(2012, AlexNet) ImageNet Classification with Deep Convolutional Neural Networks
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2012, AlexNet) ImageNet Classification with Deep Convolutional Neural Networks相关的知识,希望对你有一定的参考价值。
参考技术A上一篇文章中的LeNet-5是第一个广为人知的经典CNN网络,但那是20年前提出的CNN网络,最成功的案例是解决了手写数字识别的问题,当时被广泛应用于邮局/银行的手写邮编/支票数字自动识别系统。但直到2012年之前,在这14年间,CNN网络在图像识别领域的地位逐渐被其他分类模型如SVM取代。其中主要的原因有(事后诸葛亮......):
经过十几年的发展,以上制约CNN网络发展的主要限制因素一个个被解决,结果在2012年的ImageNet竞赛中,继LeNet-5之后的第二个经典CNN网络—AlexNet横空出世。以超出第二名10%以上的top-5准确率,勇夺ImageNet2012分类比赛的冠军,从此, 深度学习 重新回到人们的视野,并一发不可收拾。
下面从一些直观的数据比较1998年的LeNet-5和2012年的AlexNet的区别:
AlexNet网络结构如下图所示:
论文中由于使用了2块GPU,将网络结构布置成了上下两部分,看着很不方便,上图是在网上找的简易版本。
下面总结AlexNet的主要特点:
3.1. 使引入Relu激活函数减轻深度网络难以训练的问题
关于CNN网络的激活函数的讨论,SigAI公众号这篇文章总结的挺好:
另外,下面这篇论文对深度网络难以训练的问题进行了分析:
之前的CNN网络,包括前面著名的LeNet-5,都使用tanh/Sigmoid作为激活函数,这类激活函数具有饱和性,在训练深层网络时会造成梯度消失问题,而AlexNet引入了非饱和的Relu激活函数,有效地缓解了梯度消失问题。
3.2. 解决深度网络的过拟合问题
一方面,近几年来,人们越来越意识到构建庞大的数据集的重要性,于是出现了像ImageNet这样超过1500万张标注图片,2200多种类别的数据集,ILSVRC2012中,AlexNet使用了150万张图片的庞大训练集,使得拥有6000万个参数的AlexNet也没出现严重过拟合问题;
另外,AlexNet在训练时使用了数据增强(data augmentation)策略,相当于进一步扩大了训练数据集;
最后,AlexNet在全连接层部分引入了一个dropout层,同样能有效防止模型出现过拟合。
3.3. 计算能力问题
尽管AlexNet的模型复杂度很大,但其利用了英伟达GPU强大的计算能力,在GPU面前,模型复杂度不是问题。
从模型的设计思路来看,其实AlexNet遵循了LeNet-5的思想,即使用交替的卷积层和池化层用于提取图像的高级语义特征,同时降低特征尺寸。然后使用全连接层/MLP作为分类层。
但是,在细节部分,ALexNet引入了很多新的元素,用于解决以上提到的CNN网络遇到的诸多问题,使得CNN网络开始重新散发光芒。
CNN网络:AlexNet
AlexNet论文[imagenet.pdf (toronto.edu)]。AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。在图像分类上准确率远超在其之前的神经卷积网络。
AlexNet的输入要求是固定的分辨率224*224*3,为此在训练前,首先重新缩放图像,使得较短边的长度为224,然后从结果图像的中心裁剪出224*224大小的图片。原始图像经预处理就变为224*224*3。
AlexNet的网络结构如图:
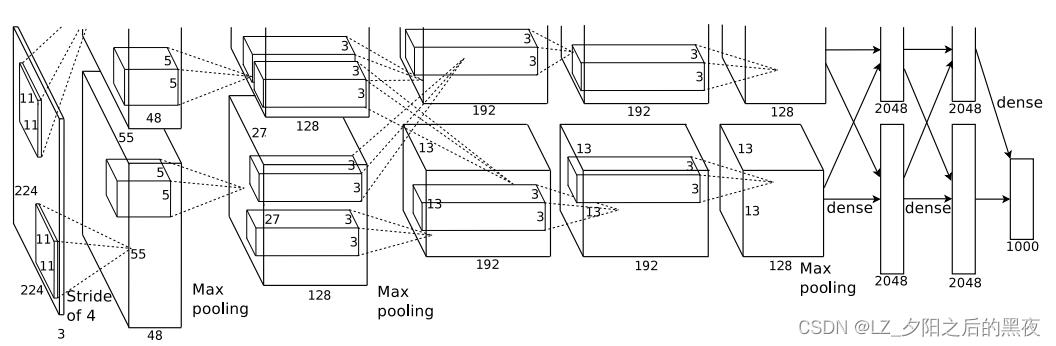
AlexNet由输入层,5个卷积层,3个全连接层组成。网络是分布在2个GPU上的,部分层只跟同一个GPU中的上一层连接。
卷积后的长 = [(输入图像的长-卷积核的尺寸-2*填充圈数)/ 滑动步长 ] + 1
池化后的长 = [(输入图像的长-池化尺寸)/ 滑动步长 ] + 1
第一层卷积池化:论文中的输入图像是224*224尺寸的,但根据卷积核计算输出的尺寸并不是55*55,但如果输入是227*227尺寸的,经过计算得到的是55*55,所以正确的输入尺寸是227*227。使用96个尺寸为11*11*3的卷积核进行卷积计算,分成两份输入到两个GPU中,stride步长为4,输出size为55*55*48。然后将55×55×48的特征图放入ReLU激活函数,生成激活图。激活后的图像进行最大重叠池化,size为3×3,stride步长为2,池化后的特征图size为27×27×48。池化后进行LRN处理。但在2015年 Very Deep Convolutional Networks for Large-Scale Image Recognition.提到LRN基本没什么用。

