前端计算机网络基础
Posted eret9616
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端计算机网络基础相关的知识,希望对你有一定的参考价值。
整理这篇文章需要30分钟:
一站到底 ---前端基础之网络
必会:
- http报文都有哪些内容?
- HTTP协议头含有哪些重要的部分,HTTP状态码?
- HTTP状态码状态码都有哪些?
- 什么是强缓存?什么是弱缓存?
- 浏览器的现缓存机制是什么?如何设置HTTP缓存?
- 你知道有哪些HTTP方法?POST 和 PUT 有什么区别?
- 如何对数据进行压缩(ZLIB),Gzip? 压缩的范围是什么,请求头会压缩吗?
- 跨域,为什么JS会对跨域做出限制?如何允许跨域?
基础:
- 影响网速的原因有哪些?网络丢包的主要原因是什么?
- 网络体系结构的五层参考模型都是什么?它们之间的关系是什么?
- 我们常听到报文、段(分组)、数据报、帧、和数据包,它们有什么关系?
- Ajax能发送http请求,它和http有什么样的关系?
- HTTP1.0 到 http1.1 解决了什么问题?
- http2有什么特性?
- http1.1为什么会有队首阻塞?
- SSL与TLS关系?HTTPS协议如何实现?
补课与拓展:(慢慢更新)
- 常用的传输层协议有哪些?TCP和UDP分别有什么特点?
- 解释一下TCP的三次握手和四次挥手?
- 为什么说TCP可能是网络通信的瓶颈?如何解决TCP队首阻塞?
- 谷歌新出QUIC为什么要基于UDP?
- QUIC有哪些新特性,解决了什么问题?
必会是和前端工作中联系最紧密的http协议相关的内容。但是如果没有网络基础,就好像空中楼阁。无法建立起知识体系。所以本文会把必会和基础放到一起,也就是本文的1-5章内容。
补课与扩展:而深入学习下一代QUIC就必须了解TCP和UDP的具体工作原理。所以这里会给大家偷偷补课。一些常用的拓展内容也会放到后边几章。
本文会用node做代码演示,相关代码在github上。如果node基础不好的同学,我把本章所有的代码整理成了一篇node的学习文档。《node.js的小美好》 。每一小节会有一些习题,用来巩固复习,我慢慢加。
1 网络基础
我们从第一题开始,当浏览器访问www.jd.com时,我们都知道浏览器向服务器发送了http请求,会把请求报文发送给服务器。那么我先粗略分析一下这个过程。
1.1 分组传递
浏览器会基于http协议产生一个http报文(消息),然后会把这个报文拆分成不同的分组(包)。发送到路由上。路由先进行缓存,然后在根据路由表转发给下一个路由,直到到达服务器。
客户端 ---> 路由--->路由.......----> 路由--->服务器
我们为什么不直接把消息发送给服务器,为什么一定要分包呢?
首先,路由是先缓存再转发,如果把整个报文直接发给服务器,那么对路由内存要求会非常高。另外还有一个重要的概念就是网络的带宽,也是在链路上的传输速率,它是由单位时间内可以传输的数据总量决定的。而不是我们物理距离,举个例子。
(1)基础题 (来自《阿里技术之瞳》)
使用一辆卡车运输n块装满数据的1TB硬盘,以80km/h速度行驶1000km将数据运送到目的地,
卡车至少运送多少块硬盘才能使传输速率超过1000Gbit/s?
答案:5625
解析:这个问题可以简化成两种方案在相同时间内两种方案要传输相同的数据量。
卡车的时间为: 1000km ÷ 80Km = 12.5h
在相同时间内网络传输的数据量为: 12.5h * 3600s/h * 1000Gbit/s ÷ 8b/B = 562000GB.
那么卡车需要运输相同的运算量,562000GB ÷ 1000GB = 5625块。
总结:带宽:在链路上的传输速率(bit/sec 即 bps)
bit(位) // 1 Byte = 8 bit
拓展:那么我们现在分析一下交付时间
现在有一个5Mbits的报文,在宽带是1Mbps,从客户端C1 发送到 服务器h2,经过路由器A,B。忽略其他影响。
C1---> A ----> B ---- h2
一次报文交换交付时间:
C1---> A : 5Mbits / 1Mbps = 5s
A ---> B : 5Mbits / 1Mbps = 5s
B --->h2 : 5Mbits / 1Mbps = 5s
共15s
如果分成5000组 , 那么每个包是1bits。
H1---> A : 1bits / 1Mbps = 1ms
当第1个到达时A时需要1ms,第2个已经出发
当第2个已经到A时,第1个已经到达h2服务器
当第5000个到达A时,第4999个到底B,其余都到达。这时候用时5s
当第5000个到达h2时,就用时,5秒零2毫秒。
最后总结一下:
- 报文:M bits
- 链路宽带:R bps
- 路由器数:n
- 分组长度:L bits
- 一次报文交换交付时间 : T = n(M / R)
- 分组交换报文交付时间:T = M / R + nL/R
所以可以看出分组交换比一次报文交互性能要好。而上面所用的时间就叫作传输延迟
传输延迟是影响网速的最主要原因,那么还有一些影响网速的原因我们来看看:
- 排队延时:比如当第1个到包达时A时,如果它前面已经有一些其他客户端的包到达,那么它就许多排队等待。排队所用的时间就是排队延时。
- 结点处理延迟:排队到了以后,结点A会对包进行一些处理,这个处理时间叫结点处理延迟,通常是毫秒级的影响非常小。
- 传播延迟: A出发后,从A到B在链路上传播还要经过一定物理距离,但传输的速度非常快,通常是0.7倍的光速,所用的时间叫传播延迟。
- 丢包: 如果很多客户端同时向A结点发送数据包,A的缓存满了以后,对接下来的数据包,会丢弃。而这正是丢包的主要原因。
问题:现在我们粗略了解了这个过程,那么具体都经历那些过程呢?
