Cascade (Mask) RCNN 2019
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cascade (Mask) RCNN 2019相关的知识,希望对你有一定的参考价值。
参考技术A"close" false positives: 和正确的样本非常接近但是其实是不正确的bbox.
在以往的方法中,界定正负样本是通过卡IoU阈值来实现的。比如在Faster RCNN中的RPN,在选择正负样本时,采用如下的方法:
当卡IoU阈值为0.5时,产生的样本数量非常noisy(如下图(a)所示,很多非常小的box仅包含了背景,但是也被留下来当作了person类)
当逐渐增大阈值,bbox的质量会越来越好,但是也导致可用于训练的正样本急剧减少。
本文中定义了:
初始前提 :一个单独的detector只能在某个特定的“quality of detector”下达到optimal. (也就是一个detector只能对应一个最佳的IoU threshold)
下面作者用了三个实验来验证上面这个前提:
图(a) 是bbox regression的表现。三个设置了不同IoU阈值的regressor,分别在它们threshold附近的IoU表现得最好,比如: 的蓝色曲线,在横轴0.5左右的地方表现就比其他两条曲线高。 图(c) 也有相同的效果。这就表明了,一个在单个IoU阈值下训练好的detector,对于IoU阈值下的表现就不是最佳的了。
图(b) 中显示的peak也能说明类似的结论。总的来说,IoU阈值确定了分类的boundary——分类器在什么boundary下是表现最好的。
这些实验观察说明,单单去提高IoU阈值来产生质量更高的proposals以训练网络是不能一定得到更好的效果的, 图(c) 里面 那里,反而证明阈值越高效果还越差。这个结果有两个原因:
于是提出了Cascade RCNN这么一种multi-stage的方式:
The Cascade of RCNN stages is trained sequentially, using the output of one stage to train the next.
因为input proposals和GT的IoU,经过了regressor之后,output和GT的IoU分数一定会更好(不然你的regressor就是白瞎了不是)。这也就是说,对于卡了低IoU阈值的detector,它输出出来的bbox如果作为下一个“高IoU阈值detector”的输入proposals,那个这个proposals(hypotheses)的质量必然是更好的。
对于上述两个问题的解决:
每一个regressor 都在之前的regressor产生的bbox分布上调优,而不是在给的初始bbox上( )。这样一来,hypotheses是一层一层越来越优化的。
RPN最开始产生出来的那些hypotheses分布中,low quality的占了大部分。在 时候,只有2.9%的examples是正样本。这样就很难去训练一个高质量下的detector(之前提到了:low quality hypotheses只能训练low quality detector; high quality hypotheses只能训练high quality detector)。在Cascade RCNN中,用了cascade regression来作为一种 重采样 策略(resampling method)。因为上一层low quality的bbox经过了上一层的regressor之后精细化了,到了下一层就变成了high quality的bbox,即使下一层卡IoU阈值卡得高一点,这些bbox也不会被过滤掉。文中说这样可以让每一个stage的正样本数几乎保持一个常量。这样做相当于 改变 了bbox hypotheses的 分布 。
从 Fig3 (c) 可以看出 Iterative BBox 和本文的Cascade RCNN差不多,只是Iterative BBox在不同的stage都用了 同样的network head ,相当于在每个stage把同样的module重复使用。这样做的话其实没有解决之前说的 paradox of high-quality detection 。
而 Intergral Loss 中提出的结构( Fig3(d) ) 没有解决当IoU阈值卡高了之后正样本数量急剧减少的问题。
Mask R-CNN中,新加入的segmentation branch是和detection branch平行加入的。在Cascade的结构中,加入这样一个新的branch就有如下两个问题:
(1) 加在哪里? (2) 加多少?
