如何将视频中的语音转成文字
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何将视频中的语音转成文字相关的知识,希望对你有一定的参考价值。
视频里的语音转成文字方法如下:
操作设备:小米11。
设备系统:miui10。
操作软件:剪映1.2.1。
1、首先,打开剪映app,然后选择上强始方的“+”号。

2、其次,添加需要制作的视频,然后选择下面的文本工具。
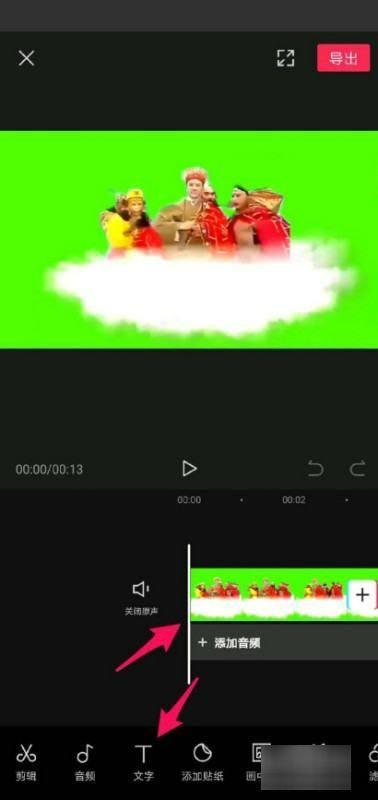
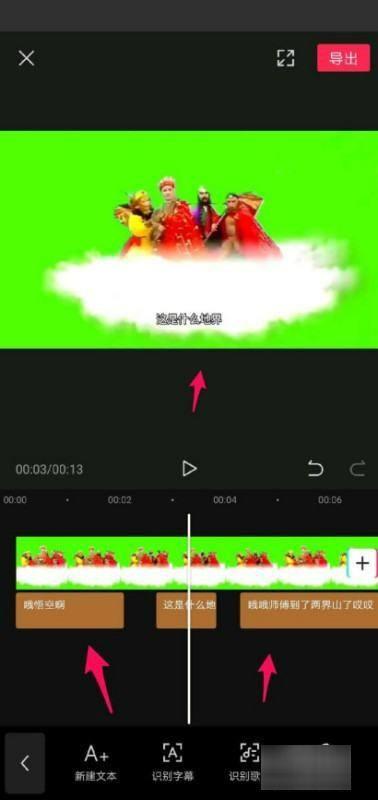
3、然后,在文本中选择字幕识别选项,然后在弹出对话框中选择开始识别。

4、通过这种方式,可以显示视频中的语音识别了。
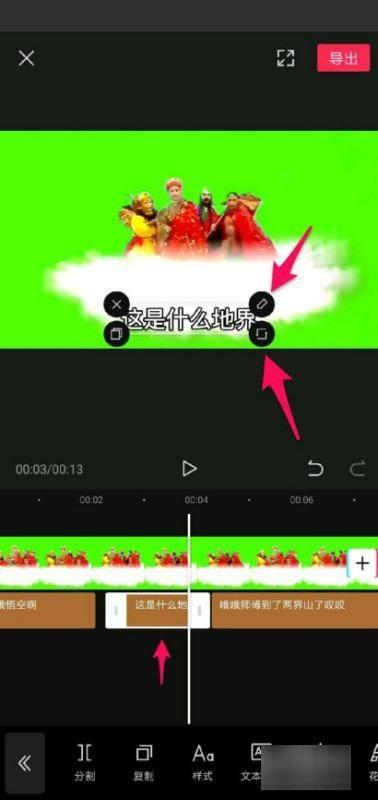
5、最后,如果识别的文本中有错误,则可以单击文本以更改文本。
如何将视频中的语音转成文字?