1.2 网络体系结构
我们先看来看OSI解释的七成参考模型。
- 分层:我们根据不同的功能把网络模型分层。
- 协议:不同层之间规定了不同协议,每个层遵循每个层的网络协议完成完成功能。
- 接口:层与层之间会通过接口去进行交互。
所以这也符合我们函数的模块化,低层函数定义好接口API,你按照函数的接口文档去调用依赖的函数,然后就等着让它去处理。在实际的开发中,我们就是这么去实现的。
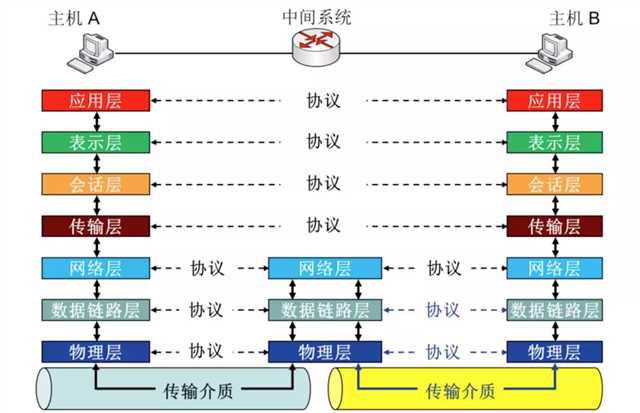
每一层通过本层的协议,增加控制信息,构造协议数据单元PUD。
应用层:
- 浏览器根据http协议,产生报文头和主体
- 对并报文进行编码,加密,压缩。
- 将数据封装好后,交给下一层,我们将这一层的PUD叫 报文(message)
传输层:
- 在浏览器端会将报文分组,在服务器端会将报文重组。
- 在每个分组的头,会加上自己协议信息。
- 这些协议信息主要功能是SAP寻址,连接控制,流量控制,差错控制
- 将数据封装好后,交给下一层,我们将这一层的PUD叫 段(segment)
网络层:
- 网络层在拿个每个段后,会根据IP协议,加上自己协议信息
- 这些协议信息主要功能是:逻辑寻址(IP地址)路由转发。
- 将数据封装好后,交给下一层,我们将这一层的PUD叫 数据报(datagram)
链路层:
- 网络层在拿个每个段后,会根据IP协议,加上自己协议信息
- 这些协议信息主要功能是:物理寻址(MAC地址),流量控制,差错控制,接入控制。
- 将数据封装好后,交给下一层,我们将这一层的PUD叫 帧(frame)
物理层:
- 物理层在拿个帧后,会把它转化成 比特(bit),就是位,二进制编码(一堆100111)
- 然后将这些二进制,根据自己物理特性去表示,比如电信号啥的。
- 然后就把它交给物理介质去传输啦
所以现在我们知道了,每发送一个http请求,是针对应用层的请求和响应。应用层虽然来回只有一次。但它下面传输层,要把整个报文,分成许多分组,再交给下一层,著名的TCP三次链接就是指的传输层的。所以应用层的一次请求和响应,再链路是可能要走许多次。每个包肯定是肯定拥有每个层的协议,不可能只有上层没有下层。而我们常说的数据包,就应该是一个段(分组)经过处理成,最后变成比特在链路上传输。
你会发现我们并没有讲表示层和会话层?因为
应用层 和 传输层 我们后边都会详细讲。这里我们再讲一下 网络层,链路层,物理层。
1.3 链路层与物理层
上面我们知道,物理层会把比特在物理介质上传输。那么主机可能和多台电脑相连,那么二进制码怎么会知道 这是发个那台电脑,走那条网线呢?
