实现服务高可用奇淫技巧
Posted jinjiangongzuoshi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现服务高可用奇淫技巧相关的知识,希望对你有一定的参考价值。
1. 前言
在上一篇通知文章有说过,六月份会开始更新公众号(当然一些好的文章我也会同步到博客中来,所以大家看到有些文章的内容和公众号中的是一样的),虽然现在已到月底了,但好歹也算没有失言,赶上了末班车了。
公众号中有很多读者留言,大家很期待能继续更新《RF接口自动化系列》文章,放心,牛奶会有的,面包也会有的,自己答应大家的,含泪也有完成的。
不过本篇仍不会更新《RF接口自动化系列》的文章,放心,后续会更新,敬请期待~
本篇会给大家介绍一下服务高可用的实现,大致也会分几篇文章进行讲解。
为什么突然会讲服务高可用,请看【背景】章节!
2. 背景
目前我们组内的主服务器docker主机(ubuntu系统),承载运行了我们组内(效率提升组)大部分对外提供的关键平台服务
先来看一张图吧
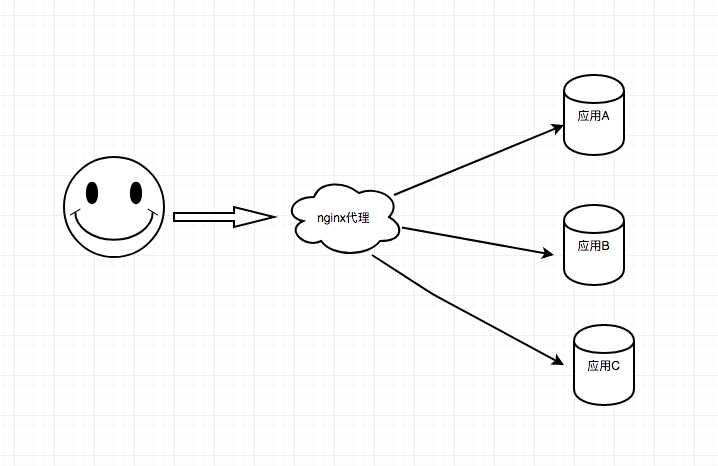
简单粗暴地画了一张精简图,从上图中直观地反映我们docker主机的一个简要架构图(如果你觉得真实部署架构也是如此简单, 那只能说明你还是太年轻了),用户访问我们的应用服务,如访问qa.xx.com应用服务(A),经过nginx代理,由nginx反向代理到实际应用服务A中。
这是常规应用部署最简单的单点结构,但作为这类关键服务节点,如果某天docker主机嗝屁了,那就意味着,所有运行在docker应用服务,就无法对外提供服务,可能有的人会说,这种情况,一般来说不会发生吧,好吧,前不久就发生的一宗因为机房中服务异常断电,重启后磁盘启动异常的案例。
所以就引出了本文,通过高可用的方案来解决应用单点部署当发生异常长时间无法对外提供服务的问题!
3. 高可用与负载均衡的区别
-
高可用集群中的节点一般是一主一备,或者一主多备,通过备份提高整个系统可用性。
-
而负载均衡集群一般是多主,每个节点都分担请求流量
4. 实现高可用的常用工具
-
ngnix
-
lvs (Linux虚拟服务器,是一个虚拟的服务器集群系统)
-
HAProxy(HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。)
-
keepalived(这里说的keepalived不是apache或者tomcat等某个组件上的属性字段,它也是一个组件,可以实现web服务器的高可用(HA high availably)。它可以检测web服务器的工作状态,如果该服务器出现故障被检测到,将其剔除服务器群中,直至正常工作后,keepalive会自动检测到并加入到服务器群里面。实现主备服务器发生故障时ip瞬时无缝交接。它是LVS集群节点健康检测的一个用户空间守护进程,也是LVS的引导故障转移模块(director failover)。Keepalived守护进程可以检查LVS池的状态。如果LVS服务器池当中的某一个服务器宕机了。keepalived会通过一 个setsockopt呼叫通知内核将这个节点从LVS拓扑图中移除。)
5. 高可用不能解决什么
高可用也就是大家常说的HA(High Availability),高可用的引入,是通过设计减少系统不能提供服务的时间,而不能保证系统可用性是能达到100%的!
