从python基础到爬虫的书有啥值得推荐
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从python基础到爬虫的书有啥值得推荐相关的知识,希望对你有一定的参考价值。
《Python3爬虫入门到精通课程视频【附软件与资料】【34课时】--崔庆才》百度网盘资源免费下载
链接:https://pan.baidu.com/s/1PM2MA-3Ba03Lcs2N_Xa1Rw
Python3爬虫入门到精通课程视频【附软件与资料】【34课时】--崔庆才|章节5: 分布式篇|章节4: 框架篇|章节3: 实战篇|章节2: 基础篇|章节1: 环境配置|Python3爬虫课程资料代码.zip|2018-Python3网络爬虫开发实战-崔庆才.pdf|课时06:Python爬虫常用库的安装.zip|课时05:Python多版本共存配置.zip|课时04:mysql的安装.zip|课时03:Redis环境配置.zip|课时02:MongoDB环境配置.zip|课时01:Python3+Pip环境配置.zip|课时13:Selenium详解.zip

《深度学习入门》([ 日] 斋藤康毅)电子书网盘下载免费在线阅读
资源链接:
链接: https://pan.baidu.com/s/1ddnvGv-r9PxjwMLpN0ZQIQ
书名:深度学习入门
作者:[ 日] 斋藤康毅
译者:陆宇杰
豆瓣评分:9.4
出版社:人民邮电出版社
出版年份:2018-7
页数:285
内容简介:本书是深度学习真正意义上的入门书,深入浅出地剖析了深度学习的原理和相关技术。书中使用Python3,尽量不依赖外部库或工具,从基本的数学知识出发,带领读者从零创建一个经典的深度学习网络,使读者在此过程中逐步理解深度学习。书中不仅介绍了深度学习和神经网络的概念、特征等基础知识,对误差反向传播法、卷积神经网络等也有深入讲解,此外还介绍了深度学习相关的实用技巧,自动驾驶、图像生成、强化学习等方面的应用,以及为什么加深层可以提高识别精度等“为什么”的问题。
作者简介:
斋藤康毅
东京工业大学毕业,并完成东京大学研究生院课程。现从事计算机视觉与机器学习相关的研究和开发工作。是Introducing Python、Python in Practice、The Elements of Computing Systems、Building Machine Learning Systems with Python的日文版译者。
译者简介:
陆宇杰
众安科技NLP算法工程师。主要研究方向为自然语言处理及其应用,对图像识别、机器学习、深度学习等领域有密切关注。Python爱好者。


目标
Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
使用过程创建一个Scrapy项目定义提取的Item编写爬取网站的 spider 并提取 Item编写Item Pipeline 来存储提取到的Item(即数据)
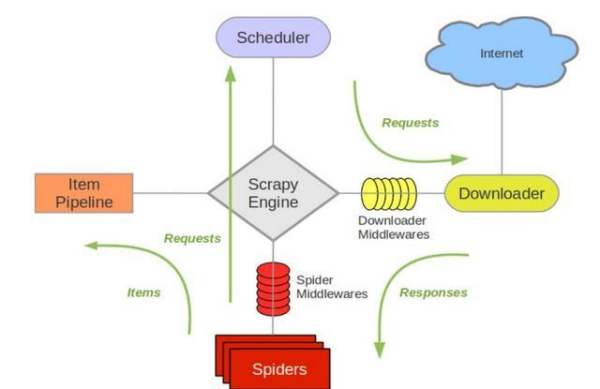
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述
Paste_Image.png
组件
Scrapy Engine引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。详细内容查看下面的数据流(Data Flow)部分。调度器(Scheduler)调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。下载器(Downloader)下载器负责获取页面数据并提供给引擎,而后提供给spider。SpidersSpider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。每个spider负责处理一个特定(或一些)网站。更多内容请看 Spiders 。Item PipelineItem Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证及持久化(例如存取到数据库中)。更多内容查看 Item Pipeline 。下载器中间件(Downloader middlewares)下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看下载器中间件(Downloader Middleware)。Spider中间件(Spider middlewares)Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware)。
三:实例分析