分享几个将视频中的语音转成文字的方法:
方法一:借助灵听录音转文字网站
1、首先在百度上找到并进入网站,登录后,上传需要处理的视频文件;

2、上传成功后,点击“开始转写”,然后耐心等待;转写完成后,在文件列表里点击“查看结果”,打开可以看到详细的文字内容;
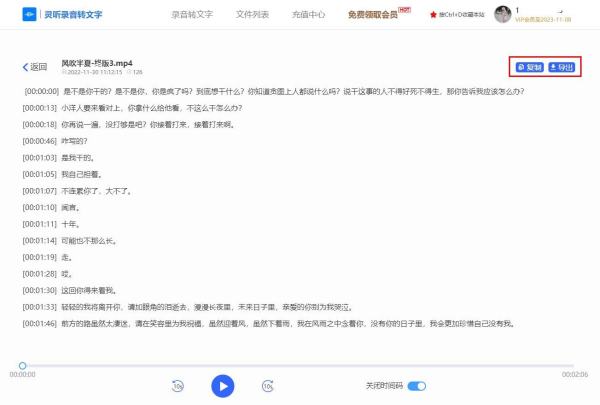
3、最后选择复制或者导出,导出的话,是导出一个压缩文件,解压后是word格式的文档。
方法二:借助剪映
1、打开剪映,将需要处理的视频文件导入进去;

2、然后点击左上方的“文本”,再点击左侧的“智能字幕”,选择“识别字幕”,点击“开始识别”,识别完成后,点击右上方的“导出”,在弹出的面板中只勾选“字幕导出”,把字幕格式选择为“txt”,点击“导出”即可。

用剪映的“智能字幕”功能就可以,步骤如下:
1、启动剪映,把音频放到轨道上;
2、单击“文本”-》“智能字幕”-》“开始识别”
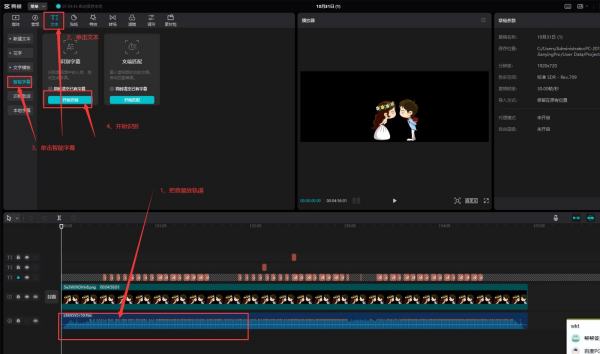
如果觉得有用,请采纳谢谢!
利用百度语音识别接口将语音转换成文字教程
一、说明
如果有一个工具能识别音视中的语音并转换成文字输出,由于可以复制粘贴而不需要逐字逐句地打,那我们进行为音频配字幕工作时将会事半功倍。
其中的关键点是音文转换,音文转换其实在很多地方都可以看到比如qq,百度搜索,讯飞输入法等等,具体到技术而言前述的三个场景其背后的技术都是一样的,都是利用AI进行语音识别。而且腾讯、百度、讯飞当前都开放了自家的语音识别接口免费使用,本文就是利用的百度语音识别接口实现的转换。
其实就配字幕这种工作而言,当前应该可以实现通过写代码自动给音频文件配上字幕,复制粘贴这步都可以省了,当然这不在本文的实现范围。
另外AI识别有一定的错误率,在我们自己使用qq、百度、讯飞时应该都有体会,更何况开放出来的接口一般都不会是公司产品百分百的能力,所以肯定还是要人工介入修正。
二、音文转换程序
2.1 程序说明
官方文档:http://ai.baidu.com/docs#/ASR-API/top
语音识别接口:http://vop.baidu.com/server_api
接口要求:只接受pcm格式音频,请求次数不限但每个音视不能超过60秒
系统环境:Windows-7 X64、Python-3.6.5 X64(miniconda)。minicoda安装可参见“PyCharm+Miniconda3安装配置教程”第二大点,如果直接安装python网上搜搜教程即可。
gihub地址:https://github.com/PrettyUp/BaiduAI。这里将程序和之前写的程序都放在了BaiduAI项目录,只管其中的vtt目录即可。
程序支持:仅支持mp3格式文件,仅支持英语(要支持普通话将post的dev_pid参数修改为1536即可,参见官方文档)
程序流程:获取video目录下的所有mp3文件并逐个进行处理----将当前要处理的mp3文件使用ffmpeg转换成pcm格式----将生成的pcm文件使用speech-vad-demo切割----将切割后的pcm文件逐个进行音文转换
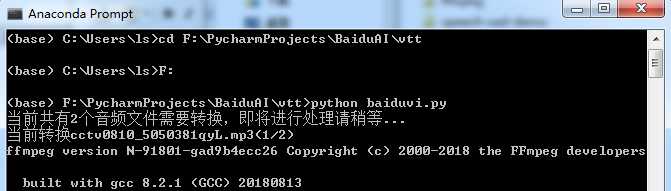
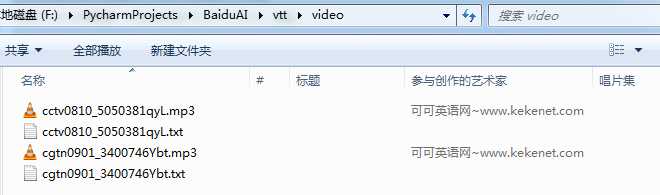
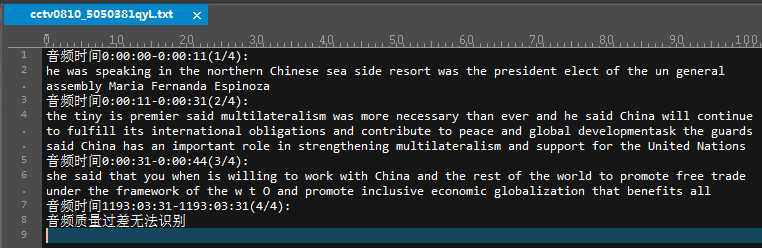
运行操作:安装好系统环境----将压缩包解压到任意目录----将要转换的mp3文件复制到video文件夹下----使用python运行baiduvi.py文件----程序执行完后在video文件夹下会为各mp3文件生成其同名.txt文件其中即是语音转换成的文字。如下所示
2.2 程序代码
程序自己写的只有一个文件,我这里命名为baiduvi.py
import base64 import json import os import time import shutil import requests class BaiduVoiceToTxt(): # 初始化函数 def __init__(self): # 定义要进行切割的pcm文件的位置。speech-vad-demo固定好的,没的选 self.pcm_path = ".\\speech-vad-demo\\pcm\\16k_1.pcm" # 定义pcm文件被切割后,分割成的文件输出到的目录。speech-vad-demo固定好的,没的选 self.output_pcm_path = ".\\speech-vad-demo\\output_pcm\\" # 百度AI接口只接受pcm格式,所以需要转换格式 # 此函数用于将要识别的mp3文件转换成pcm格式,并输出为.speech-vad-demopcm16k_1.pcm def change_file_format(self,filepath): file_name = filepath # 如果.speech-vad-demopcm16k_1.pcm文件已存在,则先将其删除 if os.path.isfile(f"{self.pcm_path}"): os.remove(f"{self.pcm_path}") # 调用系统命令,将文件转换成pcm格式,并输出为.speech-vad-demopcm16k_1.pcm change_file_format_command = f".