爬取IT之家新闻
Posted wanglinjie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取IT之家新闻相关的知识,希望对你有一定的参考价值。
爬取站点 https://it.ithome.com/ityejie/ ,进入详情页提取内容。

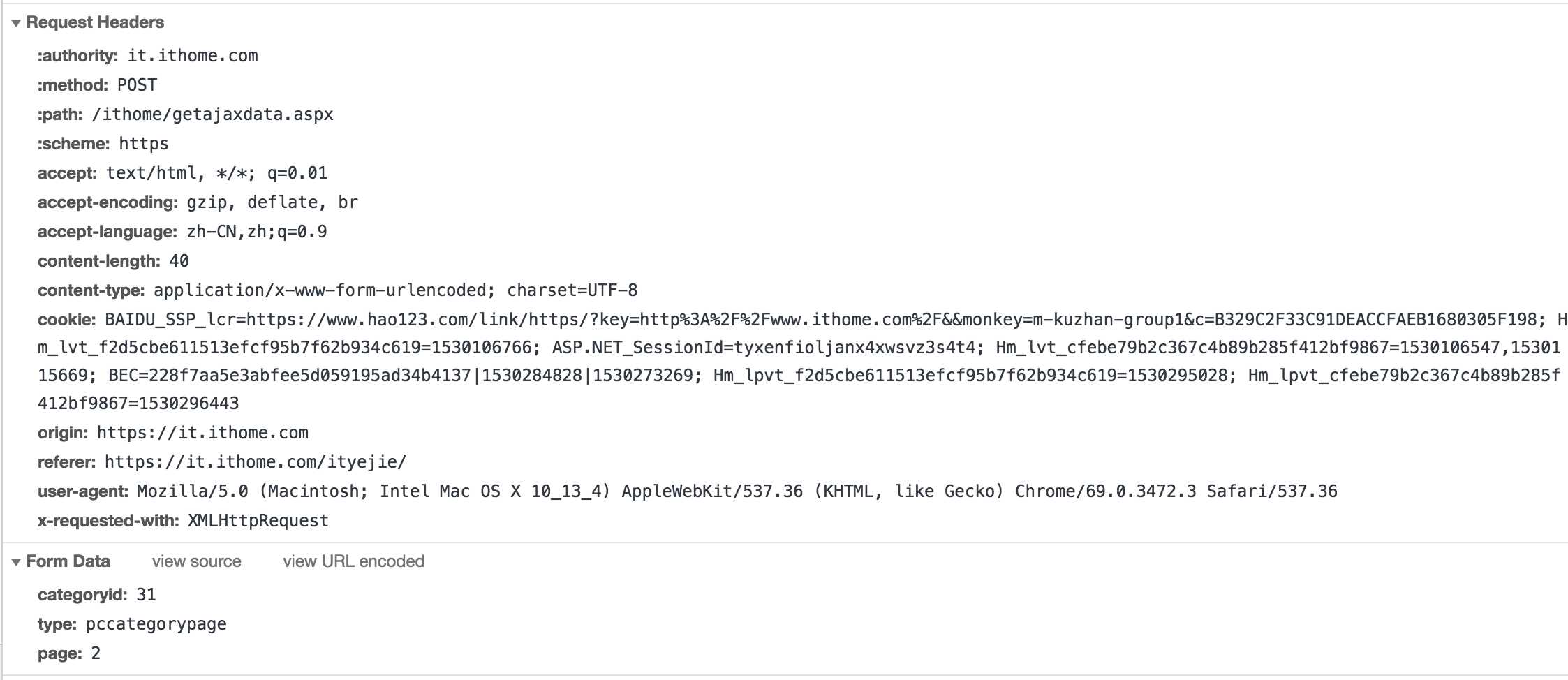
1 import requests 2 import json 3 from lxml import etree 4 5 6 url = ‘https://it.ithome.com/ithome/getajaxdata.aspx‘ 7 8 headers = { 9 10 11 ‘authority‘: ‘it.ithome.com‘, 12 ‘method‘: ‘POST‘, 13 ‘path‘: ‘/ithome/getajaxdata.aspx‘, 14 ‘scheme‘: ‘https‘, 15 ‘accept‘: ‘text/html, */*; q=0.01‘, 16 ‘accept-encoding‘: ‘gzip, deflate, br‘, 17 ‘accept-language‘: ‘zh-CN,zh;q=0.9‘, 18 ‘content-length‘: ‘40‘, 19 ‘content-type‘: ‘application/x-www-form-urlencoded; charset=UTF-8‘, 20 ‘cookie‘: ‘BAIDU_SSP_lcr=https://www.hao123.com/link/https/?key=http%3A%2F%2Fwww.ithome.com%2F&&monkey=m-kuzhan-group1&c=B329C2F33C91DEACCFAEB1680305F198; Hm_lvt_f2d5cbe611513efcf95b7f62b934c619=1530106766; ASP.NET_SessionId=tyxenfioljanx4xwsvz3s4t4; Hm_lvt_cfebe79b2c367c4b89b285f412bf9867=1530106547,1530115669; BEC=228f7aa5e3abfee5d059195ad34b4137|1530117889|1530109082; Hm_lpvt_f2d5cbe611513efcf95b7f62b934c619=1530273209; Hm_lpvt_cfebe79b2c367c4b89b285f412bf9867=1530273261‘, 21 ‘origin‘: ‘https://it.ithome.com‘, 22 ‘referer‘: ‘https://it.ithome.com/ityejie/‘, 23 ‘user-agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3472.3 Safari/537.36‘, 24 ‘x-requested-with‘: ‘XMLHttpRequest‘ 25 } 26 27 28 max_page = 1000 29 30 def get_page(page): 31 32 formData = { 33 ‘categoryid‘: ‘31‘, 34 ‘type‘: ‘pccategorypage‘, 35 ‘page‘: page, 36 } 37 r = requests.post(url, data=formData, headers=headers) 38 #print(type(r)) 39 html = r.text 40 # 响应返回的是字符串,解析为HTML DOM模式 text = etree.HTML(html) 41 #print(html) 42 text = etree.HTML(html) 43 #print(type(text)) 44 45 #link_list = text.xpath(‘//*[@id="wrapper"]/div[1]/div[1]/ul[1]/li/div/h2/a/@href‘) 