在Hadoop集群中,任务分配到每个节点上的传统方法是啥,怎么实现随机分配,均衡分配........
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在Hadoop集群中,任务分配到每个节点上的传统方法是啥,怎么实现随机分配,均衡分配........相关的知识,希望对你有一定的参考价值。
默认方法是随机加均衡,几条策略,一般都会把任务分配给离存储节点之一最近的节点
如果某个节点运算效率过慢就会把这个运算给另一个空闲节点同时做,谁先做完用谁的
如果某段计算实在做不过去,说明程序有问题,会跳过出问题的步骤,做下一步 参考技术A 如果你不管他,他就会对比,谁的效率高空间剩余的多优先用谁,不过在空闲的时候你可以使用负载均衡来使他们平均一些 参考技术B 这个嘛,我也在学习中,有在学习hadoop的朋友多交流交流,暂时还不知道,看资料中。你看看编程的api文档,是用mapreduce写的job吗?看看有没有提供 参考技术C 都是随机分配的吧,具体方法不是很了解
Hadoop学习
什么是Hadoop?
hadoop是Apache 开源发布的分布式系统基础架构。它实现了分布式文件系统(hadoop Distributed File System,HDFS),分布式系统是运行在多个主机上的软件系统。HDFS有着高容错性的特点,能够保存多个副本,并可以将自动失败的任务重新分配。Hadoop可以部署在低廉通用的硬件平台上组成集群,提供热拔插的方式增加新的节点来向集群中扩展,将任务动态的分配到各节点中,并保证各节点的动态平衡,因此Hadoop具有低成本,高扩展性,高效性,高容错性的特点。
Hadoop的体系结构
hadoop的核心
HDFS和MapReduce是Hadoop的两大核心,Hadoop通过HDFS来实现对分布式存储的底层支持,达到高速并行读写与大容量的存储扩展,通过MapReduce来对分布式并行任务处理程序的支持,保证高速分析处理数据。HDFS又对MapReduce任务处理中提供了对文件操作和存储的支持。MapReduce在HDFS的基础上实现了任务的分发,跟踪,执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
Hadoop的子项目
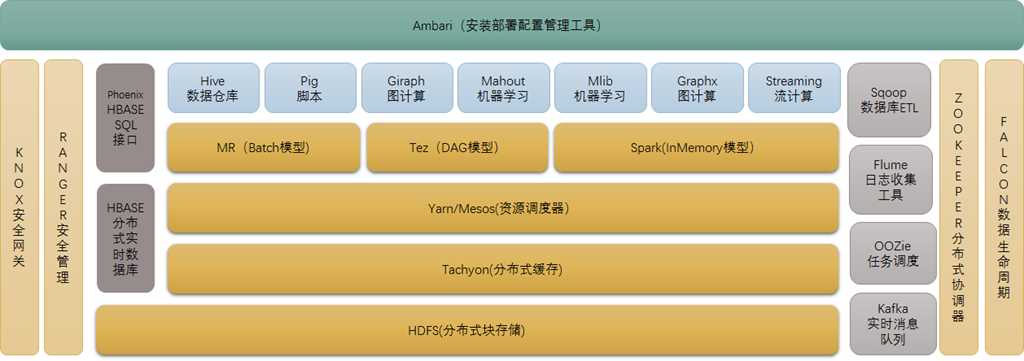
- HDFS:分布式文件系统,整个Hadoop的基石
- MapReduce/YARN:并行编程模型,YARN为二代的MapReduce。
- Hive:建立在Hadoop的数据仓库,提供类似SQL语言的功能去查询Hadoop中的数据。
- Pig:一个对大型数据集进行分析,评估的平台,主要作用类似数据库的存储过程。
- HBase:一个分布式,面向列的数据库,是一个适用非结构化数据存储的数据库。
- Zookeeper:一个分布式应用所设计的协调服务,是Hadoop和HBase的重要组件,为分布式应用提供一致性的软件,提供包括配置维护,域名服务,组服务等,减轻分布式应用所承担的协调任务。
- Sqoop:主要用于Hadoop与普通数据库,如MySQL间的数据传递。
- .......
Hadoop组件远不止这些,经过这么多年发展,更多的项目加入Hadoop生态圈,HBase,HDFS,MapReduce为Hadoop的三个重要组件,先习得这三个在深入Hadoop,对于开发来说这三个也是最基本的模块。
Hadoop版本
| Hadoop | 大版本 | 说明 |
| 第二代Hadoop2.0 | 2.x.x | 下一代Hadoop由0.23.x演化而来 |
| 0.23.x | 下一代Hadoop | |
| 第一代Hadoop1.0 | 1.0.x | 稳定版,由0.20.x演化而来 |
| 0.22.x | 非稳定版本 | |
| 0.21.x | 非稳定版本 | |
| 0.20.x | 经典版本,最后演化为1.0.x |
卒
以上是关于在Hadoop集群中,任务分配到每个节点上的传统方法是啥,怎么实现随机分配,均衡分配........的主要内容,如果未能解决你的问题,请参考以下文章