如何利用matlab求相关系数?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用matlab求相关系数?相关的知识,希望对你有一定的参考价值。
已知未知参量a,b,c,d.
f(x)和g(x)都是由这4个参量构成的表达式。求f(x)和g(x)的相关系数。
利用matlab能求么?如果可以,请高手赐教啊,顺带给个例子让我看看。
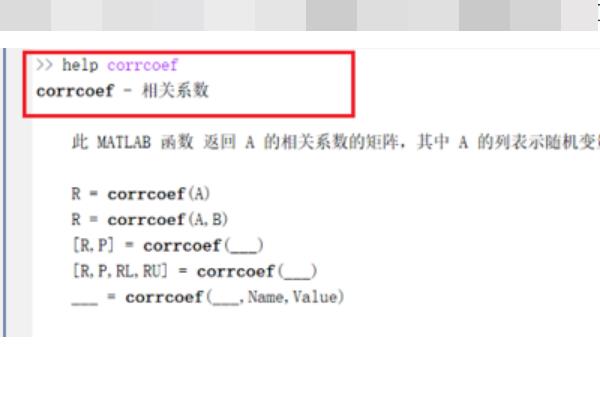
1、第一步我们首先需要知道matlab中求相关系数用到的是corrcoef函数,在命令行窗口中输入“help corrcoef”,可以看到corrcoef函数用法,
2、第二步在命令行窗口中输入a=[1 3 6 7 8 16],b=[2 4 7 9 15 19],创建两个矩阵,求两个矩阵的相关系数,

3、第三步输入corrcoef(a,b),按回车键,可以看到两个矩阵的相关系数是 0.9454 ,呈高度相关,

4、第四步输入corrcoef(a),可以求a矩阵的相关系数,如果a矩阵是个多维矩阵,可以通过corrcoef(a(:,1),a(:,2))求每一列的相关系数,

5、第五步按回车键之后,可以a矩阵自身的相关系数为1,这里需要注意的是相关系数0.00-±0.3是微相关,±0.30-±0.50是实相关,±0.50-±0.80是显著相关,±0.80-±1.00是高度相关,