6. 高可用实施中有哪些问题需要解决
高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:集群。
有了集群之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
所以,实现高可用的两个关键点:
-
集群化
-
自动故障转移
对于服务而言,一旦某个服务器宕机,就将服务切换到其他可用的服务器上;
对于数据而言,如果某个磁盘损坏,就从备份的磁盘(事先就做好了数据的同步复制)读取数据。
结合我们上图来看,要实现高可用的需要解决几个问题:
1、服务集群化,需要增加服务物理机 (利用现有的服务机或者新增购买一台新的服务机,建议后者)
2、nginx请求代理集群(请求入口需引入集群,否则应用服务有集群,nginx挂了,照样game over,所以需要解决如何让nginx可以集群,并能自动故障转移)
3、应用服务集群(服务不能单点部署,需集群部署,一个服务提供者挂了,其它可以顶上,所以需要解决如何让应用服务可以集群,并且服务异常可自动故障转移)
4、实现集群后,需保证集群间持久数据层是能保持同步一致的(mysql db、mongo db)
5、应用服务器集群的Session管理。
7. 高可用架构实践方案
整个系统的高可用,其实就是通过每一层的集群(冗余)+自动故障转移来综合实现的。
正如上述在需要解决的问题中,提到的:
1、要解决【客户端层→反向代理层】的高可用:
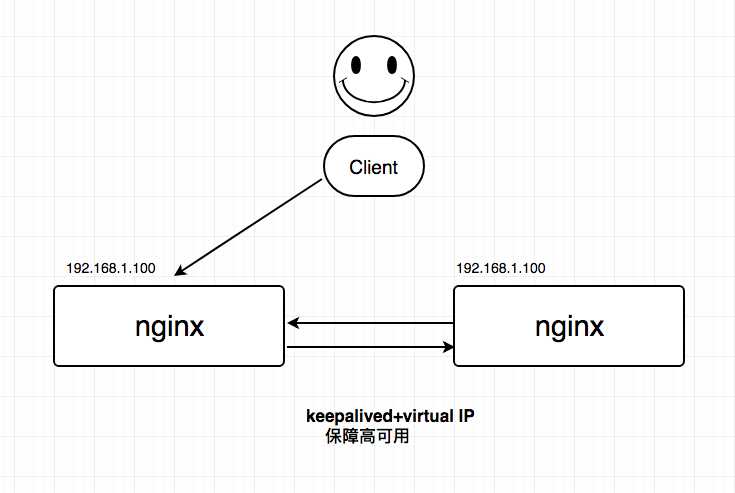
【客户端层】到【反向代理层】的高可用,是通过反向代理层的集群(冗余)来实现的。以nginx为例:需要准备至少两台nginx,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
【正常图】:
【其中一台nginx嗝屁了】:

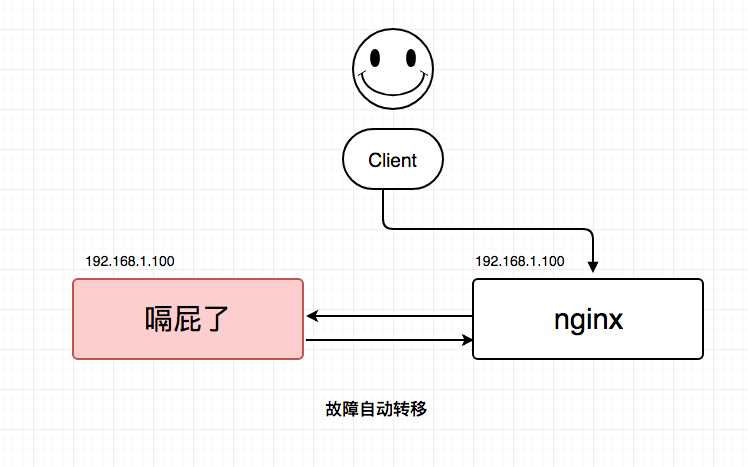