1.从网站的主页进入最新斗图表情后网址是http://www.doutula.com/photo/list/,点击第二页后看到网址变成了http://www.doutula.com/photo/list/?page=2,那我们就知道了网址的构成最后的page就是不同的页数。那么spider中的start_urls开始入口就如下定义,爬取1到20页的图片表情。想下载更多表情页数你可以再增加。start_urls =[\'http://www.doutula.com/photo/list/?page=\'.format(i) for i in range(1,20)]
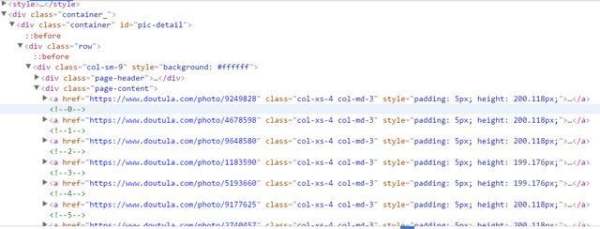
2.进入开发者模式分析网页结构,可以看到如下结构。右击复制一下xpath地址即可得到全部的表情所在的a标签内容。a[1]表示第一个a,去掉[1]就是全部的a。//*[@id="pic-detail"]/div/div[1]/div[2]/a
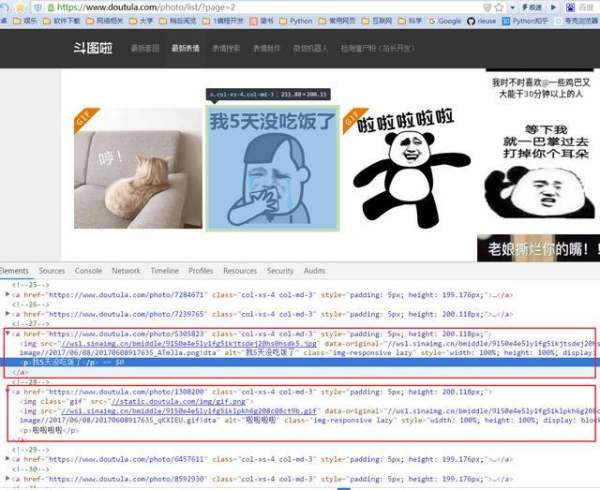
值得注意的是这里的表情有两种:一个jpg,一个gif动图。如果获取图片地址时只抓取a标签下面第一个img的src就会出错,所以我们要抓取img中的含有data-original的值。这里a标签下面还一个p标签是图片简介,我们也抓取下来作为图片文件的名称。图片的连接是\'http:\'+ content.xpath(\'//img/@data-original\')
四:实战代码
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。scrapy startproject ScrapyDoutucd ScrapyDoutu\\\\ScrapyDoutu\\\\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。import scrapyclass DoutuItem(scrapy.Item):
3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。#-*- coding: utf-8-*-import os
3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中content.xpath(\'//img/@data-original\').extract()[i]中extract()用来返回一个list(就是系统自带的那个)里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。filename =\'doutu\\\\\'.format(item[\'name\'])+ item[\'img_url\'][-4:]是用来获取图片的名称,最后item[\'img_url\'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。最后一点就是如果xpath没有正确匹配,则会出现(referer: None)
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.#-*- coding: utf-8-*-BOT_NAME =\'ScrapyDoutu\'SPIDER_MODULES =[\'ScrapyDoutu.spiders\']NEWSPIDER_MODULE =\'ScrapyDoutu.spiders\'DOWNLOADER_MIDDLEWARES =
5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
6.到现在为止,代码都已经完成了。那么开始执行吧!
scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
五:总结
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
github地址加群
学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入学习交流群
,我们一起学Python!
参考技术C 于我个人而言,我很喜欢Python,当然我也有很多的理由推荐你去学python.我只说两点.一是简单,二是写python薪资高.我觉得这俩理由就够了,对不对.买本书,装上pycharm,把书上面的例子习题都敲一遍.再用flask,web.py等框架搭个小网站.. 完美...(小伙伴们有问到该学python2.7还是3.X,那我的答案是:目前大多数实际开发,都是用2.7的,因为实际项目开发有很多依赖的包,都只支持到2.7,你用3.X干不了活.那你能怎么办.所以不需要纠结.等3.X普及,你写的2.7代码,都可以无痛移植,妥妥的不用担心.)第一个
个人认为《Python学习手册:第3版》是学习语言基础比较好的书了.
