Apache Atlas 的初始密码及账户管理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Atlas 的初始密码及账户管理相关的知识,希望对你有一定的参考价值。
参考技术A Apache Atlas 在初始安装后,启动时需要进行登录,可以使用账号admin/admin进行登录,在apache 的文档中并没有缺省账号的说明。
另外关于账号的管理,在 Authentication 中有说明,账号的信息存储在文件 /conf/users-credentials.properties 中,其格式是:
注: 其中的Password 通过如下方式产生sha256sum 摘要信息
当然这是在使用 FILE 作为认证方式时,该方式是通过在 atlas-application.properties 中如下设置的。
还好,这是缺省的设置,你可以只关心如何设置 /conf/users-credentials.properties 的账号信息。
大数据治理系统框架Apache Atlas实践
大数据元数据和数据管理框架 Apache Atlas实践今天技术小伙伴占卫同学分享了Apache Atlas元数据管理实践,被atlas的强大的血缘关系管理能力震撼,以下为本次分享内容:
•Apache Atlas简介 •Apache Atlas架构 •Titan图数据库介绍 •ApachAtlas配置 •Apache Atlas案例 •总结Apache Atlas简介
•面对海量且持续增加的各式各样的数据对象,你是否有信心知道哪些数据从哪里来以及它如何随时间而变化?采用Hadoop必须考虑数据管理的实际情况,元数据与数据治理成为企业级数据湖的重要部分 •为寻求数据治理的开源解决方案,Hortonworks公司联合其他厂商与用户于2015年发起数据治理倡议,包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理等方面。Apache Atlas 项目就是这个倡议的结果,社区伙伴持续的为该项目提供新的功能和特性。该项目用于管理共享元数据、数据分级、审计、安全性以及数据保护等方面,努力与Apache Ranger整合,用于数据权限控制策略。
Atlas主要功能 •数据分类
定义、注释和自动捕获数据集和底层之间的关系元素包括源、目标和派生过程
•安全审计数据访问的日志审计
•搜索和血缘关系元数据信息及数据之间的血缘
•安全与策略引擎 结合ApacheRanger来设置数据的访问权限Atlas架构
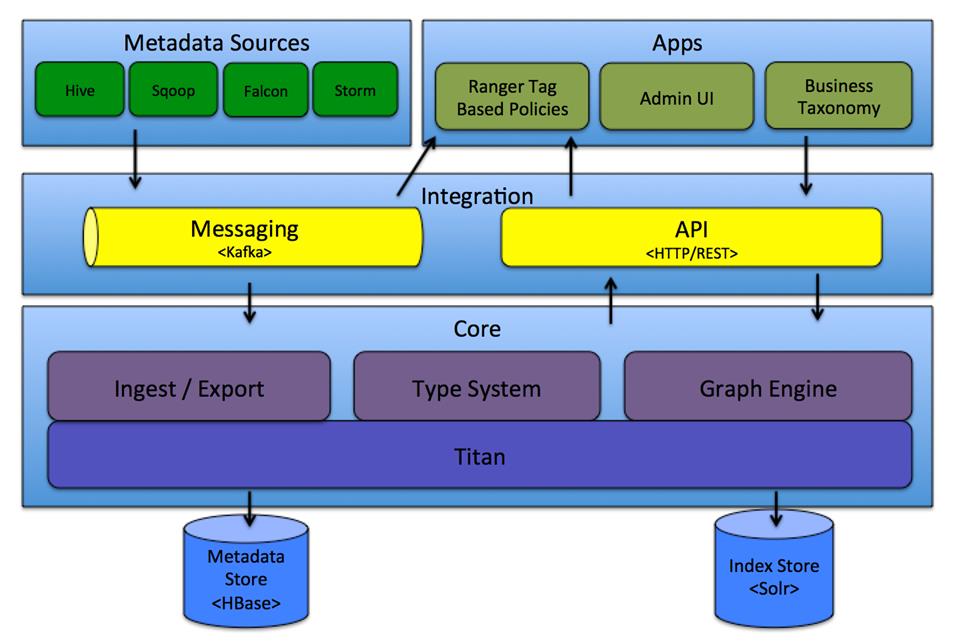
Atlas Core
