关于字符串截取与匹配
Posted cswxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于字符串截取与匹配相关的知识,希望对你有一定的参考价值。
看似做了一下午的无用功。
如题:想采用树形结构对字符串进行截取并匹配名,最后发现结果无疾而终。
需求描述:公司想对于用户在app端输入的文本进行关键字过滤,如果出现了某个敏感词汇,那么就禁止发表内容。
比如:敏感词汇:"狗蛋",用户输入的文本内容:"某某某是狗蛋。。。。。。。。",则禁止用户发表某个内容。
树形结构如下图所示:
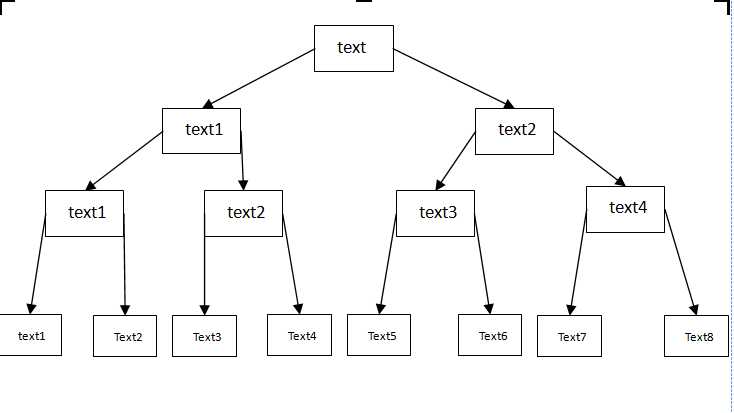
参考代码如下
public class Match {
/**
* @author
* date 11:03 2018/7/3
* Description 判断输入的字符串和目标的子串是否匹配
* 用target作为敏感词去匹配输入的文本串text
*/
public static boolean Match(String target, String text) {
//对获取到的字符串进行截取
//获取text字符串的长度textLength
Integer textLength = text.length();
//先使用最简单暴力的匹配方式进行匹配,之后再引入KMP算法进行详细的解释
String text1 = text.substring(0, textLength / 8);
String text2 = text.substring(textLength / 8, 2 * textLength / 8);
String text3 = text.substring(2 * textLength / 8, 3 * textLength / 8);
String text4 = text.substring(3 * textLength / 8, 4 * textLength / 8);
String text5 = text.substring(4 * textLength / 8, 5 * textLength / 8);
String text6 = text.substring(5 * textLength / 8, 6 * textLength / 8);
String text7 = text.substring(6 * textLength / 8, 7 * textLength / 8);
String text8 = text.substring(7 * textLength / 8);
if (text1.contains(target) || text2.contains(target) || text3.contains(target) || text4.contains(target)
|| text5.contains(target) || text6.contains(target) || text7.contains(target) || text8.contains(target)) {
return false;
}
text1 = text1 + text2;
text2 = text3 + text4;
text3 = text5 + text6;
text4 = text7 + text8;
if (text1.contains(target) || text2.contains(target) || text3.contains(target) || text4.contains(target)) {
return false;
}
text1 = text1 + text2;
text2 = text3 + text4;
if (text1.contains(target) || text2.contains(target)) {
return false;
}
if (text.contains(target)) {
return false;
}
return true;
}
public static void main(String[] args) {
String target = "狗蛋";
String text = "";//此处可以放入word文本内容(会上传)
//获取当前时间
Long startTime =System.nanoTime();
System.out.println(Match(target, text));
//获取当前时间
Long endTime =System.nanoTime();
//输出系统运行的时间
System.out.println(endTime-startTime);
}
}
在text的字串中放入大概万字文本内容。
链接:https://www.cnblogs.com/cswxl/p/9259853.html
经过测试发现,从原理上来说,如果能够匹配成功,树形结构的消耗一定会小于直接匹配的消耗。但是在这个过程中就要考虑树形结构,自身截取字符串的过程中也需要消耗时间。
针对于静态的字符串,最大的长度是65534,现在定义的text文本的长度为一万字左右,(已满)(一个汉字对应8个字节,中间出现有数字逗号等占容量比较少的字符)
通过比对发现,实际的实现过程中,如果注释掉树形结构的部分,那么两者消耗相抵消,甚至java自带的contains暴力匹配比树形结构的消耗更优。
相当于做了无用功,看以后是否能够做文本匹配,是否能够更加节省时间。
以上是关于关于字符串截取与匹配的主要内容,如果未能解决你的问题,请参考以下文章