文中给出了三个方案如上图 Fig 6 :(b) (c)两个方案主要是解决第一个问题,且只考虑加一个segmentation branch。
用来训练segmentation branch的instances是来自于detection branch的正样本。把segmentation head放到cascade的更后面可以得到更多的样本,但是由于分割是一个pixel-wise的操作,有很多重叠的instances其实也不是一件好事。
(d) 第三种方案在每个stage都加了一个分割头,这样最大化了sample的多样性。
在inference的时候所有的strategies都在最后的stage输出来的patches上面进行分割,不管训练的时候segmentation head是如何设置的。
fcn cascade rcnn
- FPN(Feature Pyramid Networks for Object Detection)
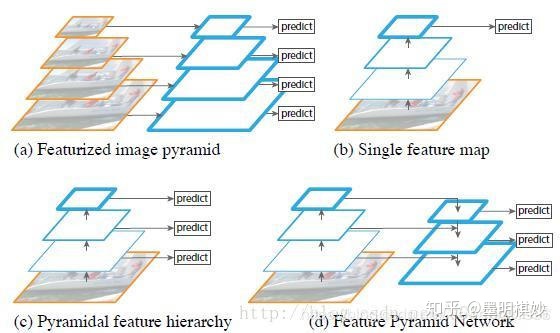
特征融合
目的是把低层次高分辨率的信息和高层次强语义的信息结合起来,提高检测性能和小目标识别。
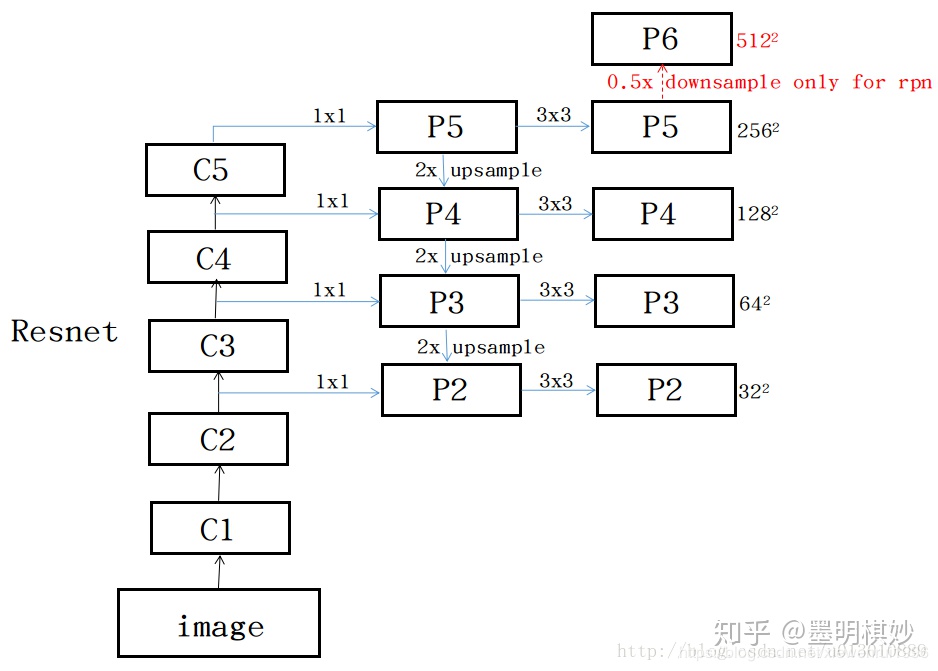
https://zhuanlan.zhihu.com/p/103263215
2.双线性插值 ROI Align
解决图像下采样的时候精度损失的问题。
https://www.cnblogs.com/yssongest/p/5303151.html
https://blog.csdn.net/qq_37577735/article/details/80041586
3. Cascade RCNN
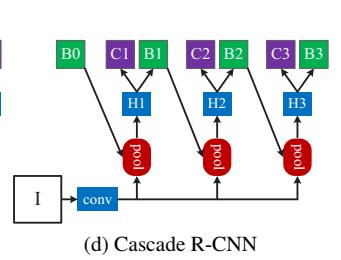
解决训练的时候使用iou阈值过滤proposals 但是推理的时候不适用iou过滤的影响
改用多个iou阈值,使得网络适应各种proposals。
https://zhuanlan.zhihu.com/p/42553957
https://blog.csdn.net/qq_39382877/article/details/97966011#Cascade%5C%20RCNN
以上是关于Cascade (Mask) RCNN 2019的主要内容,如果未能解决你的问题,请参考以下文章