• Type System : Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 “ 类型 ” 的定义组成 。 “ 类型 ” (类)的 实例被称为 “ 实体 ” 表示被管理的实际元数据对象。类型系统是一个组件,允许用户定义和管理类型和实体。由 Atlas 管理的所有元数据对象(例如 Hive 表)都使用类型进行建模,并表示为 实体 ( 类对象,一条数据 ) 。 • Ingest / Export : Ingest 组件允许将元数据添加到 Atlas 。类似地, Export 组件暴露由 Atlas 检测到的元数据更改,以作为事件引发,消费者可以使用这些更改事件来实时响应元数据更改。 • Graph Engine :在内部, Atlas 通过使用图形模型管理元数据对象。以实现元数据对象之间的巨大灵活性和丰富的关系。图形引擎是负责在类型系统的类型和实体之间进行转换的组件,以及基础图形模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便有效地搜索它们
如何使用Atlas管理
用户可以使用两种方法管理 Atlas中的元数据
•API:Atlas 的所有功能通过REST API 提供给最终用户,允许创建,更新和删除类型和实体。它也是查询和发现通过Atlas 管理的类型和实体的主要方法。https://cwiki.apache.org/confluence/display/ATLAS/Atlas+REST+API
• Messaging :除了 API 之外,用户还可以选择使用基于 Kafka 的消息接口与 Atlas 集成。这对于将元数据对象传输到 Atlas 以及从 Atlas 使用可以构建应用程序的元数据更改事件都非常有用。如果希望使用与 Atlas 更松散耦合的集成,这可以允许更好的可扩展性,可靠性等,消息传递接口是特别有用的。 Atlas 使用 Apache Kafka 作为通知服务器用于钩子和元数据通知事件的下游消费者之间的通信。事件由钩子和 Atlas 写到不同的 Kafka 主题。Titan介绍
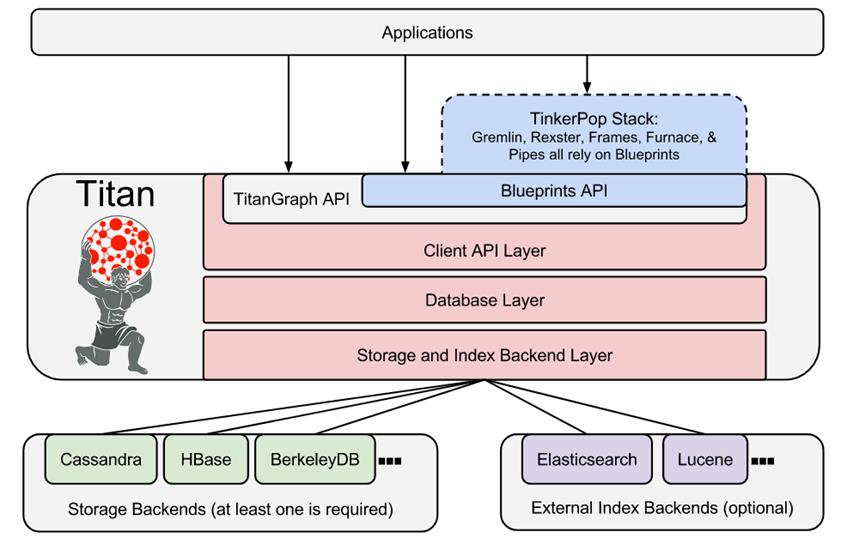
• Titan :目前, Atlas 使用 Titan 图数据库来存储元数据对象。 Titan 使用两个存储:默认情况下元数据存储配置为 HBase ,索引存储配置为 Solr 。也可以通过构建相应的配置文件将元数据存储作为 BerkeleyDB 和 Index 存储使用为 ElasticSearch 。元数据存储用于存储元数据对象本身,并且索引存储用于存储元数据属性的索引,其允许高效搜索 。 • 目前 基于 Java 使用最广泛的有两个开源框架
(1) neo4j
社区版 免费
企业版 收费
(2) Titan
全开源
Titan是一个分布式的图数据库,支持横向扩展,可容纳数千亿个顶点和边。 Titan支持事务,并且可以支撑上千并发用户和 计算复杂图形遍历。
安装
在安装前需要确定,你运行titan的Java环境为1.8+ *
1) 将安装包拷贝到安装位置后解压缩:
unzip titan-1.0.0-hadoop2.zip
2) 删除并添加相关jar包
官方提供的hadoop2的安装包有一些问题,如果想要顺利的使用titan,必须删除相关的jar包,并添加一些缺失的jar包:
a. 删除异常jar包
hadoop-core-1.2.1.jar
b. 添加所需要的jar包,这些jar包可以通过maven进行下载
titan-hadoop-1.0.0.jar
titan-hadoop-core-1.0.0.jar
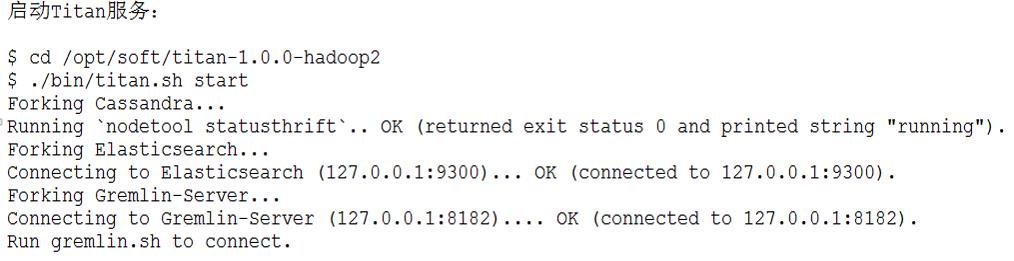
启动
• titan 安装后,使用默认配置启动 titan 服务。 • 默认情况下, titan 会启动三个服务: • • Cassandra 作为后端数据库存储图数据 • Elasticsearch 作为索引,提高图的检索效率 • Gremlin-Server 图数据库引擎,支持 gremlin 数据查询 语法
测试
./bin/gremlin.sh
:remote connect tinkerpop.serverconf/remote.yaml
//初始化
graph=TitanFactory.open('conf/titan-cassandra-es.properties')
GraphOfTheGodsFactory.load(graph)
g=graph.traversal()
//获取saturn点
saturn=g.V().has('name', 'saturn').next()
g.V(saturn).valueMap()
//查看saturn孙子
g.V(saturn).in('father').in('father').values('name')
//查看hercules父母
hercules = g.V().has('name', 'hercules').next()
g.V(hercules).out('father', 'mother').values('name')
Atlas配置
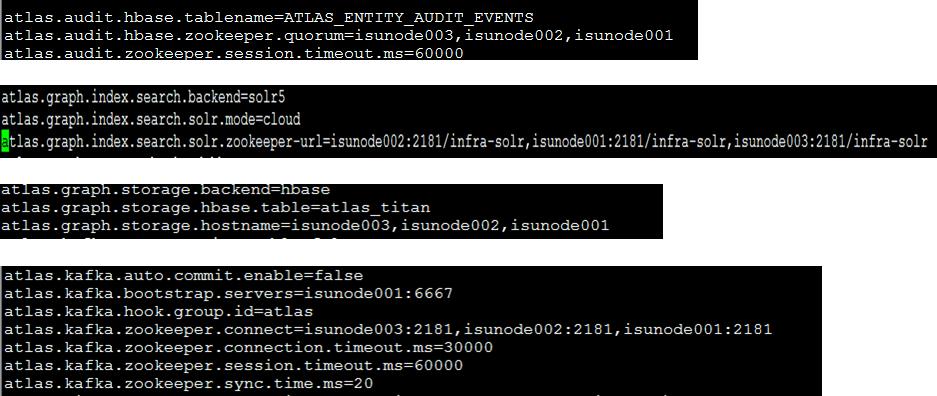
1,Atlas安装后默认hbase和solr存储,如果想修改存储介质,需要修改
/usr/hdp/2.6.0.3-8/atlas/conf/atlas-application.properties
2,Atlas安装完之后会在hive-site.xml文件中插入,是一个钩子函数

Hive 在使用 hive hook 的hive 命令执行上支持侦听器。 这用于在 Atlas 中使用org.apache.atlas.hive.model.HiveDataModelGenerator 中定义的模型添加/更新/删除实体。 hive hook将请求提交给线程池执行器,以避免阻塞命令执行。 线程将实体作为消息提交给通知服务器,并且服务器读取这些消息并注册实体。
3,如果Atlas中没有元数据,需要手动执行
/usr/hdp/2.6.0.3-8/atlas/hook-bin/import-hive.sh
4,Atlas高可用
要在 Atlas 中设置高可用性,必须在 atlas-application.properties文件中定义一些配置选项。
