请教kubernetes部署问题,pod一直处于pending状态
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了请教kubernetes部署问题,pod一直处于pending状态相关的知识,希望对你有一定的参考价值。
参考技术A 我们先从整体上看一下Kubernetes的一些理念和基本架构,然后从网络、资源管理、存储、服务发现、负载均衡、高可用、rollingupgrade、安全、监控等方面向大家简单介绍Kubernetes的这些主要特性。 当然也会包括一些需要注意的问题。主要目的是帮助大家快速理解Kubernetes的主要功能,今后在研究和使用这个具的时候有所参考和帮助。 1.Kubernetes的一些理念: 用户不需要关心需要多少台机器,只需要关心软件(服务)运行所需的环境。以服务为中心,你需要关心的是api,如何把大服务拆分成小服务,如何使用api去整合它们。 保证系统总是按照用户指定的状态去运行。 不仅仅提给你供容器服务,同样提供一种软件系统升级的方式;在保持HA的前提下去升级系统是很多用户最想要的功能,也是最难实现的。 那些需要担心和不需要担心的事情。 更好的支持微服务理念,划分、细分服务之间的边界,比如lablel、pod等概念的引入。 对于Kubernetes的架构,可以参考官方文档。 大致由一些主要组件构成,包括Master节点上的kube-apiserver、kube-scheduler、kube-controller-manager、控制组件kubectl、状态存储etcd、Slave节点上的kubelet、kube-proxy,以及底层的网络支持(可以用Flannel、OpenVSwitch、Weave等)。 看上去也是微服务的架构设计,不过目前还不能很好支持单个服务的横向伸缩,但这个会在Kubernetes的未来版本中解决。 2.Kubernetes的主要特性 会从网络、服务发现、负载均衡、资源管理、高可用、存储、安全、监控等方面向大家简单介绍Kubernetes的这些主要特性->由于时间有限,只能简单一些了。 另外,对于服务发现、高可用和监控的一些更详细的介绍,感兴趣的朋友可以通过这篇文章了解。 1)网络 Kubernetes的网络方式主要解决以下几个问题: a.紧耦合的容器之间通信,通过Pod和localhost访问解决。 b.Pod之间通信,建立通信子网,比如隧道、路由,Flannel、OpenvSwitch、Weave。 c.Pod和Service,以及外部系统和Service的通信,引入Service解决。 Kubernetes的网络会给每个Pod分配一个IP地址,不需要在Pod之间建立链接,也基本不需要去处理容器和主机之间的端口映射。 注意:Pod重建后,IP会被重新分配,所以内网通信不要依赖PodIP;通过Service环境变量或者DNS解决。 2)服务发现及负载均衡 kube-proxy和DNS,在v1之前,Service含有字段portalip和publicIPs,分别指定了服务的虚拟ip和服务的出口机ip,publicIPs可任意指定成集群中任意包含kube-proxy的节点,可多个。portalIp通过NAT的方式跳转到container的内网地址。在v1版本中,publicIPS被约定废除,标记为deprecatedPublicIPs,仅用作向后兼容,portalIp也改为ClusterIp,而在serviceport定义列表里,增加了nodePort项,即对应node上映射的服务端口。 DNS服务以addon的方式,需要安装skydns和kube2dns。kube2dns会通过读取KubernetesAPI获取服务的clusterIP和port信息,同时以watch的方式检查service的变动,及时收集变动信息,并将对于的ip信息提交给etcd存档,而skydns通过etcd内的DNS记录信息,开启53端口对外提供服务。大概的DNS的域名记录是servicename.namespace.tenx.domain,逗tenx.domain地是提前设置的主域名。 注意:kube-proxy在集群规模较大以后,可能会有访问的性能问题,可以考虑用其他方式替换,比如HAProxy,直接导流到Service的endpints或者Pods上。