第二层卷积池化:每组的27*27*48的输入图像各使用128个5*5*48的卷积核,Padding填充为2,步长为1进行卷积操作,输出图像大小为27*27*128。然后将27*27*128的特征图放入ReLU激活函数,生成激活图。激活后的图像进行最大重叠池化,size为3×3,stride步长为2,池化后的特征图size为13*13*128。池化后进行LRN处理。

第三、四、五层卷积:输入图像13*13*128,每组13*13*128的图像使用192个3*3*128的卷积核,步长为1,padding为1,卷积后输出图像为13*13*192。之后再使用192个3*3*192的卷积核,步长为1,padding填充为1,卷积后的输出图像为13*13*192。输入图像13*13*192,每组13*13*192的图像使用128个3*3*192的卷积核,步长为1,padding为1,卷积后输出图像为13*13*128。最后进行最大池化,size3*3,步长为2,池化后的特征图是6*6*128。

第六、七层两个全连接层的节点数都是4096,第八层全连接层有1000个结点。AlexNet在前两层全连接层前使用了dropout,以0.5的概率使得每个隐藏层的神经元输出0,既不参与前向传播,也不参与反向传播。这种方法弱化了神经元之间的依赖性。
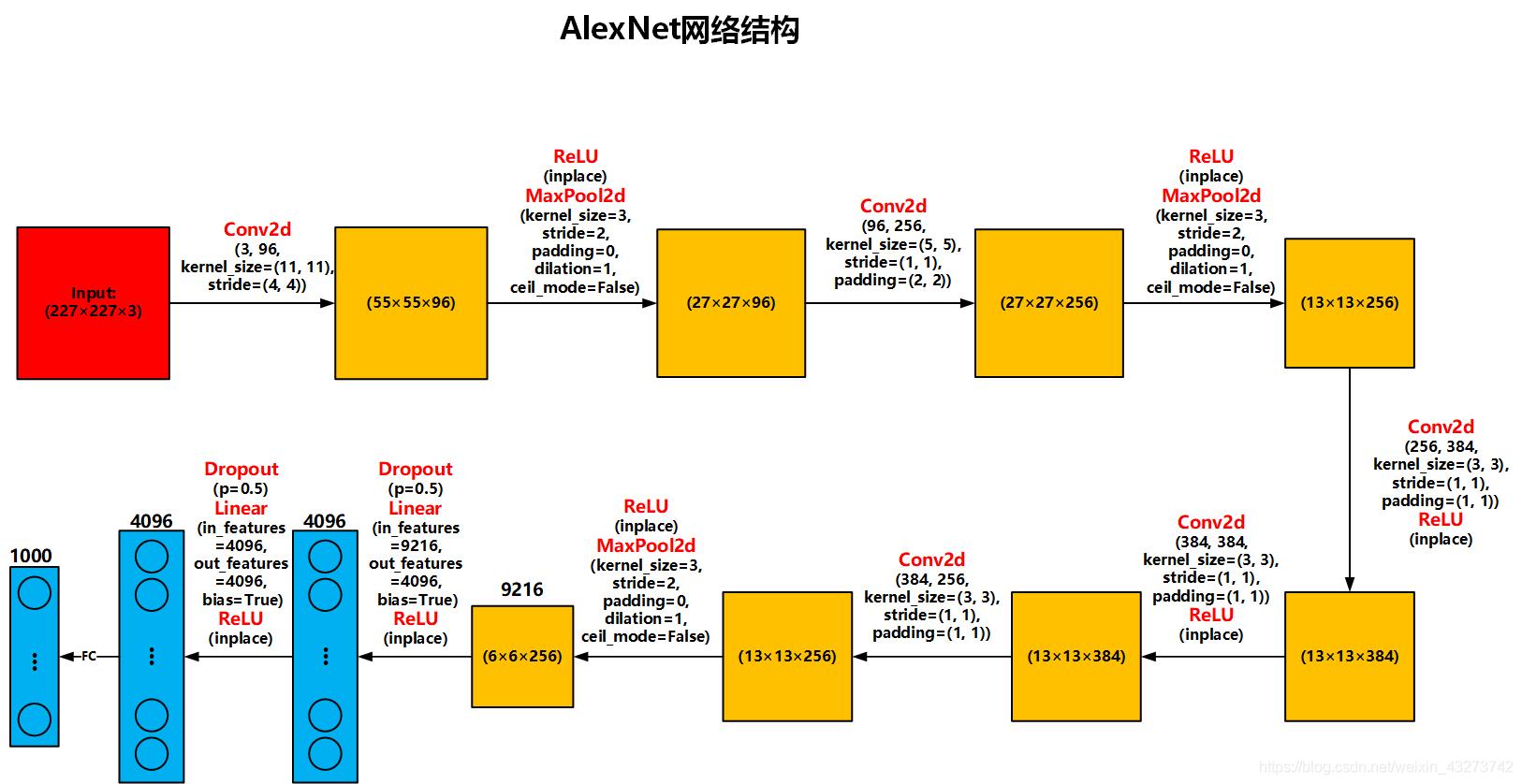
AlexNet的PyTorch实现如下:
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
_log_api_usage_once(self)
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x以上是关于(2012, AlexNet) ImageNet Classification with Deep Convolutional Neural Networks的主要内容,如果未能解决你的问题,请参考以下文章