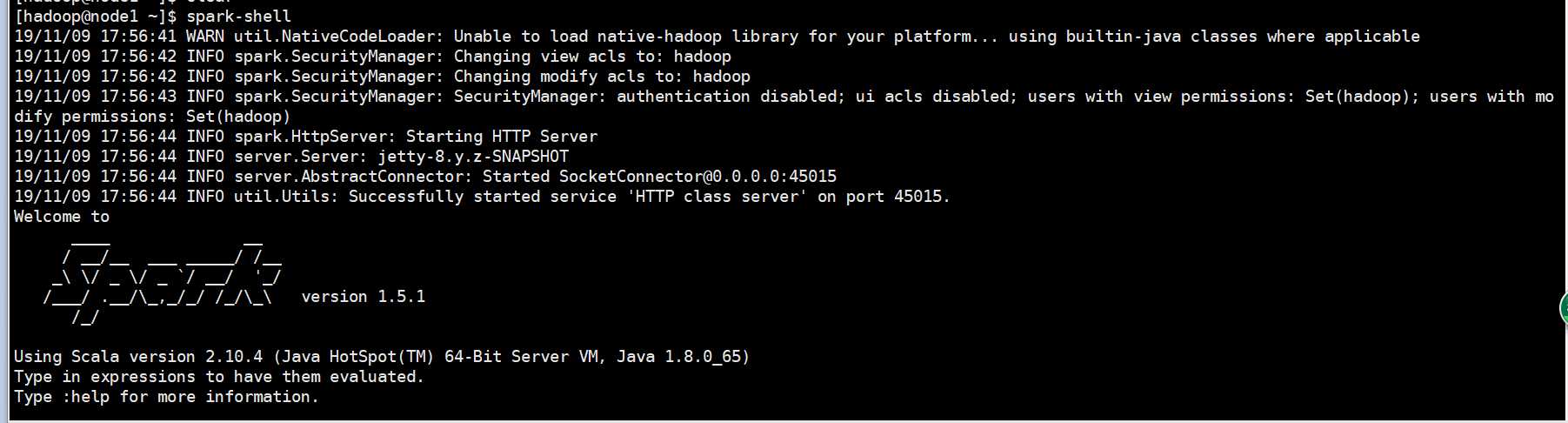
启动spark-shell
启动成功!!!!
以上是关于25.Spark下载源码和安装和使用的主要内容,如果未能解决你的问题,请参考以下文章