Kubernetes官方也在修复这个问题。 3)资源管理 有3个层次的资源限制方式,分别在Container、Pod、Namespace层次。Container层次主要利用容器本身的支持,比如Docker对CPU、内存、磁盘、网络等的支持;Pod方面可以限制系统内创建Pod的资源范围,比如最大或者最小的CPU、memory需求;Namespace层次就是对用户级别的资源限额了,包括CPU、内存,还可以限定Pod、rc、service的数量。 资源管理模型-》简单、通用、准确,并可扩展 目前的资源分配计算也相对简单,没有什么资源抢占之类的强大功能,通过每个节点上的资源总量、以及已经使用的各种资源加权和,来计算某个Pod优先非配到哪些节点,还没有加入对节点实际可用资源的评估,需要自己的schedulerplugin来支持。其实kubelet已经可以拿到节点的资源,只要进行收集计算即可,相信Kubernetes的后续版本会有支持。 4)高可用 主要是指Master节点的HA方式官方推荐利用etcd实现master选举,从多个Master中得到一个kube-apiserver保证至少有一个master可用,实现highavailability。对外以loadbalancer的方式提供入口。这种方式可以用作ha,但仍未成熟,据了解,未来会更新升级ha的功能。 一张图帮助大家理解: 也就是在etcd集群背景下,存在多个kube-apiserver,并用pod-master保证仅是主master可用。同时kube-sheduller和kube-controller-manager也存在多个,而且伴随着kube-apiserver同一时间只能有一套运行。 5)rollingupgrade RC在开始的设计就是让rollingupgrade变的更容易,通过一个一个替换Pod来更新service,实现服务中断时间的最小化。基本思路是创建一个复本为1的新的rc,并逐步减少老的rc的复本、增加新的rc的复本,在老的rc数量为0时将其删除。 通过kubectl提供,可以指定更新的镜像、替换pod的时间间隔,也可以rollback当前正在执行的upgrade操作。 同样,Kuberntes也支持多版本同时部署,并通过lable来进行区分,在service不变的情况下,调整支撑服务的Pod,测试、监控新Pod的工作情况。 6)存储 大家都知道容器本身一般不会对数据进行持久化处理,在Kubernetes中,容器异常退出,kubelet也只是简单的基于原有镜像重启一个新的容器。另外,如果我们在同一个Pod中运行多个容器,经常会需要在这些容器之间进行共享一些数据。Kuberenetes的Volume就是主要来解决上面两个基础问题的。 Docker也有Volume的概念,但是相对简单,而且目前的支持很有限,Kubernetes对Volume则有着清晰定义和广泛的支持。其中最核心的理念:Volume只是一个目录,并可以被在同一个Pod中的所有容器访问。而这个目录会是什么样,后端用什么介质和里面的内容则由使用的特定Volume类型决定。 创建一个带Volume的Pod: spec.volumes指定这个Pod需要的volume信息spec.containers.volumeMounts指定哪些container需要用到这个VolumeKubernetes对Volume的支持非常广泛,有很多贡献者为其添加不同的存储支持,也反映出Kubernetes社区的活跃程度。 emptyDir随Pod删除,适用于临时存储、灾难恢复、共享运行时数据,支持RAM-backedfilesystemhostPath类似于Docker的本地Volume用于访问一些本地资源(比如本地Docker)。 gcePersistentDiskGCEdisk-只有在GoogleCloudEngine平台上可用。 awsElasticBlockStore类似于GCEdisk节点必须是AWSEC2的实例nfs-支持网络文件系统。 