触发器与存储过程
Posted dfrank
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了触发器与存储过程相关的知识,希望对你有一定的参考价值。
https://blog.csdn.net/jesse621/article/details/9452049
触发器,简洁,存储过程,明了
使用
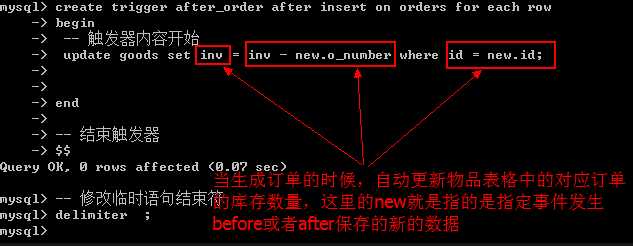
触发器的作用:
触发器的主要作用是其能够实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性。它能够对数据库中的相关表进行级联修改,强制比CHECK约束更复杂的数据完整性,并自定义操作消息,维护非规范化数据以及比较数据修改前后的状态。与CHECK约束不同,触发器可以引用其它表中的列。在下列情况下使用触发器实现复杂的引用完整性;强制数据间的完整性。创建多行触发器,当插入,更新、删除多行数据时,必须编写一个处理多行数据的触发器。执行级联更新或级联删除这样的动作。级联修改数据库中所有相关表。撤销或者回滚违反引用完整性的操作,防止非法修改数据。
触发器与存储过程的区别:
触发器与存储过程的主要区别在于触发器的运行方式。存储过程必须有用户、应用程序或者触发器来显示的调用并执行,而触发器是当特定时间出现的时候,自动执行或者激活的,与连接用数据库中的用户、或者应用程序无关。当一行被插入、更新或者删除时触发器才执行,同时还取决于触发器是怎样创建的,当UPDATE发生时使用一个更新触发器,当INSERT发生时使用一个插入触发器,当DELETE发生时使用一个删除触发器。
关于数据库中存储过程和触发器的知识,这是很细节的技术,一般只要用了都会很快掌握其使用方法。经过这么多年,我一般在设计数据库的时候也都会或多或少的使用存储过程和触发器,原因很简单:良好的性能,业务也好实现。可是在做上次的项目的时候,由于业务很复杂,存储过程和触发器的数量均都达到上百之多,这是一件很恐怖的事情,尤其是在出了错调试维护的时候,就会想没有这些东西多好。下面我从经验角度梳理一下对存储过程和触发器的看法。
1、触发器是特殊的存储过程。
这句话在教科书中会经常出现,这就说明二者是有很大的联系的,我的一般理解就是触发器是一个隐藏的存储过程,因为它不需要参数,不需要显示调用,往往在你不知情的情况下已经做了很多操作。从这个角度来说,由于是隐藏的,无形中增加了系统的复杂性,非DBA人员理解起来数据库就会有困难,因为它不执行根本感觉不到它的存在。再有,涉及到复杂的逻辑的时候,触发器的嵌套是避免不了的,如果再涉及几个存储过程,再加上事务等等,很容易出现死锁现象,再调试的时候也会经常性的从一个触发器转到另外一个,级联关系的不断追溯,很容易使人头大。其实,从性能上,触发器并没有提升多少性能,只是从代码上来说,可能在coding的时候很容易实现业务,所以我的观点是:摒弃触发器!触发器的功能基本都可以用存储过程来实现。
2、存储过程优点很多,可以经常使用
- 可以封装数据逻辑和业务规则,以便用户可以仅通过开发人员和数据库管理员打算使用的方式访问数据和对象。
- 验证所有用户输入的参数化存储过程可用于阻止 SQL 注入攻击。 如果使用动态 SQL,请确保将命令参数化,并绝对不能将参数值直接包括在查询字符串中。
- 可禁止即席查询和数据修改。 这样将阻止用户恶意或无意中损坏数据或执行查询,以避免降低服务器或网络的性能。
- 可以在过程代码中处理错误,而无需将错误直接传递给客户端应用程序。 这样可防止返回错误消息,以避免其可能有助于探测攻击。 在服务器上记录错误并对其进行处理。
- 存储过程只能编写一次,可由很多应用程序访问。
- 客户端应用程序不需要知道有关基础数据结构的任何信息。 只要更改不影响参数列表或返回的数据类型,就可以更改存储过程代码,而无需在客户端应用程序中进行更改。
- 存储过程可通过将多个操作组合到一个过程调用中来减少网络通讯。
- 安全性好—可以访问执行存储过程而不必拥有直接操作基础表的权限
- 减少网络通信流—存储过程可以包含多条SQL语句,但只要用一条语句来执行该存储过程,从而减少了客户端应用程序对服务器的调用次数和长度
- 快速执行—存储过程在第一次执行时进行语法检查和编译,编译好的版本存储在高速缓存中,用于再次调用
- 保证一致性—如果用户只通过存储过程修改数据,则可以消除偶然修改带来的问题减少操作人员和编程人员的错误—由于传递信息少,因此执行复杂任务更容易,不易出现SQL错误
3、考虑移植性,存储过程的致命伤
如果一个系统过多的使用了存储过程,那系统的业务逻辑过于依赖数据库,这样就会给系统额外的增加一层数据库中的业务逻辑层,如果开发的时候用的sql server,后来发现数据量过大,需要提高性能移植到oracle或者mysql,这样就会很麻烦,相当于把存储过程重写一遍,这是不能忍受的。我们平时在做项目的时候,往往一个功能在客户端实现起来很费劲,在服务端很容易就可以实现,这样好多人就会选择在服务端做,却为以后留下隐患。在分析项目的需求的时候,一定要考虑性能问题,多久有可能会升级, 如果数据量很小,几十年用sql server都没问题,那就可以多用存储过程;但是数据量有可能会逐渐累积成千万条甚至更多,就不得不考虑系统的可移植性,这时候尽量不要用存储过程,全部代码控制。
4、存储过程的代码可复用性差。
面向对象的思维在存储过程这毫无用武之地,两个很相似的功能在也需要两个存储过程,因为他们是互相独立的,可以互相调用,但是不能继承等面向对象的操作,这也就增加了代码量。
综上:在一般的小系统(逻辑简单)中,存储过程和触发器可以多用,毕竟ms设计的,可以很大程度上提升性能;在复杂的系统中,建议不用触发器,少用存储过程。
以上是关于触发器与存储过程的主要内容,如果未能解决你的问题,请参考以下文章