\\ffmpeg\\bin\\ffmpeg.exe -y -i {file_name} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {self.pcm_path}" os.system(change_file_format_command) # 百度AI接口最长只接受60秒的音视,所以需要切割 # 此函数用于将.speech-vad-demopcm16k_1.pcm切割 def devide_video(self): # 如果切割输出目录.speech-vad-demooutput_pcm已存在,那其中很可能已有文件,先将其清空 # 清空目录的文件是先删除,再创建 if os.path.isdir(f"{self.output_pcm_path}"): shutil.rmtree(f"{self.output_pcm_path}") time.sleep(1) os.mkdir(f"{self.output_pcm_path}") # vad-demo.exe使用相对路径.pcm和.output_pcm,所以先要将当前工作目录切换到.speech-vad-demo下不然vad-demo.exe找不到文件 os.chdir(".\\speech-vad-demo\\") # 直接执行.vad-demo.exe,其默认会将.pcm16k_1.pcm文件切割并输出到.output_pcm目录下 devide_video_command = ".\\vad-demo.exe" os.system(devide_video_command) # 切换回工作目录 os.chdir("..\\") # 此函数用于将.speech-vad-demooutput_pcm下的文件的文件名的时间格式化成0:00:00形式 def format_time(self,seconds): # 一个小时3600秒 hour_seconds = 60*60 # 一分钟60秒 minute_seconds = 60 # 文件名的时间是毫秒需要先转成秒。+500是为了四舍五入,//是整除 seconds = (seconds + 500) // 1000 # 小时 hour = seconds // hour_seconds # 扣除小时后剩余秒数 hour_left_seconds = seconds % hour_seconds # 分钟 minute = hour_left_seconds // minute_seconds # 如果不足10分钟那在其前补0凑成两位数格式 if minute < 10: minute = f"0{minute}" # 扣除分钟后剩余秒数 minute_left_seconds = hour_left_seconds % minute_seconds # 如果秒数不足10秒,一样在其前补0凑足两位数格式 if minute_left_seconds < 10: minute_left_seconds = f"0{minute_left_seconds}" # 格式化成0:00:00形式,并返回 time_format = f"{hour}:{minute}:{minute_left_seconds}" return time_format # 此函数用于申请访问ai接口的access_token def get_access_token(self): # 此变量赋值成自己API Key的值 client_id = ‘f3wT23Otc8jXlDZ4HGtS4jfT‘ # 此变量赋值成自己Secret Key的值 client_secret = ‘YPPjW3E0VGPUOfZwhjNGVn7LTu3hwssj‘ auth_url = ‘https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=‘ + client_id + ‘&client_secret=‘ + client_secret response_at = requests.get(auth_url) # 以json格式读取响应结果 json_result = json.loads(response_at.text) # 获取access_token access_token = json_result[‘access_token‘] return access_token # 此函数用于将.speech-vad-demooutput_pcm下的单个文件由语音转成文件 def transfer_voice_to_txt(self,access_token,filepath): # 百度语音识别接口 url_voice_ident = "http://vop.baidu.com/server_api" # 接口规范,以json格式post数据 headers = { ‘Content-Type‘: ‘application/json‘ } # 打开pcm文件并读取文件内容 pcm_obj = open(filepath,‘rb‘) pcm_content_base64 = base64.b64encode(pcm_obj.read()) pcm_obj.close() # 获取pcm文件大小 pcm_content_len = os.path.getsize(filepath) # 接口规范,则体函义见官方文件,值得注意的是cuid和speech两个参数的写法 post_data = { "format": "pcm", "rate": 16000, "dev_pid": 1737, "channel": 1, "token": access_token, "cuid": "1111111111", "len": pcm_content_len, "speech": pcm_content_base64.decode(), } proxies = { ‘http‘:"127.0.0.1:8080" } # 调用接口,进行音文转换 response = requests.post(url_voice_ident, headers=headers, data=json.dumps(post_data)) # response = requests.post(url_voice_ident,headers=headers,data=json.dumps(post_data),proxies=proxies) return response.text if __name__ == "__main__": # 实例化 baidu_voice_to_txt_obj = BaiduVoiceToTxt() # 自己要进行音文转换的音视存放的文件夹 video_dir = ".