46 link_list = text.xpath(‘//h2/a/@href‘) 47 #result = etree.tostring(text) 48 #print(result) 49 #print(link_list) 50 #print(page) 51 print("提取第"+str(page)+"页文章") 52 id=0 53 for link in link_list: 54 id+=1 55 print("解析第"+str(page)+"页第"+str(id)+"篇文章") 56 print("链接为:"+link) 57 loadpage(link) 58 59 60 # 取出每个文章的链接 61 def loadpage(link): 62 63 headers = {‘user-agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3472.3 Safari/537.36‘} 64 65 reseponse = requests.get(link, headers = headers) 66 html = reseponse.text 67 # 解析 68 69 node = etree.HTML(html) 70 71 #text = etree.HTML(html) 72 # 取出每层发送的文章链接集合 73 #result = etree.tostring(text) 74 #print(result.decode(‘utf-8‘)) 75 #print(type(result)) 76 77 items ={} 78 # 取出每个标题,正文等 79 #for node in text: 80 #用循环的话,一个页面会执行两次for,内容会重复。 81 print(node) 82 83 # xpath返回的列表,这个列表就这一个参数,用索引方式取出来,标题 84 title = node.xpath(‘//*[@id="wrapper"]/div[1]/div[2]/h1‘)[0].text 85 # 时间 86 data = node.xpath(‘//*[@id="pubtime_baidu"]‘)[0].text 87 # 取出标签下的内容 88 content = "".join(node.xpath(‘//*[@id="paragraph"]/p/text()‘)).strip() 89 #content = node.xpath(‘//*[@id="paragraph"]/p‘)[1].text 90 # 取出标签里包含的内容,作者 91 author = node.xpath(‘//*[@id="author_baidu"]/strong‘)[0].text 92 # 评论数 93 commentcount = node.xpath(‘//span[@id="commentcount"]‘)[0].text 94 #评论数没有取到 95 96 97 items = { 98 "title" : title, 99 "data" : data, 100 "content" : content, 101 "author" : author, 102 "commentcount" : commentcount 103 } 104 105 print("--正在保存--") 106 with open("ithome.json", "a") as f: 107 #f.write(json.dumps(items, ensure_ascii = False).encode("utf-8") + " ") 108 f.write(json.dumps(items, ensure_ascii = False) + " ") 109 print("--已保存--") 110 111 112 113 if __name__ == "__main__": 114 115 for page in range(1, max_page + 1): 116 get_page(page)
以上是关于爬取IT之家新闻的主要内容,如果未能解决你的问题,请参考以下文章