《Python学习手册(第3版)》讲述了:Python可移植、功能强大、易于使用,是编写独立应用程序和脚本应用程序的理想选择。无论你是刚接触编程或者刚接触Python,通过学习《Python学习手册(第3版)》,你可以迅速高效地精通核心Python语言基础。读完《Python学习手册(第3版)》,你会对这门语言有足够的了解,从而可以在你所从事的任何应用领域中使用它。
《Python学习手册(第3版)》是作者根据过去10年用于教学而广为人知的培训课程的材料编写而成的。除了有许多详实说明和每章小结之外,每章还包括一个头脑风暴:这是《Python学习手册(第3版)》独特的一部分,配合以实用的练习题和复习题,让读者练习新学的技巧并测试自己的理解程度。
《Python学习手册(第3版)》包括:
类型和操作——深入讨论Python主要的内置对象类型:数字、列表和字典等。
语句和语法——在Python中输入代码来建立并处理对象,以及Python一般的语法模型。
函数——Python基本的面向过程工具,用于组织代码和重用。
模块——封装语句、函数以及其他工具,从而可以组织成较大的组件。
类和OOP——Python可选的面向对象编程工具,可用于组织程序代码从而实现定制和重用。
异常和工具——异常处理模型和语句,并介绍编写更大程序的开发工具。
讨论Python 3.0。
《Python学习手册(第3版)》让你对Python语言有深入而完整的了解,从而帮助你理解今后遇到的任何Python应用程序实例。如果你准备探索Google和YouTube为什么选中了Python,《Python学习手册(第3版)》就是你入门的最佳指南。
第二个
《Python基础教程(第2版·修订版)》也是经典的Python入门教程,层次鲜明,结构严谨,内容翔实,特别是最后几章,作者将前面讲述的内容应用到10个引人入胜的项目中,并以模板的形式介绍了项目的开发过程,手把手教授Python开发,让读者从项目中领略Python的真正魅力。这本书既适合初学者夯实基础,又能帮助Python程序员提升技能,即使是Python方面的技术专家,也能从书里找到耳目一新的内容。
第三个
《“笨办法”学Python(第3版)》是一本Python入门书籍,适合对计算机了解不多,没有学过编程,但对编程感兴趣的初学者使用。这本书结构非常简单,其中覆盖了输入/输出、变量和函数三个主题,以及一些比较高级的话题,如条件判断、循环、类和对象、代码测试及项目的实现等。每一章的格式基本相同,以代码习题开始,按照说明编写代码,运行并检查结果,然后再做附加练习。这本书以习题的方式引导读者一步一步学习编程,从简单的打印一直讲授到完整项目的实现,让初学者从基础的编程技术入手,最终体验到软件开发的基本过程。
【大牛评价】hardway(笨办法)比较适合起步编程,作为Python的入门挺不错。
第四个
在这里给大家推荐最后一本《集体智慧编程》
本书以机器学习与计算统计为主题背景,专门讲述如何挖掘和分析Web上的数据和资源,如何分析用户体验、市场营销、个人品味等诸多信息,并得出有用的结论,通过复杂的算法来从Web网站获取、收集并分析用户的数据和反馈信息,以便创造新的用户价值和商业价值。
全书内容翔实,包括协作过滤技术(实现关联产品推荐功能)、集群数据分析(在大规模数据集中发掘相似的数据子集)、搜索引擎核心技术(爬虫、索引、查询引擎、PageRank算法等)、搜索海量信息并进行分析统计得出结论的优化算法、贝叶斯过滤技术(垃圾邮件过滤、文本过滤)、用决策树技术实现预测和决策建模功能、社交网络的信息匹配技术、机器学习和人工智能应用等。
本书是Web开发者、架构师、应用工程师等的绝佳选择。
“太棒了!对于初学这些算法的开发者而言,我想不出有比这本书更好的选择了,而对于像我这样学过Al的老朽而言,我也想不出还有什么更好的办法能够让自己重温这些知识的细节。”
——Dan Russell,资深技术经理,Google
“Toby的这本书非常成功地将机器学习算法这一复杂的议题拆分成了一个个既实用又易懂的例子,我们可以直接利用这些例子来分析当前网络上的社会化交互作用。假如我早两年读过这本书,就会省去许多宝贵的时间,也不至于走那么多的弯路了。”
——Tim Wolters,CTO,Collective Intellect
第五个
其实我觉得很多人也在看《Python核心编程:第2版》.在我自己看来,我并不喜欢这本书.