min(min(corrcoef(x1, x2))) 就是x1,x2之间的相关系数。
比如
t = (1:0.1:100)';
w = 2*pi;
x1=sin(w*t)+randn(size(t));
x2=cos(w*t)+randn(size(t));
x3=sin(w*t)+randn(size(t));
x1_x2 = min(min(corrcoef(x1, x2)))
x1_x3 = min(min(corrcoef(x1, x3)))
2、用corrcoef函数
设a1,b1,c1,d1 ,a2,b2,c2,d2 分别为f(x)和g(x)的系数
x=[a1,b1,c1,d1];
y=[a2,b2,c2,d2];
z=corrcoef(x,y) 参考技术B 用corrcoef函数
设a1,b1,c1,d1 ,a2,b2,c2,d2 分别为f(x)和g(x)的系数
x=[a1,b1,c1,d1];
y=[a2,b2,c2,d2];
z=corrcoef(x,y)本回答被提问者和网友采纳
如何在 Matlab 中生成两个具有给定相关系数的 Weibull 随机向量?
【中文标题】如何在 Matlab 中生成两个具有给定相关系数的 Weibull 随机向量?【英文标题】:How can I generate two Weibull Random Vectors with a given correlation coefficient in Matlab? 【发布时间】:2021-10-24 17:38:25 【问题描述】:我需要创建两个包含 N 个样本的向量 X 和 Y。它们都是具有相同 λ,k 参数的 Weibull 分布,并且它们的相关系数 ρ 既不是 -1 也不是 1 也不是 0,而是一个表示偏相关的通用值。
如何创建它们?
【问题讨论】:
【参考方案1】:您有边际分布(Weibull 分布),并且您想从两个分量相关的二元分布中进行抽样。这可以通过copula 来完成。
这是一个基于双变量 Plackett copula 的 Octave 脚本。 (该脚本使用logit 函数,该函数在Octave 中包含在statistics 包中。我没有Matlab;希望您能处理脚本中的Octave-isms。)
脚本后显示的图表显示了计算结果。
Matlab 有一个assortment of functions related to copulas,它可能允许您简化此代码,或提供其他有趣的方法来生成示例。
1;
% Copyright 2021 Warren Weckesser
% License (per *** terms): CC BY-SA 4.0
% (See https://creativecommons.org/licenses/by-sa/4.0/)
function rho = spearman_rho_log(logtheta)
% Compute the Spearman coefficient rho from the log of the
% theta parameter of the bivariate Plackett copula.
%
% The formula for rho is from slide 66 of
% http://www.columbia.edu/~rf2283/Conference/1Fundamentals%20(1)Seagers.pdf:
% rho = (theta + 1)/(theta - 1) - 2*theta/(theta - 1)**2 * log(theta)
% If R = log(theta), this can be rewritten as
% coth(R/2) - R/(cosh(R) - 1)
%
% Note, however, that the formula for the Spearman correlation rho in
% the article "A compendium of copulas" at
% https://rivista-statistica.unibo.it/article/view/7202/7681
% does not include the term log(theta). (See Section 2.1 on the page
% labeled 283, which is the 5th page of the PDF document.)
rho = coth(logtheta/2) - logtheta/(cosh(logtheta) - 1);
endfunction;
function logtheta = est_logtheta(rho)
% This function gives a pretty good estimate of log(theta) for
% the given Spearman coefficient rho. That is, it approximates
% the inverse of spearman_rho_log(logtheta).
logtheta = logit((rho + 1)/2)/0.69;
endfunction;
function theta = bivariate_plackett_theta(spearman_rho)
% Compute the inverse of the function spearman_rho_log,
%
% Note that theta is returned, not log(theta).
logtheta = fzero(@(t) spearman_rho_log(t) - spearman_rho, ...
est_logtheta(spearman_rho), optimset('TolX', 1e-10));
theta = exp(logtheta);
endfunction
function [u, v] = bivariate_plackett_sample(theta, m)
% Generate m samples from the bivariate Plackett copula.
% theta is the parameter of the Plackett copula.
%
% The return arrays u and v each hold m samples from the standard
% uniform distribution. The samples are not independent. The
% expected Spearman correlation of the samples can be computed with
% the function spearman_rho_log(log(theta)).
%
% The calculations are based on the information in Chapter 6 of the text
% *Copulas and their Applications in Water Resources Engineering*
% (Cambridge University Press).
u = unifrnd(0, 1, [1, m]);
w2 = unifrnd(0, 1, [1, m]);
S = w2.*(1 - w2);
d = sqrt(theta.*(theta + 4.*S.*u.*(1 - u).*(1 - theta).^2));
c = 2*S.*(u.*theta.^2 + 1 - u) + theta.*(1 - 2*S);
b = theta + S.*(theta - 1).^2;
v = (c - (1 - 2*w2).*d)./(2*b);
endfunction
% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
% Main calculation
% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
% rho is the desired Spearman correlation.
rho = -0.75;
% m is the number of samples to generate.
m = 2000;
% theta is the Plackett copula parameter.
theta = bivariate_plackett_theta(rho);
% Generate the correlated uniform samples.
[u, v] = bivariate_plackett_sample(theta, m);
% At this point, u and v hold samples from the uniform distribution.
% u and v are not independent; the Spearman rank correlation of u and v
% should be approximately rho.
% Now use wblinv to convert u and v to samples from the Weibull distribution
% by using the inverse transform method (i.e. pass the uniform samples
% through the Weibull quantile function wblinv).
% This changes the Pearson correlation, but not the Spearman correlation.
% Weibull parameters
k = 1.6;
scale = 6.5;
wbl1 = wblinv(u, scale, k);
wbl2 = wblinv(v, scale, k);
% wbl1 and wbl2 are the correlated Weibull samples.
printf("Spearman correlation: %f\n", spearman(wbl1, wbl2))
printf("Pearson correlation: %f\n", corr(wbl1, wbl2))
% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
% Plots
% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
% Scatter plot:
figure(1)
plot(wbl1, wbl2, '.')
axis('equal')
grid on
% Marginal histograms:
figure(2)
wbl = [wbl1; wbl2];
maxw = 1.02*max(max(wbl));
nbins = 40;
for p = 1:2
subplot(2, 1, p)
w = wbl(p, :);
[nn, centers] = hist(w, nbins);
delta = centers(2) - centers(1);
hist(w, nbins, "facecolor", [1.0 1.0 0.7]);
hold on
plot(centers, delta*wblpdf(centers, scale, k)*m, 'k.')
grid on
xlim([0, maxw])
if p == 1
title("Marginal histograms")
endif
endfor
终端输出:
Spearman correlation: -0.746778
Pearson correlation: -0.654956
散点图:
边际直方图(Weibull 分布,尺度为 6.5,形状参数为 1.6):
【讨论】:
【参考方案2】:让我提出一些简单的想法。您有两个相同的分布,相同的 μ 和相同的 σ 可以从 Weibull λ,k 参数得出。
ρ = E[(X-μ)(Y-μ)]/σ2
一般来说,它是 X 和 Y 之间线性度的度量。
所以让我们将 N 个样本分成 M 和 (N-M)。对于前 M 个样本,您对 X 和 Y 都使用 Weibull(λ,k) 的相同采样向量。最后 (N-M) 个样本独立于 Weibull(λ,k) 获取。所以 2D 图片看起来像这样 - 前 M 个点的完美线性相关性,然后是独立点云。
M越大,采样的相关性越多,ρ接近1。反之亦然——ρ接近1,那么你必须使M大。唯一的问题是弄清楚 M(ρ) 依赖关系(暂时不知道,但会考虑一下)。
上面我们介绍了非负 ρ 的情况。如果 ρ 为负数,则仅具有反线性依赖关系。
M(ρ) 依赖应该是单调的,也可能是线性函数,类似于
M = int(ρ*N)
但我目前没有证据
简单代码示例(未经测试!)
a=3;
b=4;
N=1000;
M=100;
c = wblrnd(a,b, M, 1);
xx = wblrnd(a,b, N-M, 1);
yy = wblrnd(a,b, N-M, 1);
X = cat(1, c, xx);
Y = cat(1, c, yy);
【讨论】:
非常感谢,听起来很棒。只是一个问题:一旦我生成了 X 和 Y 的元素,我是否必须混合它们?如果 X 和 Y 在 M 个样本中具有完全相同的初始部分,这不是太特殊了吗? @Kinka-Byo 但是你需要两个样本的一部分是线性的,这就是 rho 的全部意义所在。我会建议简单的测试。将其写为返回两个相关数组 X 和 Y 的函数。假设 N=10000。然后将 st M 设为 500,并调用此函数并计算 X 和 Y 之间的 rho。重复此操作 1000 次,对于给定的 M 计算平均 rho,E[rho]。然后将 M 设置为 1000 并重复。 M=1500 并重复。并绘制 E[rho] 作为 y 轴与 M/N (0.05, 0.1, 0.15, ...) 作为 x 轴的图。您会很快看到是否存在线性依赖关系以上是关于如何利用matlab求相关系数?的主要内容,如果未能解决你的问题,请参考以下文章