\\video\\" all_video_file =[] all_file = os.listdir(video_dir) # 只接受.mp3格式文件。因为其他格式没研究怎么转成pcm才是符合接口要求的 for filename in all_file: if ".mp3" in filename: all_video_file.append(filename) all_video_file.sort() i = 0 video_file_num = len(all_video_file) print(f"当前共有{video_file_num}个音频文件需要转换,即将进行处理请稍等...") # 此层for循环是逐个mp3文件进行处理 for video_file_name in all_video_file: i += 1 print(f"当前转换{video_file_name}({i}/{video_file_num})") # 将音视翻译成的内容输出到同目录下同名.txt文件中 video_file_txt_path = f".\\video\\{video_file_name[:-4]}.txt" # 以覆盖形式打开.txt文件 video_file_txt_obj = open(video_file_txt_path,‘w+‘) filepath = os.path.join(video_dir, video_file_name) # 调用change_file_format将mp3转成pcm格式 baidu_voice_to_txt_obj.change_file_format(filepath) # 将转换成的pcm文件切割成多个小于60秒的pcm文件 baidu_voice_to_txt_obj.devide_video() # 获取token access_token = baidu_voice_to_txt_obj.get_access_token() # 获取.speech-vad-demooutput_pcm目录下的文件列表 file_dir = baidu_voice_to_txt_obj.output_pcm_path all_pcm_file = os.listdir(file_dir) all_pcm_file.sort() j = 0 pcm_file_num = len(all_pcm_file) print(f"当前所转文件{video_file_name}({i}/{video_file_num})被切分成{pcm_file_num}块,即将逐块进行音文转换请稍等...") # 此层for是将.speech-vad-demooutput_pcm目录下的所有文件逐个进行音文转换 for filename in all_pcm_file: j += 1 filepath = os.path.join(file_dir, filename) if (os.path.isfile(filepath)): # 获取文件名上的时间 time_str = filename[10:-6] time_str_dict = time_str.split("-") time_start_str = baidu_voice_to_txt_obj.format_time(int(time_str_dict[0])) time_end_str = baidu_voice_to_txt_obj.format_time(int(time_str_dict[1])) print(f"当前转换{video_file_name}({i}/{video_file_num})-{time_start_str}-{time_end_str}({j}/{pcm_file_num})") response_text = baidu_voice_to_txt_obj.transfer_voice_to_txt(access_token, filepath) # 以json形式读取返回结果 json_result = json.loads(response_text) # 将音文转换结果写入.txt文件 video_file_txt_obj.writelines(f"音频时间{time_start_str}-{time_end_str}({j}/{pcm_file_num}): ") if json_result[‘err_no‘] == 0: print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})转换成功:{json_result[‘result‘][0]}") video_file_txt_obj.writelines(f"{json_result[‘result‘][0]}") elif json_result[‘err_no‘] == 3301: print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})音频质量过差无法识别") video_file_txt_obj.writelines(f"音频质量过差无法识别") else: print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})转换过程遇到其他错误") video_file_txt_obj.writelines(f"转换过程遇到其他错误") video_file_txt_obj.writelines(f" ") video_file_txt_obj.close()
参考:
http://ai.baidu.com/docs#/ASR-API/top
http://ai.baidu.com/forum/topic/show/495449
以上是关于如何将视频中的语音转成文字的主要内容,如果未能解决你的问题,请参考以下文章