rbd-RadosBlockDevice-Ceph secret用来通过KubernetesAPI向Pod传递敏感信息,使用tmpfs(aRAM-backedfilesystem) persistentVolumeClaim-从抽象的PV中申请资源,而无需关心存储的提供方 glusterfs iscsi gitRepo 根据自己的需求选择合适的存储类型,反正支持的够多,总用一款适合的:) 7)安全 一些主要原则: 基础设施模块应该通过APIserver交换数据、修改系统状态,而且只有APIserver可以访问后端存储(etcd)。 把用户分为不同的角色:Developers/ProjectAdmins/Administrators。 允许Developers定义secrets对象,并在pod启动时关联到相关容器。 以secret为例,如果kubelet要去pull私有镜像,那么Kubernetes支持以下方式: 通过dockerlogin生成.dockercfg文件,进行全局授权。 通过在每个namespace上创建用户的secret对象,在创建Pod时指定imagePullSecrets属性(也可以统一设置在serviceAcouunt上),进行授权。 认证(Authentication) APIserver支持证书、token、和基本信息三种认证方式。 授权(Authorization) 通过apiserver的安全端口,authorization会应用到所有http的请求上 AlwaysDeny、AlwaysAllow、ABAC三种模式,其他需求可以自己实现Authorizer接口。 8)监控 比较老的版本Kubernetes需要外接cadvisor主要功能是将node主机的containermetrics抓取出来。在较新的版本里,cadvior功能被集成到了kubelet组件中,kubelet在与docker交互的同时,对外提供监控服务。 Kubernetes集群范围内的监控主要由kubelet、heapster和storagebackend(如influxdb)构建。Heapster可以在集群范围获取metrics和事件数据。它可以以pod的方式运行在k8s平台里,也可以单独运行以standalone的方式。 注意:heapster目前未到1.0版本,对于小规模的集群监控比较方便。但对于较大规模的集群,heapster目前的cache方式会吃掉大量内存。因为要定时获取整个集群的容器信息,信息在内存的临时存储成为问题,再加上heaspter要支持api获取临时metrics,如果将heapster以pod方式运行,很容易出现OOM。所以目前建议关掉cache并以standalone的方式独立出k8s平台。本回答被提问者采纳Kubernetes对象之Pod
Pod是Kubernetes调度的最小单元。一个Pod可以包含一个或多个容器,因此它可以被看作是内部容器的逻辑宿主机。Pod的设计理念是为了支持多个容器在一个Pod中共享网络和文件系统 因此处于一个Pod中的多个容器共享以下资源:
PID命名空间:Pod中不同的应用程序可以看到其他应用程序的进程ID。
network命名空间:Pod中多个容器处于同一个网络命名空间,因此能够访问的IP和端口范围都是相同的。也可以通过localhost相互访问。
IPC命名空间:Pod中的多个容器共享Inner-process Communication命名空间,因此可以通过SystemV IPC或POSIX进行进程间通信。
UTS命名空间:Pod中的多个容器共享同一个主机名。Volumes:Pod中各个容器可以共享在Pod中定义分存储卷(Volume)。
Pod,容器与Node(工作主机)之间的关系如下图所示:
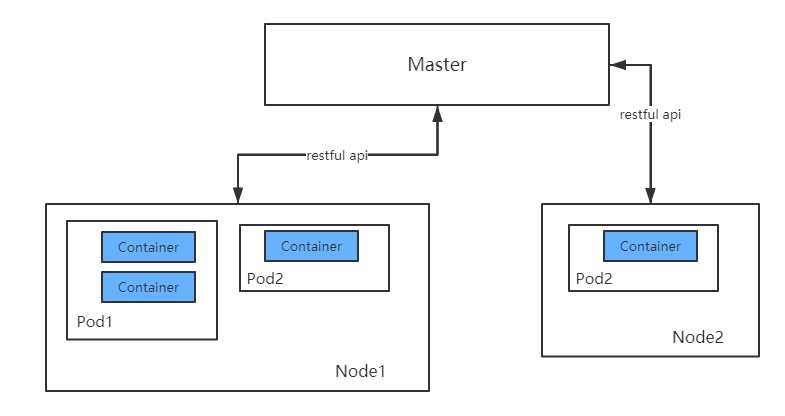
1. Pod的定义
通过yaml文件或者json描述Pod和其内容器的运行环境和期望状态,例如一个最简单的运行nginx应用的pod,定义如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
在生产环境中,推荐使用诸如Deployment,StatefulSet,Job或者CronJob等控制器来创建Pod,而不是直接创建。
将上述pod描述文件保存为nginx-pod.yaml,使用kubectl apply命令运行pod
kubectl apply -f nginx-pod.yaml下面简要分析一下上面的Pod定义文件:
- apiVersion: 使用哪个版本的Kubernetes API来创建此对象