自动故障转移:当nginx挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到另外一台nginx,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
2、要解决【反向代理层→应用服务站点层】的高可用
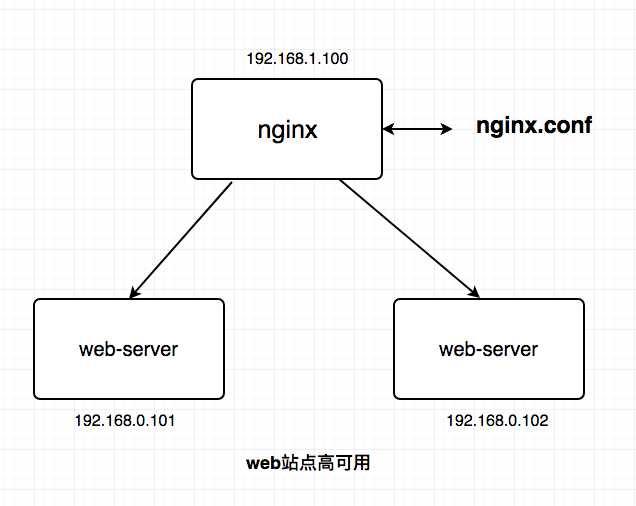
【反向代理层】到【站点层】的高可用,是通过站点层的集群(冗余)来实现的。假设反向代理层是nginx,nginx.conf里能够配置多个web后端,并且nginx能够探测到多个后端的存活性。
【正常图】:
【其中一台站点服务嗝屁了】:
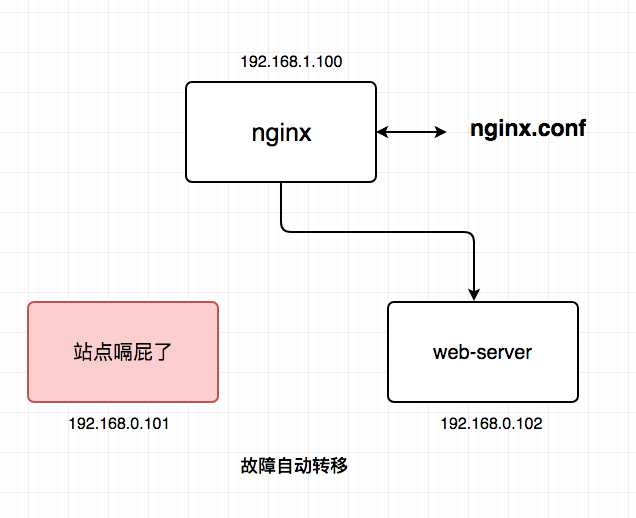
自动故障转移:当web-server服务站点挂了的时候,nginx能够探测到,会自动的进行故障转移,将请求自动迁移到其他的web-server,整个过程由nginx自动完成,对调用方是透明的。
3、虽然我们的服务应用,没有怎么用到了缓存,但还是想补充一个小章节说一下,【服务层】到【缓存层】的高可用
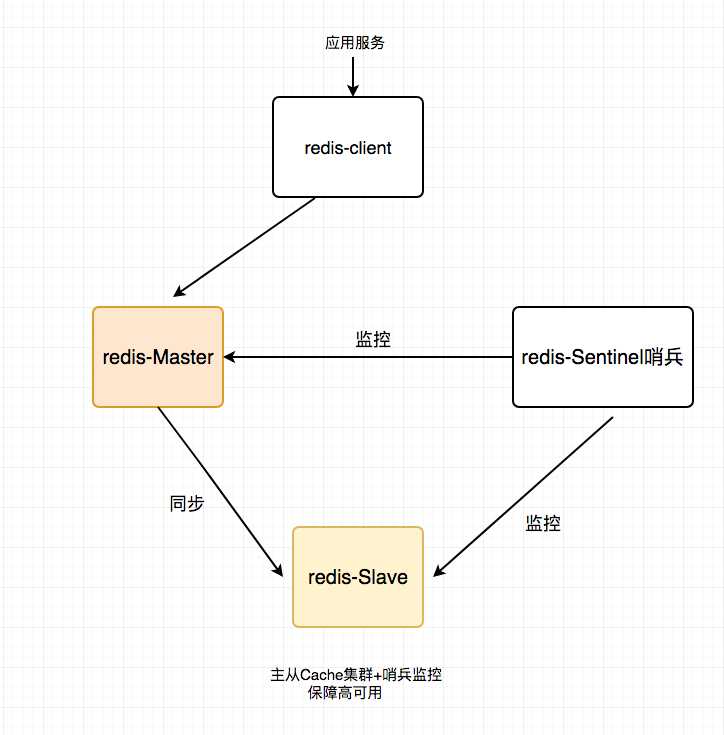
缓存层的数据集群有几种方式:第一种是利用客户端的封装,service对cache进行双读或者双写,也可以通过主从同步的缓存来解决缓存层的高可用问题。
以redis为例,redis天然支持主从同步,redis官方也有sentinel哨兵机制,来做redis的存活性检测。
【正常图】
【reids-Master嗝屁了】
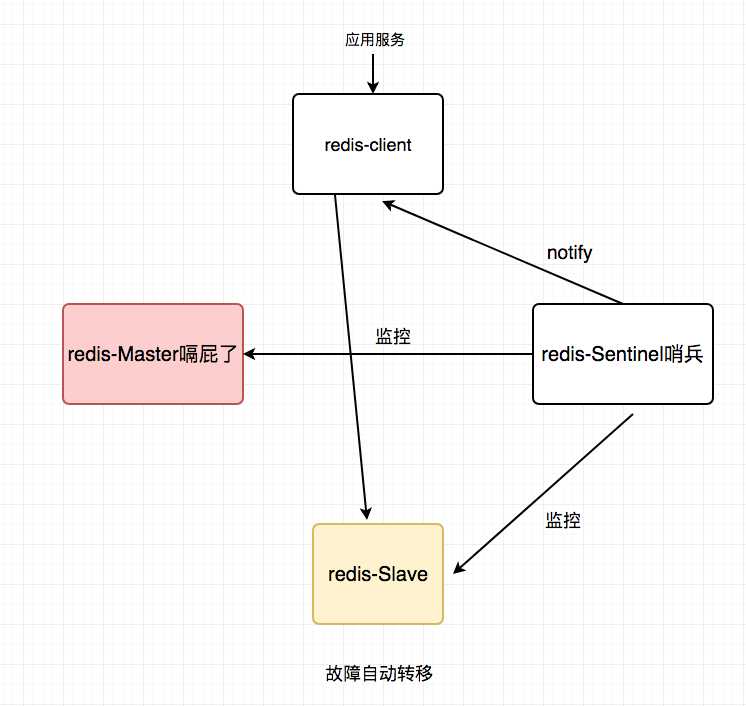
自动故障转移:当redis主挂了的时候,sentinel能够探测到,会通知调用方访问新的redis,整个过程由sentinel和redis集群配合完成,对调用方是透明的。
注:实际小型业务对缓存并不一定有“高可用”要求,更多的对缓存的使用场景,是用来“加速数据访问”:把一部分数据放到缓存里,如果缓存挂了或者缓存没有命中,是可以去后端的数据库中再取数据的。(当然一些大型的流量平台除外)
