Python实现文本过滤去重
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实现文本过滤去重相关的知识,希望对你有一定的参考价值。
参考技术A具体的公式就不贴出来了,外面一大堆,主要记录一下Python的实现方式
布隆过滤器详解(BloomFilter)以及其实现介绍
一、 三种去重方式
-
1.HashSet
使用java中的HashSet不能重复的特点去重。优点是容易理解。使用方便。
缺点:占用内存大,性能较低。 -
2.Redis去重
使用Redis的set进行去重。优点是速度快(Redis本身速度就很快),而且去重不会占用爬虫服务器的资源,可以处理更大数据量的数据爬取。
缺点:需要准备Redis服务器,增加开发和使用成本。 -
3.布隆过滤器(BloomFilter)
使用布隆过滤器也可以实现去重。优点是占用的内存要比使用HashSet要小的多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会判定重复,但是重复数据一定会判定重复。
二、布隆过滤器介绍
布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种
space efficient的概率型数据结构,用于判断一个元素是否在集合中。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的1/8或1/4的空间复杂度就能完成同样的问题。布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,误报率越大,但是漏报是不可能的。
原理:
布隆过滤器需要的是一个位数组(和位图类似)和K个映射函数(和Hash表类似),在初始状态时,对于长度为m的位数组array,它的所有位被置0。
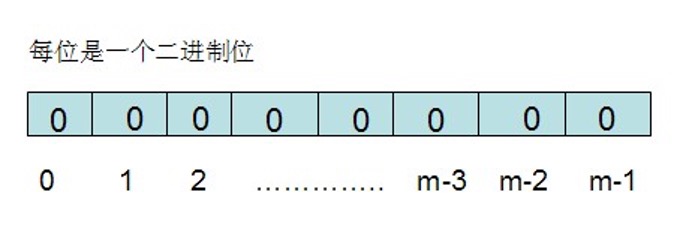
对于有n个元素的集合S=S1,S2…Sn,通过k个映射函数f1,f2,…fk,将集合S中的每个元素Sj(1<=j<=n)映射为K个值g1,g2…gk,然后再将位数组array中相对应的array[g1],array[g2]…array[gk]置为1:
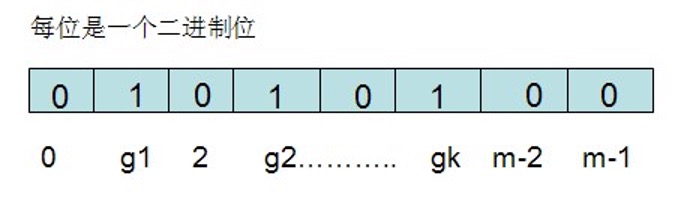
如果要查找某个元素item是否在S中,则通过映射函数f1,f2,…fk得到k个值g1,g2…gk,然后再判断array[g1],array[g2]…array[gk]是否都为1,若全为1,则item在S中,否则item不在S中。
布隆过滤器会造成一定的误判,因为集合中的若干个元素通过映射之后得到的数值恰巧包括g1,g2,…gk,在这种情况下可能会造成误判,但是概率很小。
三、布隆过滤器实现
//布隆过滤器
public class BloomFilter
/* BitSet初始分配2^24个bit */
private static final int DEFAULT_SIZE = 1 << 24;
/* 不同哈希函数的种子,一般应取质数 */
private static final int[] seeds = new int[] 5, 7, 11, 13, 31, 37 ;
private BitSet bits = new BitSet(DEFAULT_SIZE);
/* 哈希函数对象 */
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter()
for (int i = 0; i < seeds.length; i++)
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
// 将url标记到bits中
public void add(String str)
for (SimpleHash f : func)
bits.set(f.hash(str), true);
// 判断是否已经被bits标记
public boolean contains(String str)
if (StringUtils.isBlank(str))
return false;
boolean ret = true;
for (SimpleHash f : func)
ret = ret && bits.get(f.hash(str));
return ret;
/* 哈希函数类 */
public static class SimpleHash
private int cap;
private int seed;
public SimpleHash(int cap, int seed)
this.cap = cap;
this.seed = seed;
// hash函数,采用简单的加权和hash
public int hash(String value)
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++)
result = seed * result + value.charAt(i);
return (cap - 1) & result;
以上是关于Python实现文本过滤去重的主要内容,如果未能解决你的问题,请参考以下文章