整理常见排序算法及其时间复杂度总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整理常见排序算法及其时间复杂度总结相关的知识,希望对你有一定的参考价值。
原文出处:
1. 白话经典算法系列之八 MoreWindows白话经典算法之七大排序总结篇
3. 常见排序算法小结
本篇主要整理了冒泡排序,直接插入排序,直接选择排序,希尔排序,归并排序,快速排序,堆排序七种常见算法,是从上面三篇博文中摘抄整理的,非原创。
一、冒泡排序
主要思路是:
通过交换相邻的两个数变成小数在前大数在后,这样每次遍历后,最大的数就“沉”到最后面了。重复N次即可以使数组有序。
冒泡排序改进1:
在某次遍历中,如果没有数据交换,说明整个数组已经有序,因此通过设置标志位来记录此次遍历有无数据交换就可以判断是否要继续循环。
冒泡排序改进2:
记录某次遍历时最后发生数据交换的位置,这个位置之后的数据显然已经有序。因此设置标志位记录每次遍历中最后发生数据交换的位置可以确定下次循环的范围。

二、直接插入排序
主要思路是:
每次将一个待排序的数组元素,插入到前面已排序的序列中这个元素应该在的位置,直到全部数据插入完成。类似扑克牌洗牌过程。
三、直接选择排序
主要思路是:
数组分成有序区和无序区,初始时整个数组都是无序区,每次遍历都从无序区选择一个最小的元素直接放在有序区最后,直到排序完成。

四、快速排序
主要思路是:
“挖坑填数 + 分治法”,首先令i = L;j = R;将a[i]挖出形成打一个坑,称a[i]为基准数。然后j--从后向前找到一个比基准数小的数,挖出来填到a[i]的坑中,这样a[j]就形成了一个新的坑,再i++从前向后找到一个比基准数大的数填到a[j]坑中。重复进行这种挖坑填数,直到i = j。这时a[i]形成了一个新的坑,将基数填到a[i]坑中,这样i之前的数都比基准数小,i之后的数都比基准数大。因此将数组分成两部分再分别重复上述步骤就完成了排序。

五、希尔排序
主要思路是:
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。由于希尔排序是对相隔若干距离的数据进行直接插入排序,因此可以形象的称希尔排序为“跳着插”。
六、归并排序
主要思路是:
当一个数组左边有序,右边也有序,那合并这两个有序数组就完成了排序。如何让左右两边有序了?用递归!这样递归下去,合并上来就是归并排序。

七、堆排序
堆排序的难点就在于堆的的插入和删除。
堆的插入就是——每次插入都是将新数据放在数组最后,而从这个新数据的父结点到根结点必定是一个有序的数列,因此只要将这个新数据插入到这个有序数列中即可。
堆的删除就是——堆的删除就是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点开始将一个数据在有序数列中进行“下沉”。
因此,堆的插入和删除非常类似直接插入排序,只不是在二叉树上进行插入过程。所以可以将堆排序形容为“树上插”

再用一张图表示下这七种常用的排序方法的关系。

最后给出一张各算法的性能比较图
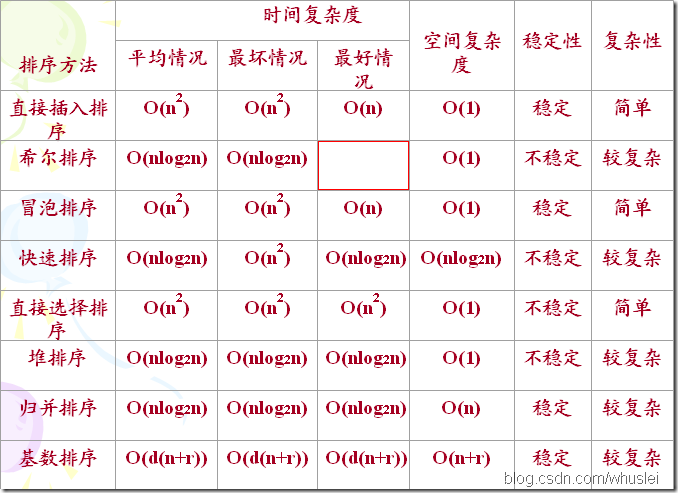
以上是关于整理常见排序算法及其时间复杂度总结的主要内容,如果未能解决你的问题,请参考以下文章