4、【服务层>数据库层】的高可用
数据库层一般集群化都会采用了“主从同步,读写分离”架构,
以mysql为例,可以设置两个mysql双主同步,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
【正常图】
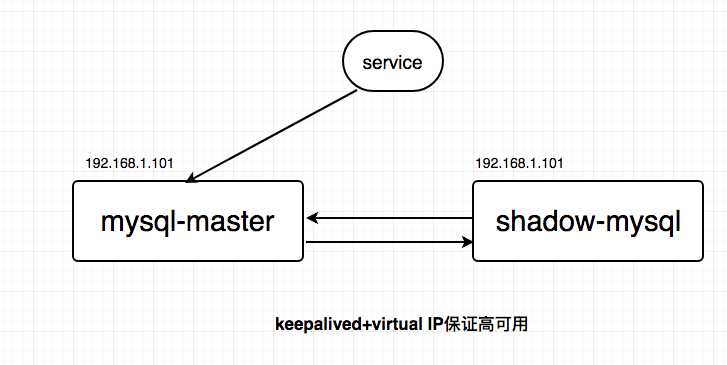
【其中一台数据库嗝屁了】
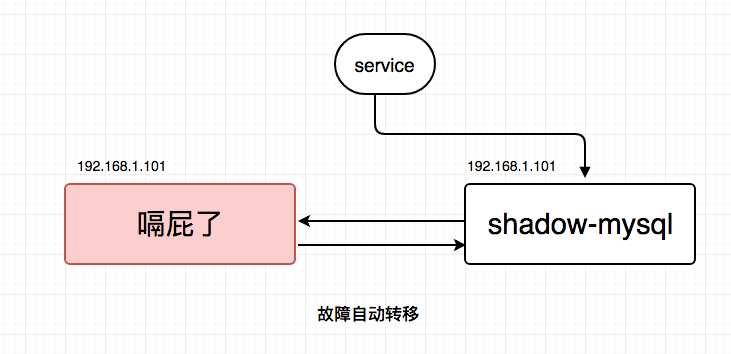
自动故障转移:当其中一个数据库挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-mysql,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
5、再来看看应用服务器集群的Session管理,在集群环境下,Session管理的几种常见手段:
-
Session复制:集群中的几台服务器之间同步Session对象,任何一台服务器宕机都不会导致Session对象的丢失,服务器也只需要从本机获取即可
-
Session绑定:利用负载均衡的源地址Hash算法,总是将源于同一IP地址的请求分发到同一台服务器上。即Session绑定在某台特定服务器上,保证Session总能在这台服务器上获取。(这种方案又叫做会话粘滞)
-
Cookie记录Session:利用浏览器支持的Cookie记录Session。(所以需要保证服务集群间的域名一致来保证session id一致)
注:显然session复制和绑定不符合高可用的需求。因为一旦某台服务器宕机,那么该机器上得Session也就不复存在了,用户请求切换到其他机器后因为没有Session而无法完成业务处理。
》》未完待续《《
另外,打一个小广告,4月份与testerhome合作办了一个测试开发线下培训,我负责的课题持续集成建设与Docker容器化应用相关,目前课件对外特价优惠,感兴趣的同学可以私聊找我哦~
以上是关于实现服务高可用奇淫技巧的主要内容,如果未能解决你的问题,请参考以下文章