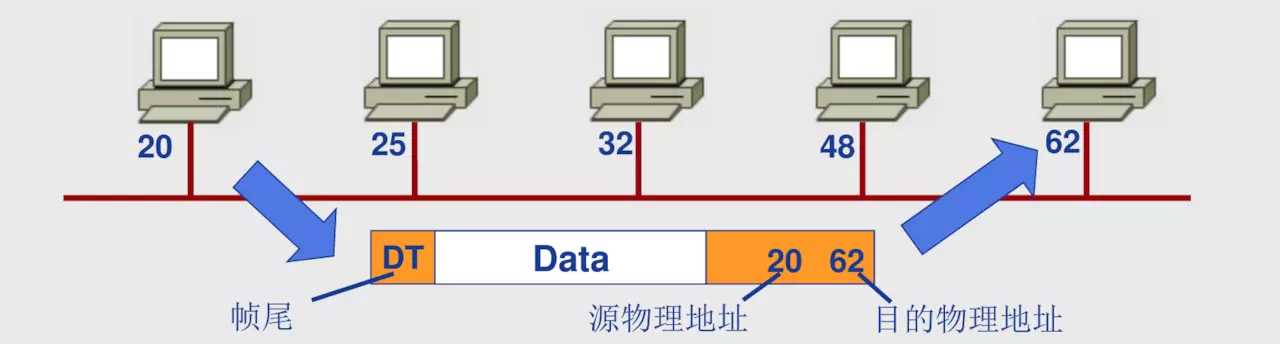
我们知道在链路层会加上要访问主机的物理寻址(MAC地址),所以如果网线连多个电脑,会送到每台电脑,在物理层转化回帧,发现如果不是目标电脑的Mac地址,就不去处理。直到找到目标Mac地址的电脑。这里用到的就是MAC协议。
1.4 网络层与链路层
那么链路层是怎么知道目标机器的Mac地址的呢?
在网络层,我们知道了要访问服务器的IP,首先操作系统会判断是不是本地IP,如果不是,会发送给网关。 操作系统启动的时候,就会被 DHCP 协议配置 IP 地址,以及默认的网关的 IP 地址 192.168.1.1。 操作系统会广播,谁是 192.168.1.1 啊?网关会回答它,我就是,这是Mac地址。这样我们就知道了Mac 地址。这个广播得到Mac 地址的协议就是ARP协议。
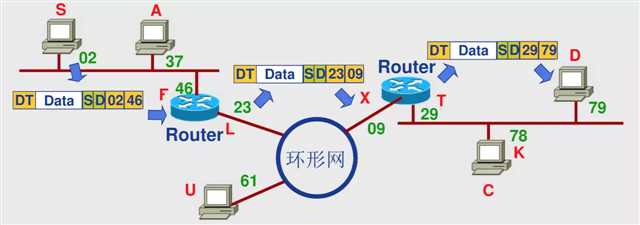
网关往往是一个路由器,知道到某个 IP 地址应该怎么走,这个叫作路由表。这样它再从帧中取出数据报,看到了你想去的IP,它就会告诉你那你应该走那条路,并去找哪个路由。然后在链路层封装的帧中写入那个路由的Mac地址。
路由是怎么知道怎么走的呢,因为路由和路由也会沟通。沟通的协议称为路由协议,常用的有OSPF和BGP。
(测试题1)不定选项 七层网络协议(来自京东2018秋招笔试题)
用浏览器访问www.jd.com时,可能使用到的协议有?
A MAC
B HTTP
C SMTP
D ARP
E RTSP
答案:A B D
解析:所以在第一题中 HTTP是在应用层用的协议 。
MAC和ARP是在数据链路层用和网络层用到的协议。
而同样的应用层协议SMTP是邮件传输协议,RTSP是实时流传输协议。
在访问www.jd.com的时候,我们用不到。2 应用层
2.1 应用层协议
应用层是基于传输层协议之上。常见的传输层协议有TCP,UDP。
- 基于TCP:HTTP(超文本传输协议),FTP(文件传输协议),SMTP(邮件传输协议)
- 基于UDP:DNS(域名系统)和最近兴起的QUIC(谷歌制定低时延的互联网传输层协议)
应用层的功能是完成客户端和服务器消息交换。要想完成信息交换就必须知道资源的位置,那我们是怎么约定资源位置的呢。
2.2 URL:统一资源定位符
语法为:
协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
http://username:[email protected]:80/directory/file.html?query#ref
ftp://username:[email protected]:21/directory/file.html
news://news.newsgroup.com.hk
注意:
如果参数里边有!,%,&,/,?,=,等非西欧字符 需要encode 方法对url的进行预处理
- decode解码成普通字符串
- encode普通字符串编码,编码后的名字非常长叫(application/x-www-form-urlencoded MIME 字符串)
2.3 代码演示
应用层的功能是完成客户端和服务器消息交换。
- 浏览器发送http请求:会输入ip服务和端口
- 服务器监听端口号,在收到请求时作出响应的
代码演示1 node创建TCP服务器
这时我们会过头来看,浏览器左下角,是不是一直在显示等待响应,是因为我们还没有返回数据啊,那我们给 它返回一些数据。
代码演示1 node创建TCP服务器
这里我们先不用管TCP的细节部分,我们会在传输层部分去讲。
问题:在大致了解了应用层协议后,就让我们去具体学习http协议吧
3 HTTP协议:
这一节的内容,可是前端的看家本领,大家一定要对应着代码自己敲出来,看看效果
- HTTP是超文本传输协议,从www浏览器传输到本地浏览器的 一种传输协议,
- HTTP协议是由从客户机到服务器的请求(Request)和从服务器 到客户机的响应(response)进行约束和规范。
3.1 HTTP报文
HTTP报文:用于HTTP协议交互的信息被称为HTTP报文。
- 请求(Request)端的报文叫请求报文
- 响应(response)端的报文叫响应报文
我们那上一节以响应报文为例,我们之前说要符合http协议的规则,那么http规则是什么呢?
let responseDataTpl = `HTTP/1.1 200 OK
Connection:keep-alive
Date: ${new Date()}
Content-Length: 12
Content-Type: text/plain
Hello world!