- kind:要创建的对象类型,例如Pod,Deployment等
- metadata:用于唯一区分对象的元数据,包括:name,UID和namespace
- labels:是一个个的key/value对,定义这样的label到Pod后,其他控制器对象可以通过这样的label来定位到此Pod,从而对Pod进行管理。(参见Deployment等控制器对象)
spec: 其它描述信息,包含Pod中运行的容器,容器中运行的应用等等。不同类型的对象拥有不同的spec定义。详情参见API文档:https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.9/
Kubernetes在每个Pod启动时,会自动创建一个镜像为
gcr.io/google_containers/pause:version的容器,所有处于该Pod中的容器在启动时都会添加诸如--net=container:pause --ipc=contianer:pause --pid=container:pause的启动参数,因此pause容器成为Pod内共享命名空间的基础。所有容器共享pause容器的IP地址,也被称为Pod IP。
如果我们希望从外部访问这nginx应用,那么我们还需要创建Service对象来暴露IP和port。
2. Pod的生命周期
Pod的生命周期是Replication Controller进行管理的。一个Pod的生命周期过程包括:
通过yaml或json对Pod进行描述
apiserver(运行在Master主机)收到创建Pod的请求后,将此Pod对象的定义存储在etcd中
scheduler(运行在Master主机)将此Pod分配到Node上运行
Pod内所有容器运行结束后此Pod也结束
在整个过程中,Pod通常处于以下的五种阶段之一:
Pending:Pod定义正确,提交到Master,但其所包含的容器镜像还未完全创建。通常,Master对Pod进行调度需要一些时间,Node进行容器镜像的下载也需要一些时间,启动容器也需要一定时间。(写数据到etcd,调度,pull镜像,启动容器)。
Running:Pod已经被分配到某个Node上,并且所有的容器都被创建完毕,至少有一个容器正在运行中,或者有容器正在启动或重启中。
Succeeded:Pod中所有的容器都成功运行结束,并且不会被重启。这是Pod的一种最终状态
Failed:Pod中所有的容器都运行结束了,其中至少有一个容器是非正常结束的(exit code不是0)。这也是Pod的一种最终状态。
Unknown:无法获得Pod的状态,通常是由于无法和Pod所在的Node进行通信。
2.1 Restart policy
定义Pod时,可以指定restartPolicy字段,表明此Pod中的容器在何种条件下会重启。restartPolicy拥有三个候选值:
Always:只要退出就重启
OnFailure:失败退出时(exit code不为0)才重启
Never:永远不重启
2.2 通过controller管理Pod
Pod本身不具备容错性,这意味着如果Pod运行的Node宕机了,那么该Pod无法恢复。因此推荐使用Deployment等控制器来创建Pod并管理。
一般来说,Pod不会自动消失,只能手动销毁或者被预先定义好的controller销毁。但有一种特殊情况,当Pod处于Succeeded或Failed阶段,并且超过一定时间后(由master决定),会触发超时过期从而被销毁。
总体上来说,Kubernetes中拥有三种类型的controller:
Job。通常用于管理一定会结束的Pod。如果希望Pod被Job controller管理,那么restartPolicy必须指定为OnFailure或Never。
ReplicationController,ReplicaSet和Deployment。用于管理永远处于运行状态的Pod。如果希望Pod被此类controller管理,那么restartPolicy必须指定为Always。
DaemonSet。它能够保证你的Pod在每一台Node都运行一个副本。
以上是关于请教kubernetes部署问题,pod一直处于pending状态的主要内容,如果未能解决你的问题,请参考以下文章