grep命令
Posted sxfu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了grep命令相关的知识,希望对你有一定的参考价值。
首先介绍下grep命令:
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。它是linux中最常用的“文本处理工具之一”,与sed、awk合称为linux中的“三剑客”。
选项:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --revert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
示例:
为了方便,准备了一个测试文件test.txt,内容如下
如果我们想要搜索包含hello字符串的行,则可以使用如下命令:

上图中的命令表示使用grep命令,在test.txt文件中搜索包含“hello”字符串的行,并将包含hello字符串的行打印出来。
默认情况下grep是区分大小写的,如果要想不区分大小写把想找的内容搜索出来则可以加上 -i 的参数,如下所示:

因为是用来实验的,所以测试文件中所写的内容比较少,一般情况在平时工作中一个文件里的内容少则几十行,多则几百上千行,而我们想要确定我们想要搜索的内容在这个文件里第几行需要怎么办?
加上一个 -n 的参数就可以解决上述的问题,如下所示:

如图所示,利用-n 参数就可以把要检索的内容的行数显示出来。
如果我们只想知道有多少行包含我们检索的内容,而不在乎哪些行包含这些内容,我们可以使用如下命令,获取到符合条件的行数。

有的时候,我们需要反向查找,比如查找“不包含某个字符串的行”,这个时候“-v”选项就可以解决这个问题

上述表示查找出文本中不包含“test”的行。
某些场景下,我们需要同时从多个目标中匹配,什么意思呢?来,我们看下示例就知道了
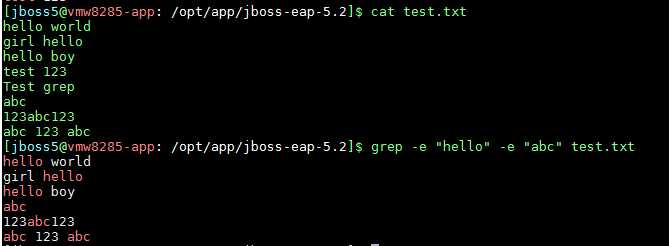
上例子我们同时检索了包 hello 和 abc字符串,包含这两个字符串中的每一行都被打印出来,没错,就像上面的图例一样,使用“-e”选项可以同时匹配多个目标,多个目标存在“或”关系,即匹配到其中的任意一个都算作匹配成功。
在写脚本时,你可能只是想要利用grep判断文本中是否存在某个字符串,你只关心有没有匹配到,而不关心匹配到的内容,你只关心有,或者没有,这时,我们可以使用grep的静默模式,示例如下。
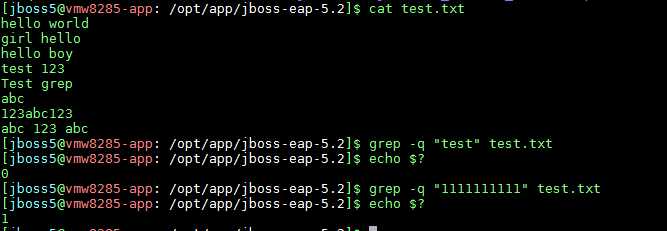
当使用"-q"选项时,表示grep使用静默模式,静默模式下grep不会输入任何信息,无论是否匹配到指定的字符串,都不会输出任何信息,所以,我们需要配合"echo $?"命令,查看命令的执行状态,如果返回值为0,证明上一条grep命令匹配到了指定的字符串,如果返回值为1,则证明上一条grep命令没有匹配到指定的字符串,就像上图示例中显示的那样,静默模式下,grep没有输出任何信息,当我们在test.txt文本中查找"test"字符串时,可以匹配到结果,当在文本中查找"1111111111"字符串的时候,没有匹配到结果,所以,我们只关心有没有匹配到指定字符时,可以使用"-q"选项,但是需要配合"echo $?"命令查看执行状态。
grep还有很多其它选项,我只是列举了常用的一些选项,其它选项可以自行练习。
其实,除了grep命令,其实还有egrep命令,还有fgrep命令(fast grep),它们有各自的特点。
grep:支持基本正则表达式
egrep:支持扩展正则表达式,相当于grep -E
fgrep:不支持正则表达式,只能匹配写死的字符串,但是速度奇快,效率高,fastgrep
【参考资料:http://www.zsythink.net/archives/1733】
以上是关于grep命令的主要内容,如果未能解决你的问题,请参考以下文章