`;
- 报文首部和报文主体中间要有空行(CR+LF:回车+换行)
- 报文首部:处理请求和响应提供的信息(上文中设置的各种信息)
- 报文主体:所需要的资源都在(比如返回的文本信息就是Hello world)
报文首部:根据实际用途会分为四种
- 通用首部字段(General):请求报文和响应报文都会使用的字段
- 请求首部字段(Requse Header):请求报文使用的首部
- 响应首部字段(Response Header):响应报文使用的首部
- 实体首部字段(Entity Header):与实体有关信息的字段
所以在chrome的network中,header会显示为:
- General
- Response Headers
- Requse Headers
实体首部字段会写进请求头和响应头 对于get请求后边的参数会显示在Query String Parameters
在上边TCP服务器中,我们发现每次写符合http协议格式的响应报文非常麻烦,为什么我们不封装好呢?对啊,所以下面的案例我们就用了封装好的HTTP模块。
代码演示:用node搭建HTTP服务器
我们在代码中看到‘Content-Type‘,它的作用是规定内容的格式。
问题:现在你把实战中的状态码改成400,发现页面仍然能正常访问。这其实就是你和后端按照标准预定的啊,那么是有什么样子的标准呢?
3.2 HTTP状态码
HTTP状态码:是客户端向服务端发送请求,描述请求的状态。 状态码组成:以3位数字和原因短语组成 比如(200 OK 和 206 Partial Content)
第一位数字代表类别:
- 1XX : 信息性状态码(接收请求正在处理)
- 2XX : 成功状态码(请求正常处理完毕)
- 3XX : 重定向状态码(需要进行附加操作以完成请求)
- 4XX : 客户端错误状态码(服务器无法处理请求)
- 5XX : 服务端错误状态码(服务器处理请求出错)
所以状态码就是前后端通信时对于状态的一种约定,原则上只要遵循状态码类别的定义,即使改变RFC2616定义的状态码,或自行创建都是没问题的。
像上面你非将200成功状态改成400,就好比,你把红灯换成绿灯,老司机们都会乱了套。那现在我们看看老司机们都常用的状态码都有哪些吧。
- 200 OK :请求被正常处理返回 200 OK,这也是我们最常见的啦
- 204 No Content :请求处理成功但是没有资源返回,就是报文中没有报文主体
- 206 Partial Content :客户端进行范围请求,就是请求资源一部分,服务器返回请求这部分(Content-Range)
- 301 Moved Permanently:永久重定向(资源的URL已经更新)
- 302 Found :临时重定向(资源的URI已经临时定位到其他位置了)
- 303 See Other: 对应的资源存在另一URL,资源的URL已经更新,是否按新的去访问
- 304 Not Modified:客户端发附带条件的请求,服务端允许请求访问资源,但没有满足条件
- 307 Temporary Redirect: 也是临时重定向
- 400 Bad Request : 请求报文中存在语法错误
- 401 Unauthorized : 需要有HTTP认证
- 403 Forbidden : 请求访问的资源被服务器拒绝了
- 404 Not Found : 服务器上没有找到资源
- 500 Internal Server Error: 服务器执行请求时出错
- 503 Service Unavailable : 服务器处于超负载,正在进行停机维护
代码演示:用url路径模块,完成了node路由
(测试题3)单选题 http状态码(来自阿里技术之瞳)
chrome DevTools的Network面板中参看静态资源加载情况,当发现静态资源的HTTP状态码
是___时,需要使用强制刷新以便获得最新版的静态资源?
A 204
B 304
C 403
D 501
答案:B
解析:304是资源重定向,客户端发附带条件的请求,服务端允许请求访问资源,但没有满足条件
你是不是还有点蒙呢,别着急httpd的缓存协议里你就会看见它啦。
问题:我们知道了状态码代表的含义,但是它们在什么场景下会出现呢?让我们一个一个去学习吧
3.2 HTTP压缩协议
HTTP压缩协议理解起来很简单,就好像你要给你朋友在QQ上传1个1G文件,需要10分钟,哇网速好快哦。 但是你要是压缩一下,这个文件就变成了300M。再给你朋友传可能就需要3分钟。然后你压缩需要1分钟,他解压需要一分钟。这样你们5分钟就搞定啦。同样的道理。
- http请求头带:Accept-Encoding: gzip, deflate, br
这是浏览器告诉服务器我支持什么样的压缩格式,优先级是什么样的。
- http响应头带:Content-Encoding: gzip
这是服务器告诉浏览器我已经按什么样子的格式压缩了,解压工作你拜托你了
所以在浏览器上我们就需要根据请求头中的Accept-Encoding去判断,浏览器支持什么压缩啊。然后压缩之后再告诉浏览器,我已经给你压缩成什么样子啦。
代码演示:2.5 用gzip对文件进行压缩
3.3 HTTP缓存协议
3.3.1 强缓存
Catche Contrl: :是通用首部字段,就是之前将的发送报文和响应报文都会使用的。可以对文件里引用资源的缓存进行设置
这里举一个简单的例子:
浏览器发访问http://localhost:10080/
- ‘请求报文没带 Cache-Control‘ 客户端说我要访问首页
服务器返回数据
- ‘响应报文带:Cache-Control : max-age = 604800‘ 服务器说给你index.html和加载里面资源,并告诉你这些资源一周之内不要不必确认了
浏览器刷新的网页再次访问http://localhost:10080/时
- 里面的资源就不会再发送请求了,直接从缓存中拿 你会在chrome,network中看到Time是0(from memory catch)
服务器返回数据
- 服务器只返回index.html文件
这时候你强制刷新浏览器(command+shift+R)
- ‘请求报文带 Catche Contrl:no-cache ‘客户端说我不要缓存过的数据,我要源服务器的数据
服务器返回数据
- 服务器返回index.html文件和依赖的资源
这就是强缓存,所谓强是在条件内,你网页依赖的资源都不会发送http请求了。可以直接从网页里面拿。
代码演示:浏览器缓存协议的实现
3.3.2 协商缓存
有两种:
第一种:If-Modified-Since/Last-Modified
服务器会下发一个Last-Modified最后修改时间。然后浏览器会记住这个时间。当浏览器第二次请求时会带上if-modified-since的时间。服务器可以去比较这份文件在if-modified-since的时间后是否修改过。如果没有修改过,那就返回304.
- Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
- If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If- -Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified- Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说 明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包 体,节省浏览),告知浏览器继续使用所保存的cache。
代码演示:浏览器缓存协议的实现
上面那个代码中我们服务器并没有实现去记录文件修改时间,我们只要拿一段时间内去比较。我们知道了使用 if-modified-since,服务器就要每次记录文件的一个修改时间。所以用时间去判断并不是很好。
第二种:Etag/ If-None-Match
服务器Etag会下发一个字符串,然后浏览器在第二次请求时会在if-none-match中带上这个字符串。这时候服务器可以比较两个字符串,如果相同,就让浏览器去缓存中去取。
- Etag:web服务器响应请求时,告诉浏览器当前资源在服务器 的唯一标识(生成规则由服务器决定)
- If-None-Match:当资源过期时(使用Cache-Control标识的max- age),发现资源具有Etage声明,则再次向web服务器请求时带 上头If-None-Match (Etag的值)。web服务器收到请求后发现 有头If-None-Match 则与被请求资源的相应校验串进行比对,决 定返回200或304。
代码演示:浏览器缓存协议的实现
那么现在在学完两种缓存之后,你会问,如果同时都有,那么浏览器是如何判断的呢?
3.3.2 协商缓存
有两种:
第一种:If-Modified-Since/Last-Modified
服务器会下发一个Last-Modified最后修改时间。然后浏览器会记住这个时间。当浏览器第二次请求时会带上if-modified-since的时间。服务器可以去比较这份文件在if-modified-since的时间后是否修改过。如果没有修改过,那就返回304.
- Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
- If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If- -Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified- Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说 明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包 体,节省浏览),告知浏览器继续使用所保存的cache。
代码演示:浏览器缓存协议的实现
上面那个代码中我们服务器并没有实现去记录文件修改时间,我们只要拿一段时间内去比较。我们知道了使用 if-modified-since,服务器就要每次记录文件的一个修改时间。所以用时间去判断并不是很好。
第二种:Etag/ If-None-Match
服务器Etag会下发一个字符串,然后浏览器在第二次请求时会在if-none-match中带上这个字符串。这时候服务器可以比较两个字符串,如果相同,就让浏览器去缓存中去取。
- Etag:web服务器响应请求时,告诉浏览器当前资源在服务器 的唯一标识(生成规则由服务器决定)
- If-None-Match:当资源过期时(使用Cache-Control标识的max- age),发现资源具有Etage声明,则再次向web服务器请求时带 上头If-None-Match (Etag的值)。web服务器收到请求后发现 有头If-None-Match 则与被请求资源的相应校验串进行比对,决 定返回200或304。
代码演示:浏览器缓存协议的实现
那么现在在学完两种缓存之后,你会问,如果同时都有,那么浏览器是如何判断的呢?
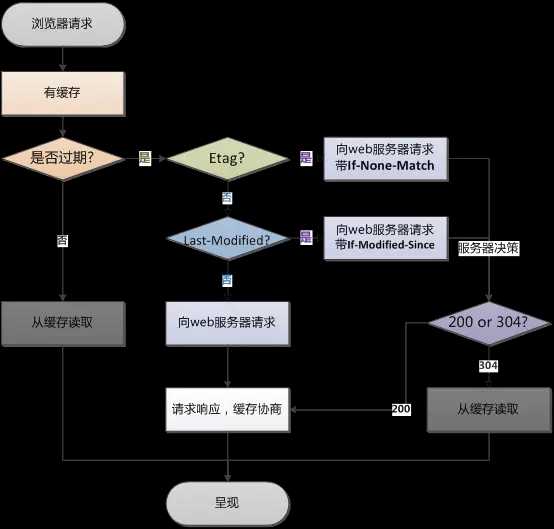
所以可以看出,强缓存优先于协商缓存。
(习题4)不定选项 HTTP缓存 (来自京东2018秋招笔试题)
以下哪些是HTTP请求中浏览器缓存机制会用到的协议头?