•高可用性是Atlas 的可选功能。因此,必须通过将配置选项atlas.server.ha.enabled设置为true 来启用。 •接下来,定义标识符列表,为您为 Atlas Web Service 实例选择的每个物理机器分配一个标识符。这些标识符可以是简单的字符串,如id1,id2等。它们应该是唯一的,不应包含逗号。 •将这些标识符的逗号分隔列表定义为选项 atlas.server.ids的值。 •对于每个物理机,请列出IP地址/主机名和端口作为配置 atlas.server.address.id的值,其中 id指的是此物理机的标识符字符串。•例如,如果您选择了 2台主机名为 http://host1.company.com和 http://host2.company.com的计算机,则可以如下定义配置选项: • atlas.server.ids=id1,id2 • atlas.server.address.id1=host1.company.com:21000 • atlas.server.address.id2=host2.company.com:21000 •定义使用的 Zookeeper为 Atlas提供高可用性功能
atlas.server.ha.zookeeper.connect=zk1.company.com:2181,zk2.company.com:2181,zk3.comp
•要验证高可用性是否正常工作,请在安装了 Atlas Web Service 的每个实例上运行以下脚本。$ATLAS_HOME/bin/atlas_admin.py -status
以下hive 操作由 hive hook 当前捕获
create database
create table/view, create table as select
load, import, export
DMLs (insert)
alter database
alter table (skewed table information, stored as, protection is notsupported)
alter view
案例
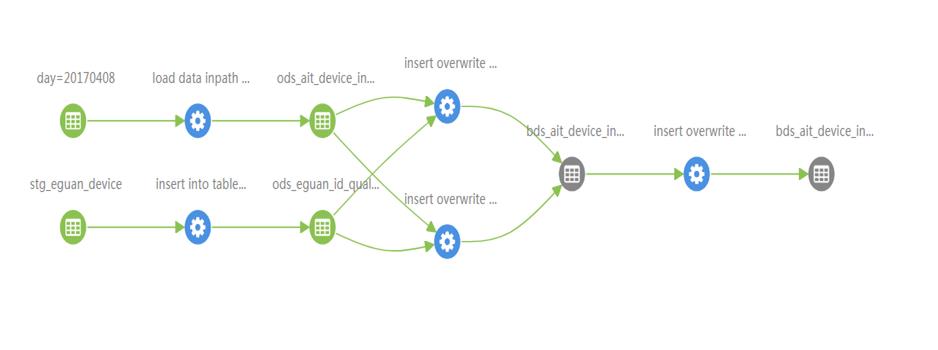
REST API
http://192.168.200.13:21000/api/atlas/lineage/hive/table/stg.stg_device_info_d@test/inputs/graph
http://192.168.200.13:21000/api/atlas/lineage/hive/table/stg.stg_device_info_d@test/outputs/graph
注意:已经删除的表,RESTAPI不能查询,但是图形化工具可以查询
总结
ApacheAtlas可监控数据的流向
ApacheRanger统一授权管理

以上是关于Apache Atlas 的初始密码及账户管理的主要内容,如果未能解决你的问题,请参考以下文章