这本书的原书的勘误表就有够长的,翻译时却几乎没有参考勘误表,把原书的所有低级错误都搬进去了。这本书的原书质量也并不好,书的结构组织并不合理,不适合初学者阅读。有人说,这本书适合进阶阅读,我觉得也不尽然。这本书很多地方都写的欲言又止的,看得人很郁闷。 参考技术D
前两篇爬虫12(点击头像看历史)
资料仅供学习
方式一
直接爬取网站
http://chanyouji.com/(网站会拦截IP,第二篇就用到了)
1~打开网页,里面有很多人分享的游记,我们就进行游记爬取2~点开其中一篇游记,看到链接地址形式http://chanyouji.com/trips/,这个时候,思考,这个数字代表的含义?会不会是游记在数据库的ID,如果是的话那我们换个数字会不会得到别的游记,试一下访问http://chanyouji.com/trips/,确实看到了不一样的游记。自己试试
c).结论,我们可以来请求到不同的数据。然而,这并不一定是可以按照上两节的方式来爬取。原因有很多。比如,有些数据是通过js渲染的。对于有web开发基础的很好理解,但是对于没有做过web开发的同学解释一下。我们假设要买一个房子,房子种类很多,分成两类,一类是没有装修的,另一类是装修好的。对于前者,我们要买家具装修布置,对于装修好的我们可以直接入住生活。带入例子http://chanyouji.com/trips/*****这个请求就买一个房子,没装修就是说返回的是这个网站的外壳,需要另外在JS里面重新请求数据,放到外壳里面。装修好的数据什么的直接给你。d).判断两类的结果:很简单。以火狐浏览器为例,F12打开调试窗口,找到网络->点击请求得到:
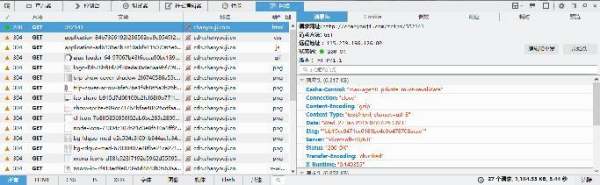
数据显示在里面后点开响应,会看到请求来的源代码(用爬虫发请求的结果)如下

e).假如是js渲染的,我没在这个网站上找到用js渲染的换个目标来解释。
方式二
目标网址:http://music.163.com/#/user/home?id=48353(一个网页)方法同上
a).这个http://music.163.com/user/home?id=48353缺少了歌单
b).我们寻找那个歌单的数据
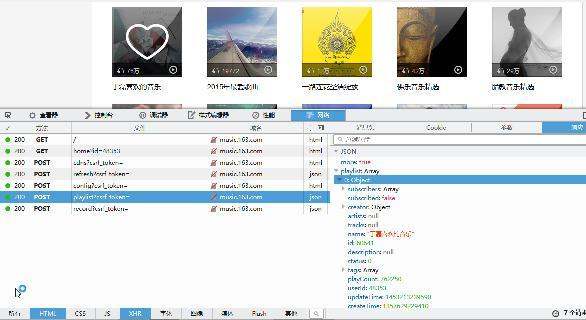
发现http://music.163.com/weapi/user/playlist?csrf_token=这个就是返回的歌单,我们只需要请求这个接口的时候,带上该有的参数,就能得到这个数据。
方式三
(新)进行利用目标网址的APP,仍以蝉游记进行