A Last-Modified
B Etag
C Referer
D Authorization
答案: A B3.4 HTTP方法
post和get区别最近好像总有争论,到底有什么区别。既然都是应用层的协议,我们不妨回归到本质就看看。我们先来将一下http都有哪些方法,再说post和get的区别。
3.4.1 HTTP方法
- GET:获取资源
- POST:传输实体主体
- PUT:传输文件
- HEAD:获取报文首部
- DELETE:删除文件
- OPTIONS:查询支持方法
- TRACK:追踪路径
- CONNECT:要求用隧道协议连接代理
3.4.2 GET 与 POST区别
协议不久是规定应用层双方的行为和约定吗?那么我们就分别从浏览器和服务器去看看。
浏览器:
- GET是请求数据,使用URL或Cookie传参。POST是传输实体主体所以会把参数放到报文体中
- GET数据放到URL中,浏览器对URL大小有限制,所以数据大小进行限制。POST是传输实体主体,所以大小没有限制
- GET数据放到URL中,所以安全性肯定不高啊,所以不能用来传递敏感信息。POST相对安全
- GET是请求数据所以URL地址可以后退,而POST发送数据不会(chrome中post就会后退)。
- GET是请求所以会被浏览器主动cache,而POST是发送数据,所以不会除非手动设置。
服务器:
- get是把参数放到URL中去处理
- 而post是触发了服务器中监听的请求事件,服务器可能会做出处理,影响返回结果
这里如果不是理解,建议先把这小节实战代码看一下:2.6 浏览器缓存协议的实现
看完服务具体是如何响应的,现在你对下面这句话是不是理解了呢?
“GET和POST最大的区别主要是GET请求是幂等性的,POST请求不是。幂等性是指一次和多次请求某一个资源应该具有同样的副作用。简单来说意味着对同一URL的多个请求应该返回同样的结果。”
答了这么多,不知道你发现没有。浏览器的所有行为都是根据这两个动作做出的相关反应啊。 那么什么时候使用get,什么时候使用post?
根据协议使用啊,不都给你规定好了吗?请求数据的时候用get,传输实体主体的时候用post。
问题:哈哈,学到这,你是不是渐渐明白,并找到一直学不好网络的原因了,都怪浏览器太智能!对,现代浏览器已经非常智能了,所以很多时候,即使的代码质量不高,它也能给你有很好的优化。但是我们毕竟还是要做一名合格的前端工程师,那么下一节就让我们走进浏览器吧
4 浏览器与协议
4.1 XHR 与 AJAX
对于前端工程师来说,AJAX再熟悉不过了,我们知道它是用来发送http请求的。那么它到底与http什么关系?那我们先来手写一个AJAX。
-
AJAX全称是Asynchronous javascript and XML(异步js和XML)。异步js,我们比较容易理解。那么什么是XHR呢。
-
XHR全称是XMLHttpRequest,就是XML的http的请求。其实这是一个浏览器层面的API。通俗点讲就是浏览器给你封装好了的http功能函数。
在之前的课程,我们发送的http请求都是浏览器自己主动发送的。如果,浏览器没有开放这么一个功能。你就当然没有能力主动向服务器获取数据。所以就完不成交互。这就是为什么在AJAX 之前要通过刷新页面来解决。
那么我们如何理解XHR是浏览器层面的API?
-
我们在node服务端的时候知道,我们经常需要需要操作请求头中的数据,比如根据请求头中的压缩机制做出相应的处理。但我们在前端用ajax得到数据的时候。并不用考虑压缩啊,这就是因为XHR是一个浏览器层面的API。它向我们隐藏了大量的底层处理,比如压缩,缓存。换句话说,浏览器也没有开放给你做这些事能力。
-
总结一下,其实很好理解,我们的web页面是跑在浏览器上的,虽然浏览器是智能的,但也是通用的,不是为我们定制的。这也正是webapp不如原生app的体验流畅的原因啊。原声app可以理解为(浏览器+页面)。而webapp是在浏览器上写内容。
但是浏览器单单发送http请求的是不能满足我们日常开发需求的。为了完成跟多的功能,我们有长轮询,浏览器也提供的了websocket的API。这写具体涉及到业务的场景的功能。有机会单写一篇吧。
问题:我们知道了浏览器给我们带来很多的限制,那么具体业务有哪些影响呢?
