.递归获取所有页码
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.递归获取所有页码相关的知识,希望对你有一定的参考价值。
# -*- coding: utf-8 -*-
import scrapy
class GetChoutiSpider(scrapy.Spider):
name = ‘get_chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘https://dig.chouti.com/‘]
def parse(self, response):
# 在子子孙孙中找到所有id="dig_lcpage"的div标签
# 在对应的div标签中找到所有的a标签
# 获取所有对应a标签的href属性
# 加上extract()获取字符串
res = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract()
for url in res:
print(url)
‘‘‘
/all/hot/recent/2
/all/hot/recent/3
/all/hot/recent/4
/all/hot/recent/5
/all/hot/recent/6
/all/hot/recent/7
/all/hot/recent/8
/all/hot/recent/9
/all/hot/recent/10
/all/hot/recent/2
‘‘‘
# 会发现这里有重复的,因为我们起始是第一页,每次总共分十页。那么下一页指的就是第二页
# 所以会发现第二页重复的href重复了
# 可以定义一个集合
urls = set()
for url in res:
if url in urls:
print(f"{url}--此url已存在")
else:
urls.add(url)
print(url)
‘‘‘
/all/hot/recent/2
/all/hot/recent/3
/all/hot/recent/4
/all/hot/recent/5
/all/hot/recent/6
/all/hot/recent/7
/all/hot/recent/8
/all/hot/recent/9
/all/hot/recent/10
/all/hot/recent/2--此url已存在
‘‘‘
# -*- coding: utf-8 -*-
import scrapy
class GetChoutiSpider(scrapy.Spider):
name = ‘get_chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘https://dig.chouti.com/‘]
def parse(self, response):
# 上面是直接将url进行比较,但是一般情况下我们不直接比较url
# url我们可能会放在缓存里,或者放在数据库里
# 如果url很长,会占用空间,因此我们会进行一个加密,比较加密之后的结果
res = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract()
# 也可以直接找到所有想要的a标签
‘‘‘
找到a标签,什么样的a标签,以"/all/hot/recent/"开头的a标签
res = response.xpath(‘//a[starts-with(@href, "/all/hot/recent/")]/@href‘).extract()
也可以通过正则表达式来找到a标签,re:test是固定写法
res = response.xpath(‘//a[re:test(@href, "/all/hot/recent/d+")]/@href‘).extract()
‘‘‘
md5_urls = set()
for url in res:
md5_url = self.md5(url)
if md5_url in md5_urls:
print(f"{url}--此url已存在")
else:
md5_urls.add(md5_url)
print(url)
def md5(self, url):
import hashlib
m = hashlib.md5()
m.update(bytes(url, encoding="utf-8"))
return m.hexdigest()
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
class GetChoutiSpider(scrapy.Spider):
name = ‘get_chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘https://dig.chouti.com/‘]
# 当递归查找时,会反复执行parse,因此md5_urls不能定义在parse函数里面
md5_urls = set()
def parse(self, response):
res = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract()
for url in res:
md5_url = self.md5(url)
if md5_url in self.md5_urls:
pass
else:
print(url)
self.md5_urls.add(md5_url)
# 将新的要访问的url放到调度器
url = "https://dig.chouti.com%s" % url
yield Request(url=url, callback=self.parse)
‘‘‘
/all/hot/recent/2
/all/hot/recent/3
/all/hot/recent/4
/all/hot/recent/5
/all/hot/recent/6
/all/hot/recent/7
/all/hot/recent/8
/all/hot/recent/9
/all/hot/recent/10
/all/hot/recent/1
/all/hot/recent/11
/all/hot/recent/12
........
........
........
/all/hot/recent/115
/all/hot/recent/116
/all/hot/recent/117
/all/hot/recent/118
/all/hot/recent/119
/all/hot/recent/120
‘‘‘
def md5(self, url):
import hashlib
m = hashlib.md5()
m.update(bytes(url, encoding="utf-8"))
return m.hexdigest()
可以看到,spider将所有的页码全都找出来了,但我不想它把全部页码都找出来,因此可以指定爬取的深度
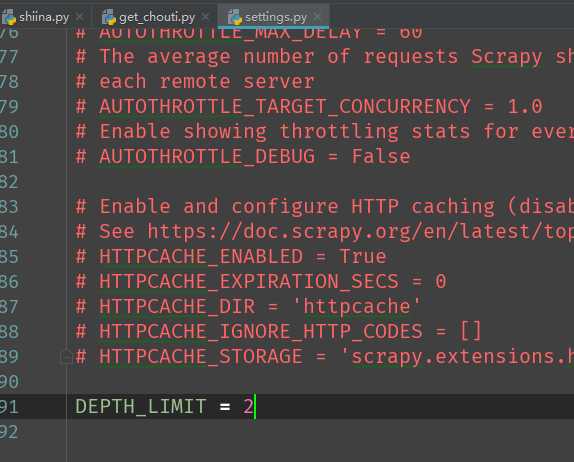
在settings里面加上DEPTH_LIMIT=2,表示只爬取两个深度,即当前十页完成之后再往后爬取两个深度。
如果DEPTH_LIMIT<0,那么只爬取一个深度,等于0,全部爬取,大于0,按照指定值爬取相应的深度
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
class GetChoutiSpider(scrapy.Spider):
name = ‘get_chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘https://dig.chouti.com/‘]
# 当递归查找时,会反复执行parse,因此md5_urls不能定义在parse函数里面
md5_urls = set()
def parse(self, response):
res = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract()
for url in res:
md5_url = self.md5(url)
if md5_url in self.md5_urls:
pass
else:
print(url)
self.md5_urls.add(md5_url)
# 将新的要访问的url放到调度器
url = "https://dig.chouti.com%s" % url
yield Request(url=url, callback=self.parse)
‘‘‘
/all/hot/recent/2
/all/hot/recent/3
/all/hot/recent/4
/all/hot/recent/5
/all/hot/recent/6
/all/hot/recent/7
/all/hot/recent/8
/all/hot/recent/9
/all/hot/recent/10
/all/hot/recent/1
/all/hot/recent/11
/all/hot/recent/12
/all/hot/recent/13
/all/hot/recent/14
/all/hot/recent/15
/all/hot/recent/16
/all/hot/recent/17
/all/hot/recent/18
‘‘‘
def md5(self, url):
import hashlib
m = hashlib.md5()
m.update(bytes(url, encoding="utf-8"))
return m.hexdigest()



因此在当前十页爬取完毕之后,再往下一个深度,是十四页,再往下一个深度是十八页
以上是关于.递归获取所有页码的主要内容,如果未能解决你的问题,请参考以下文章