APP的接口返回值一般都是JSON(比较好解析除了网易云音乐)核心:拦截APP请求。
a).我在电脑上安装安卓模拟器(用的是bluestacks不太好安装的)b).在里面安装APP蝉游记(还可以用电脑开个热点,用手机连接这个热点也能拦截)c).安装httpanalyzer其他的也行,打开httpanalyzerd).使用目标APP拦截到请求如下

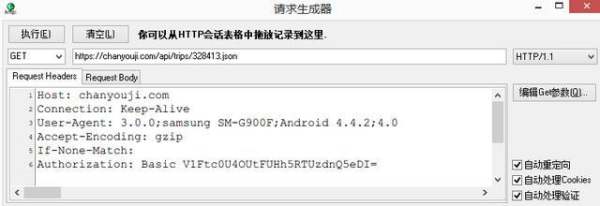
e).请求时注意http和http的区别。遇到http的请求,试下用http替换。(有的比较麻烦不行)
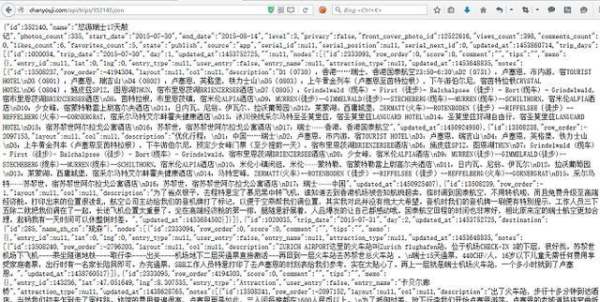
f).把数据转化成标准的json数据,用这个工具http://www.bejson.com/jsonviewernew/
把数据复制过去格式化一下
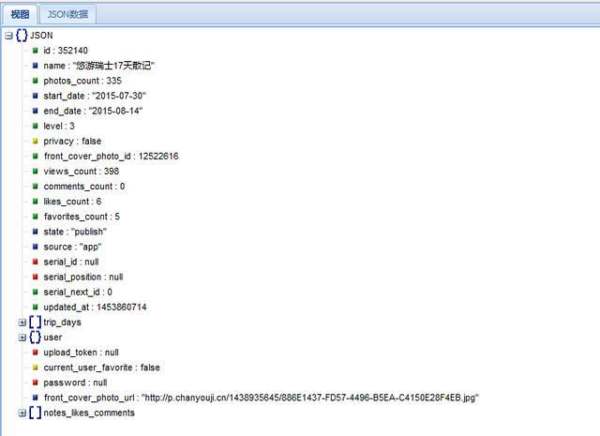
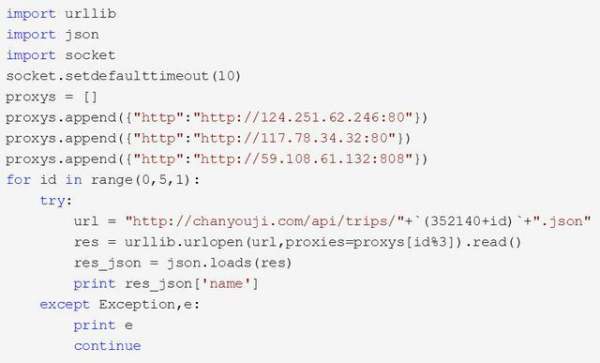
游记代码

结果

学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入学习交流群
,我们一起学Python!
每天晚上都有大神与你高清视频免费分享交流行业最新动态凑热闹就不要加了群名额有限!
学习Android 开发,有啥书籍值得推荐
入门的话就《疯狂Android讲义》
但是推荐看一下《Android权威指南》里面对frgment讲的很详细,书也比较新,疯狂Android讲义那本书更适合做字典用。。。。
基础入门的书的话就这两本感觉就可以了,其他的什么Android4.0高级编程之类的,感觉都差不多。
如果LZ相接触NDK开发的话,推荐《Android C++高级编程:使用NDK》亚马逊还有一本叫《细说Android 4.0 NDK编程》,这本书讲NDK很是扯淡,不过意外的发现这本书的附录
的讲UI的部分还是不错的。
如果LZ还想接着学的话看看《精通Android》这一类图灵系列丛书或者看看深入Android学习泽一系列的,比如《Android开发精要》就是其中一本,感觉这一个系列的书还是很不错的。
LZ如果还想接着搞系统源码的话推荐看看《深入理解Android内核设计思想》老罗那一套看不懂....
到这里LZ估计也会发现没有讲frameworks层源代码的书。。。唯一的途径就是要么看看sdk,要么自己编译一下源码看看吧。。。。
参考技术A 书名:第一行代码,该作者的博客也有更,你可以去看看以上是关于从python基础到爬虫的书有啥值得推荐的主要内容,如果未能解决你的问题,请参考以下文章