5 http发展
5.1 HTTP1.0 到http1.1
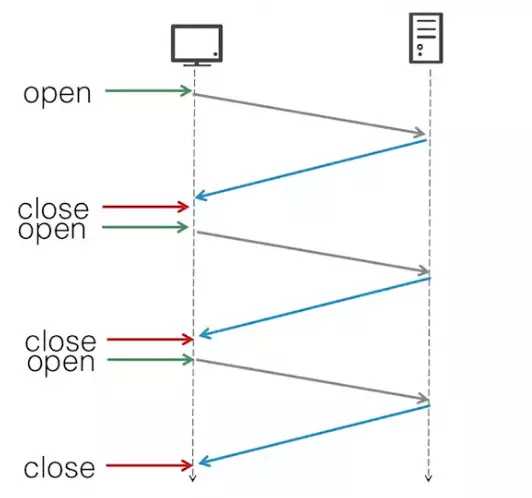
- HTTP1.0的时候,每次发送一个http请求就要建立一次TCP连接,然后再断开
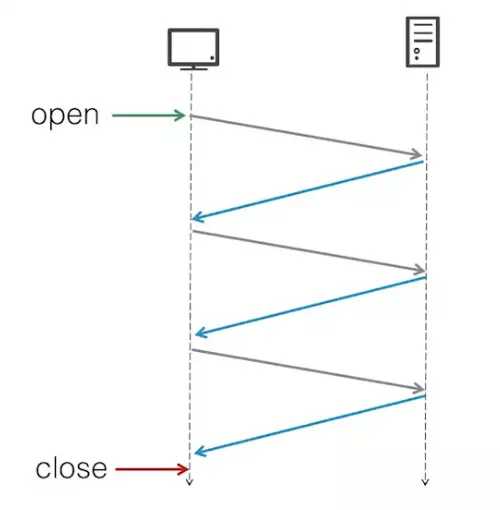
- http1.1的时候,引入了Connection:keep-alive的机制,连接后不断开可以继续发送请求
- 但每次请求都是第一个回来,第二个再出发。后来浏览器又引入了 pipelining的管道化连接。
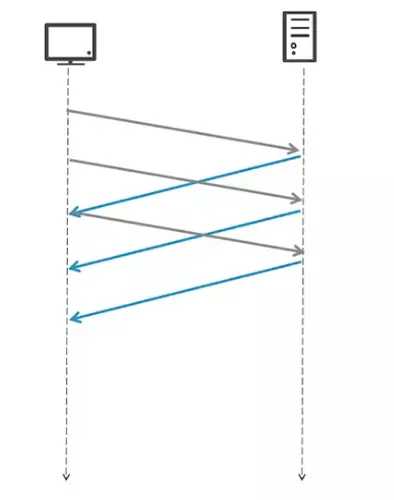
- 在一个TCP连接内,多个HTTP请求可以并行,下一个HTTP请求在上一个HTTP请求的应答完成之前就发起 这个不需要你去设置,引入了Connection:keep-alive,浏览器自动会这么处理。但这又有一个问题,由于HTTP1.1服务端返回响应数据的顺序必须跟客户端请求时的顺序一致,这样也就是要求先进先出。所以很容易造成队首阻塞。就是你第一个请求不返回,后面都得在那等着。
所以这节的重点就是http2就解决了队首阻塞的问题。但http2是基于https的,那就让我们先学习https吧
5.2 HTTPS
HTTPS是针对HTTP安全性不足,做的改进,我们先看看HTTP安全性都有哪些不足
- 通信就是明文
- 没有验证通信方身份
- 无法证明报文完整性
** 所以 HTTS = HTTP + 加密 + 认证 + 完整性保护 **
那么现在我们先看看如何加密解密的吧?
-
比如我有一份数据要给你,我只需要把它加密了,你在解密这样不就安全了。
-
所以我有一个私钥用来加密,给别人解密的是公钥
-
但是这个时候,我们又不能保证别人拿到的公钥就是我的公钥。万一数据没有变,但是公钥被劫持,解密出来的内容就也不是我想发给对方的啦
-
所以我把公钥交给第三方CA认证一下,第三方把公钥变成了证书
-
这样浏览器再拿到我发给它的证书的时候,他去和第三方CA问一下,这是不是他的证书啊。
-
第三方说是,这样我们就安全了。
-
同样浏览器也会以同样的私钥和证书的方式对传给服务器的数据进行加密解密。在第三方认证的时候,我们会详细登记自己的信息。这样我们彼此也就完成了身份认证。
-
最后,这个加密算法还用摘要功能来保证数据的完整性
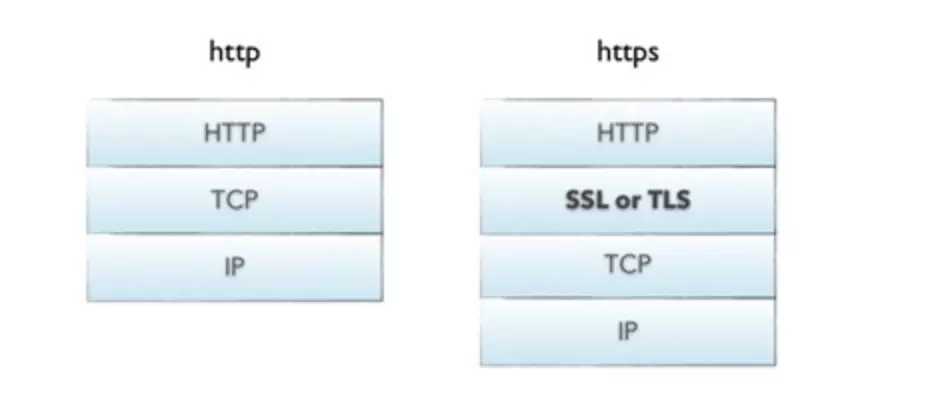
现在我们知道了就是通过一个私钥和证书对数据进行进行加解密。所以HTTPS协议只是HTTP通信接口部分用SSL协议代替而已。而刚才我们讲的这个过程就是SSL协议的内容。它是由网景公司发明,后来转交给IETF,IETF在SSL基础上制定的TLS(改个名字)。
代码演示:3.1 https的node服务器的搭建
5.2 HTTP2.0
现在终于来到我们http2啦。还记得我们说的http1.1的对手阻塞嘛。对http2就解决了这个问题。
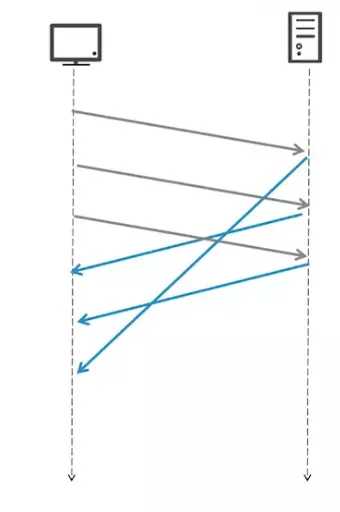
- (1)多路复用,并不在遵循先进先出。
那么现在有一个问题,http2中,既然没有先进先出,那么重要的文件加载的慢,那不就尴尬啦。
- (2)http2定义了请求优先级
我们可以让一些重要的请求优先加载。浏览器也智能的根据http2定义出的优先级规则去显示页面。
- (3)头部压缩
我们知道我们在用Gzip方式给报文体进行压缩。http2给报文头也进行了压缩。你可别小看了报文头,一般网页的报文头能占到报文的40%。 而压缩后能减少60%左右。
- (4)性能上新增了二进制分帧层。也得到了大大的提升。分针层对应的就是http报文。所以http/1.1是一个文本协议,而 http2 是一个彻彻底底的二进制协议。
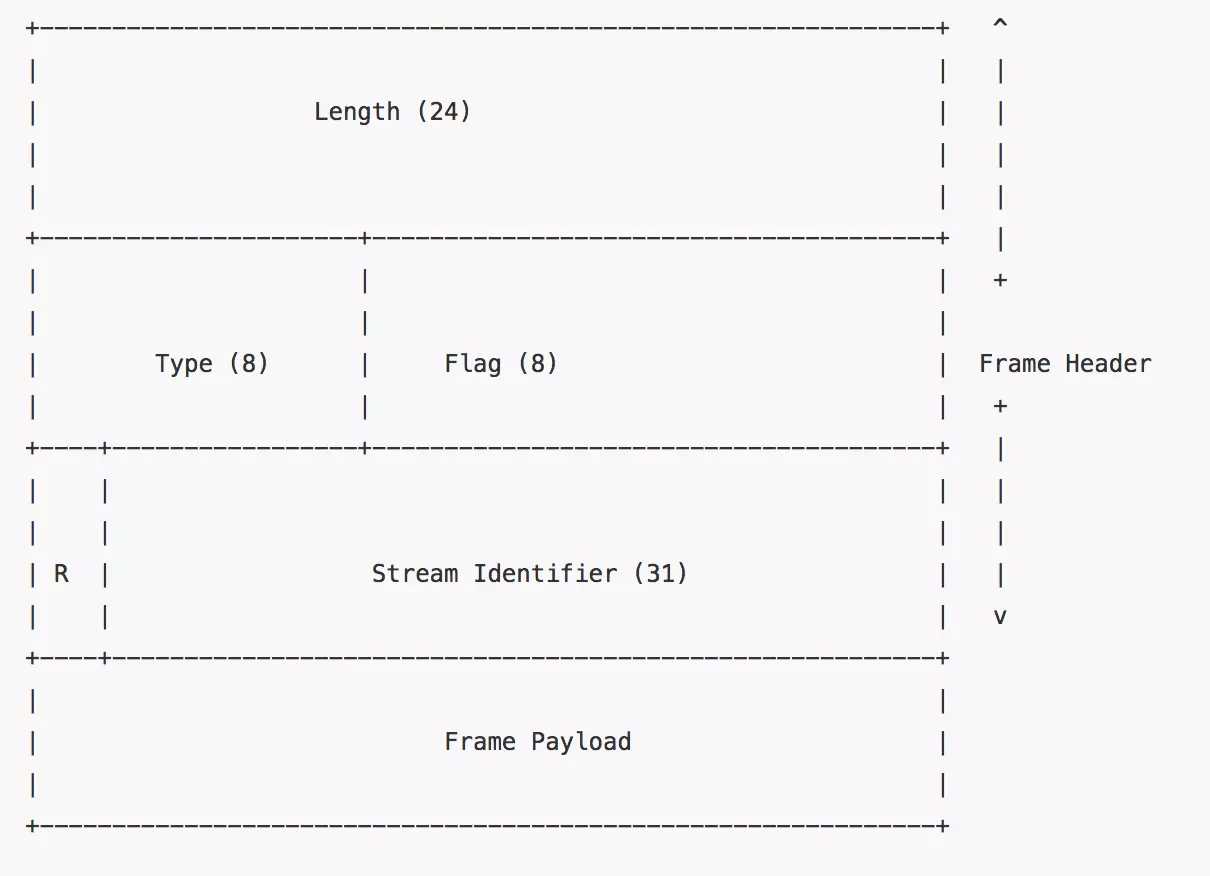
接下来就让我们动手去实践一下吧。
最后,写的好累。。。觉得这一篇写不完。后边写的太糙了。我慢慢改改。拓展有空在写吧。
以上是关于前端计算机网络基础的主要内容,如果未能解决你的问题,请参考以下文章